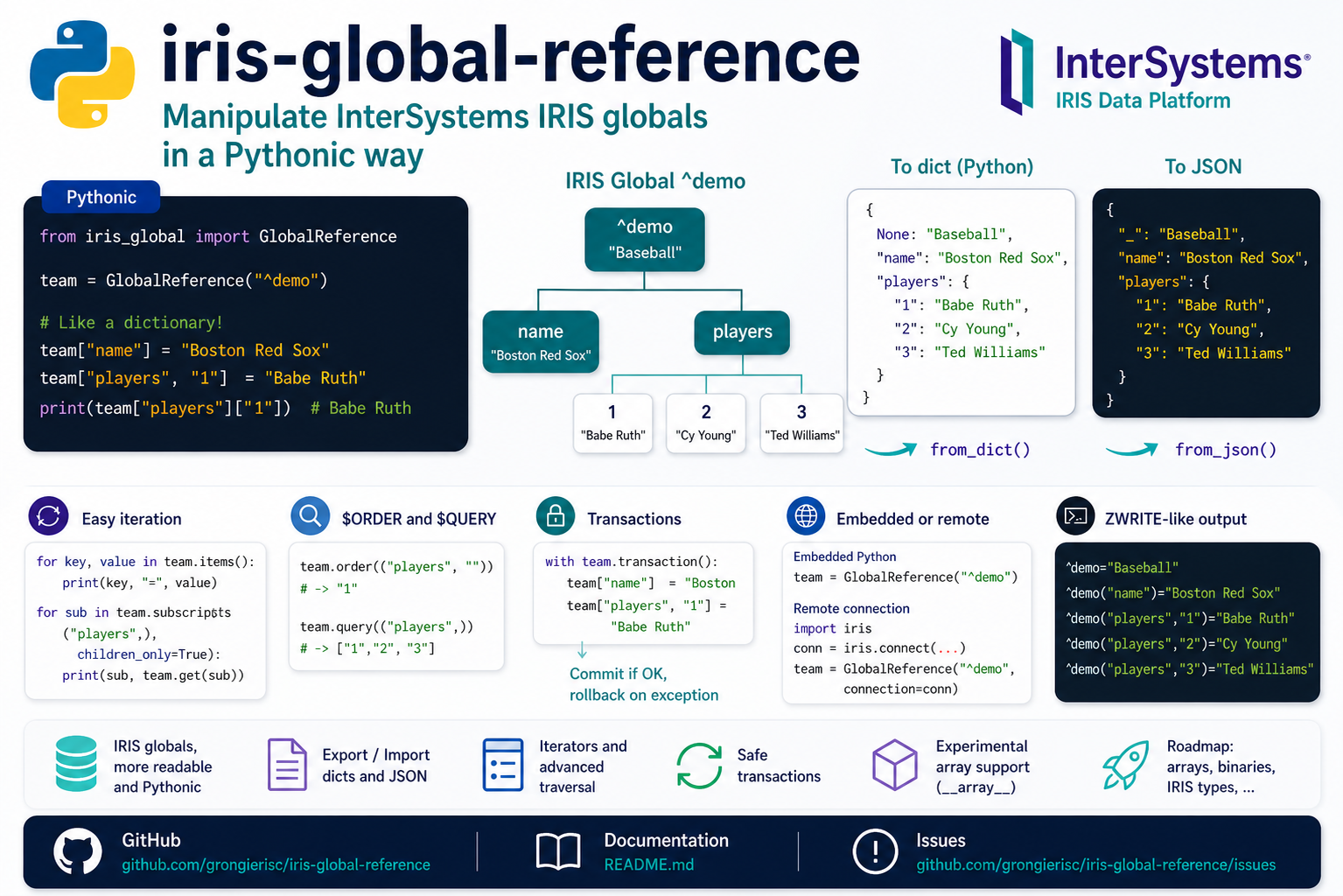
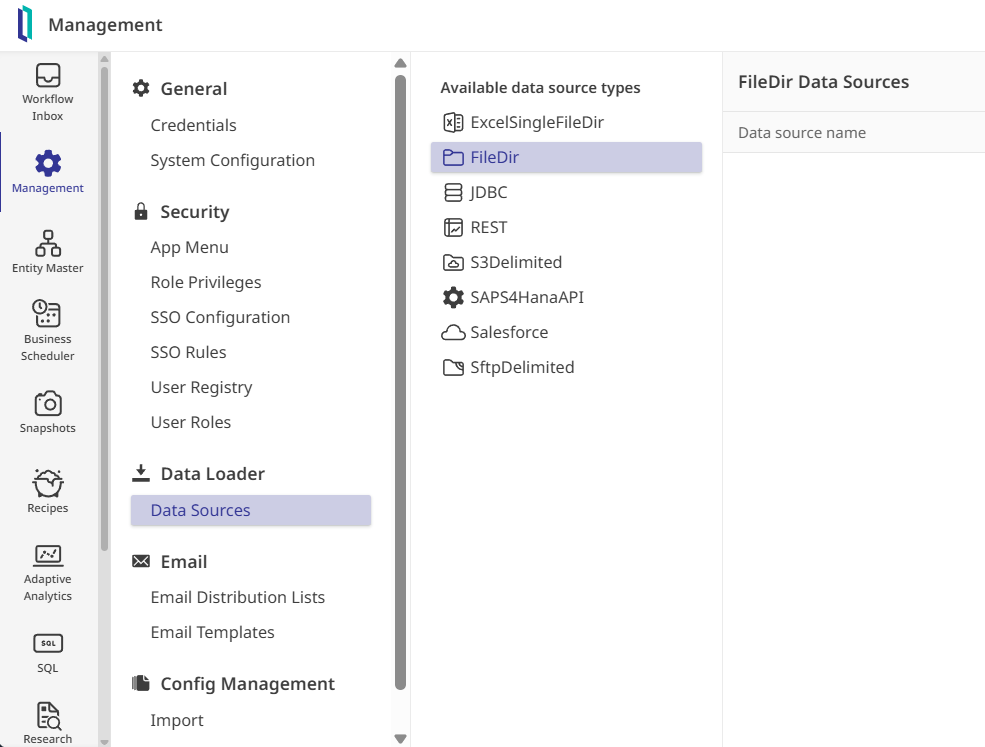
When managing critical healthcare data through an integration engine you want to know the moment a queue starts backing up or a service drops.
Unfortunately, this usually leads to an email inbox stuffed full of notifications that can sometimes seem impossible to maintain.
Well, I’ve not solved that problem.
But I have created something that could help...