By likes
By likes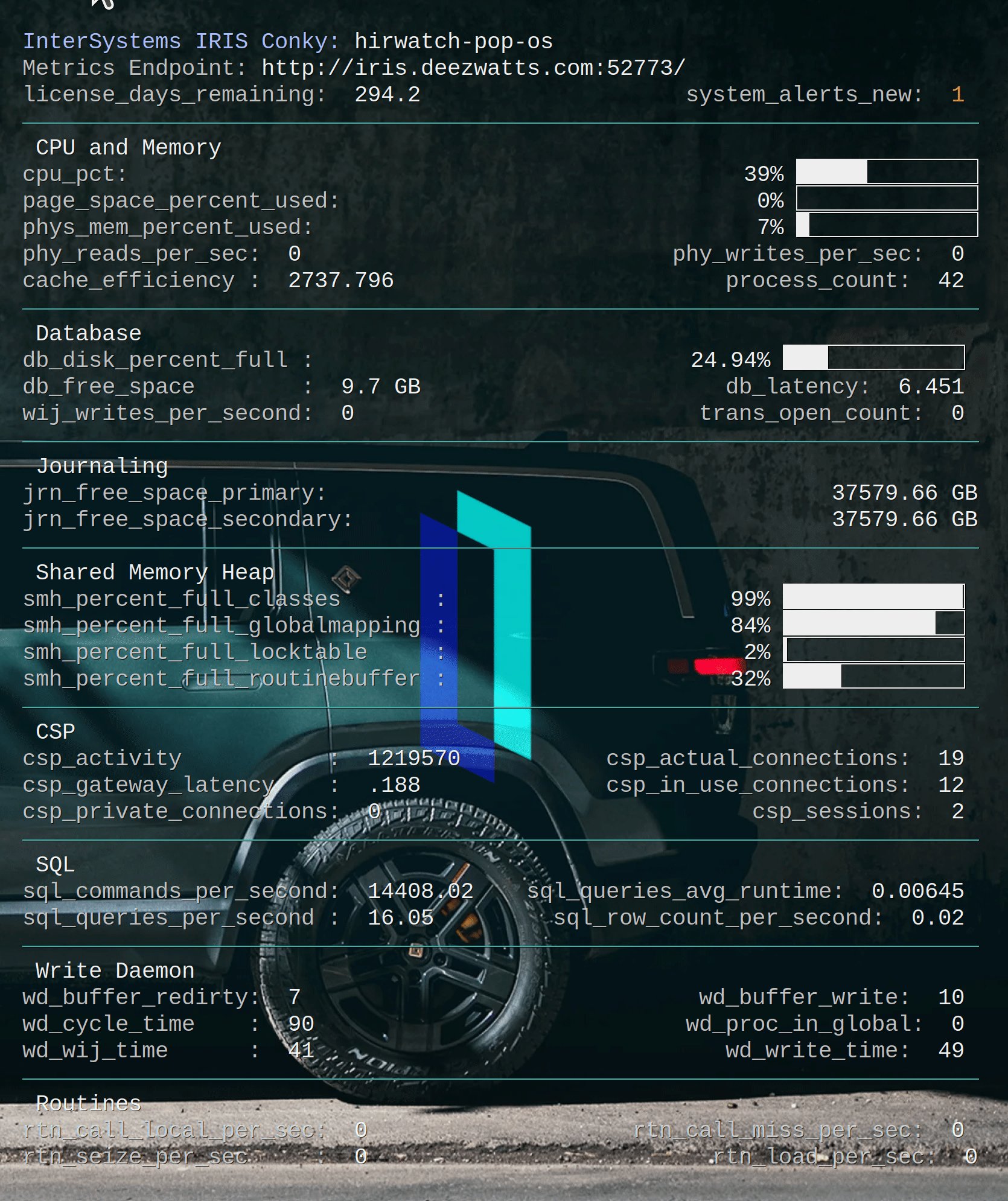
.png)
I attended Cloud Native Security Con in Seattle with full intention of crushing OTEL day, then perusing the subject of security applied to Cloud Native workloads the following days leading up to CTF as a professional excercise. This was happily upended by a new understanding of eBPF, which got my screens, career, workloads, and atitude a much needed upgrade with new approaches to solving workload problems.
