 By likes
By likesHi all,
I recently discovered the Monitoring Activity Volume feature in IRIS and I was amazed by it. So, I put it to work in one of our productions. It is nice how easy it is to set up and all the possibilites that came with it.
But there's something weird: the numbers. Actually, one of the BP is stating a time of more than 6 seconds to process:
.png)

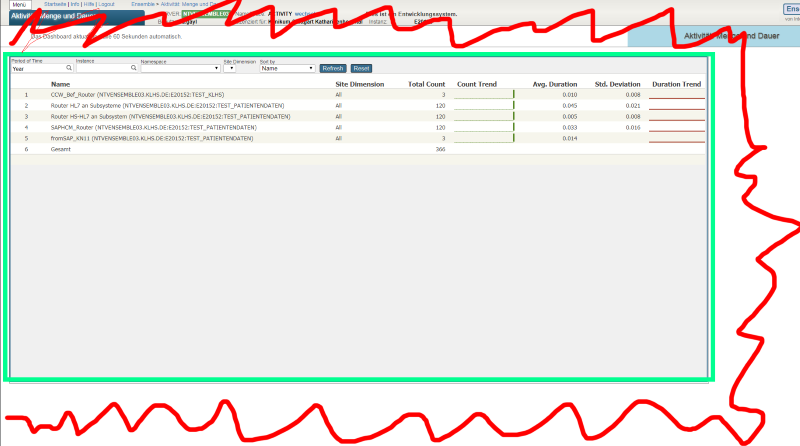
.png)
