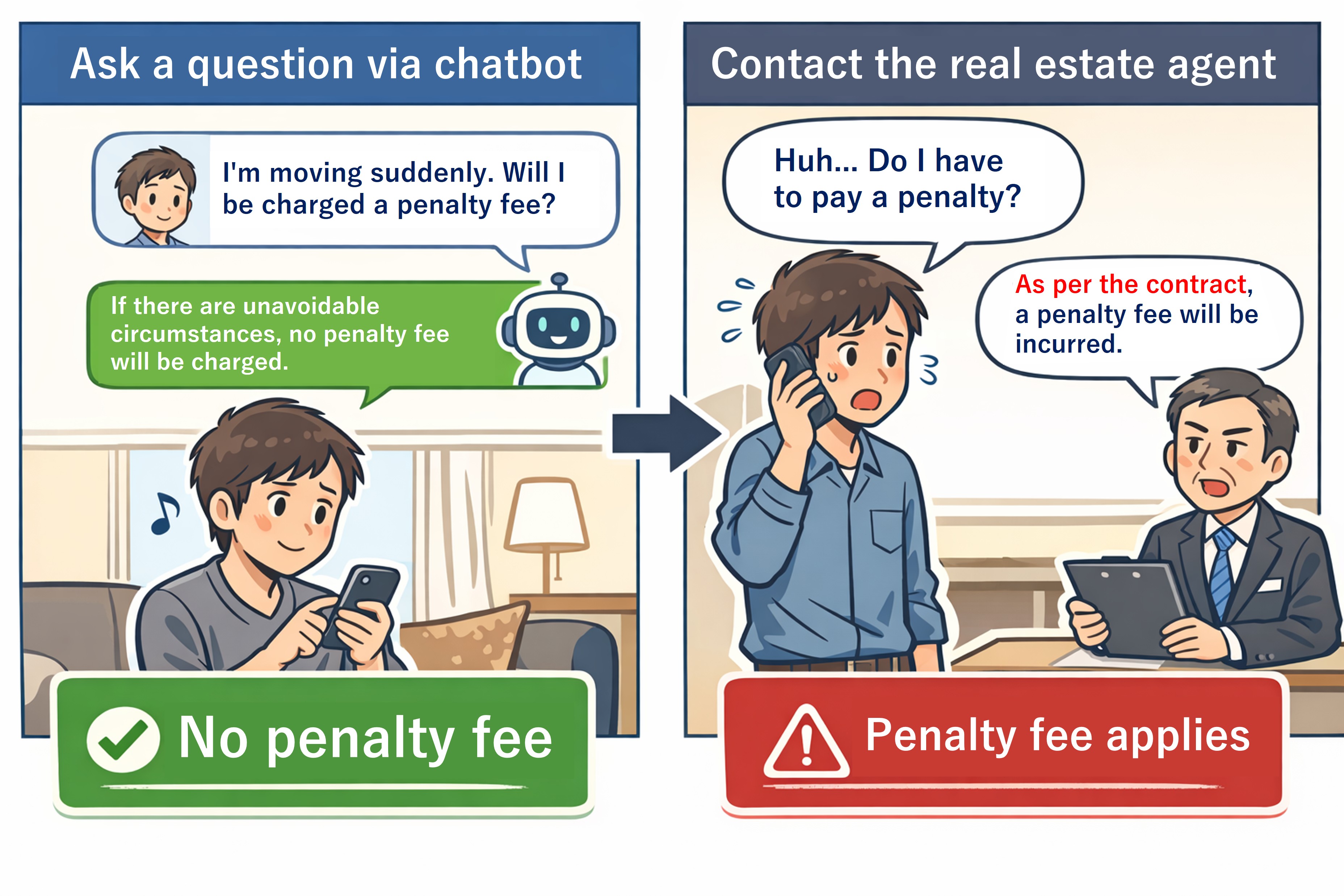
Introduction
In my previous article, I introduced the FHIR Data Explorer, a proof-of-concept application that connects InterSystems IRIS, Python, and Ollama to enable semantic search and visualization over healthcare data in FHIR format, a project currently participating in the InterSystems External Language Contest.
In this follow-up, we’ll see how I integrated Ollama for generating patient history summaries directly from structured FHIR data stored in IRIS, using lightweight local language models (LLMs) such as Llama 3.2:1B or Gemma 2:2B.
The goal was to build a completely local AI pipeline that can extract, format, and narrate patient histories while keeping data private and under full control.
All patient data used in this demo comes from FHIR bundles, which were parsed and loaded into IRIS via the IRIStool module. This approach makes it straightforward to query, transform, and vectorize healthcare data using familiar pandas operations in Python. If you’re curious about how I built this integration, check out my previous article Building a FHIR Vector Repository with InterSystems IRIS and Python through the IRIStool module.
Both IRIStool and FHIR Data Explorer are available on the InterSystems Open Exchange — and part of my contest submissions. If you find them useful, please consider voting for them!

.png)
.png)