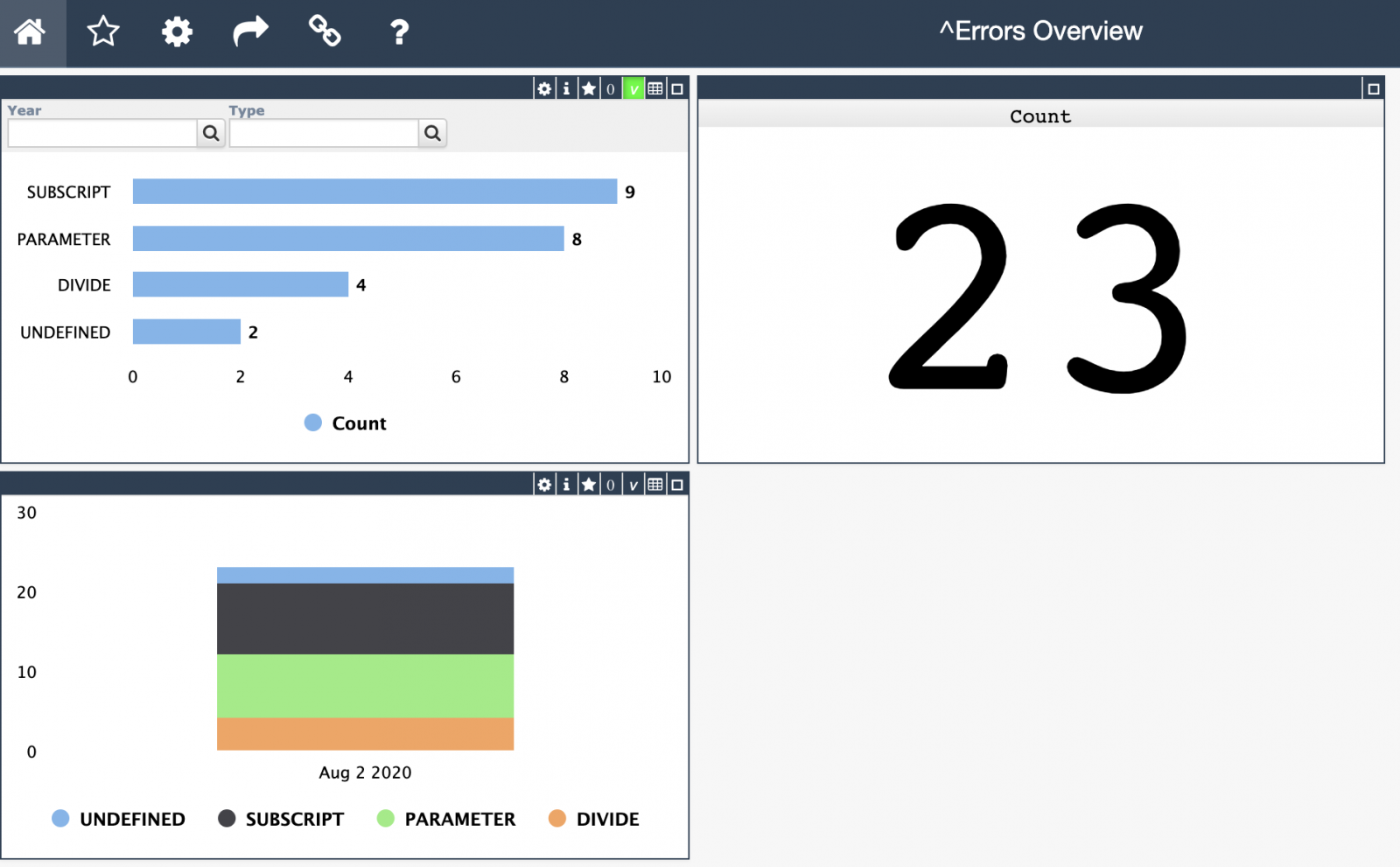
So I made it to the eBPF party and have been attending clinic after clinic on the subject ever since, here I would like to "unbox" eBPF as a technical solution, mapped directly to what we do in practice (even if its a bit off), and step through eBPF through my experimentation on supporting InterSystems IRIS Workloads, particularly on Kubernetes, but not necessarily void on standalone workloads.
 Open Exchange app
Open Exchange app

.png)