The 2025.1.4 and 2024.1.6 maintenance releases of InterSystems IRIS® data platform, InterSystems IRIS® for Health, and InterSystemsHealth Connect™ are now Generally Available (GA). These releases include the fixes for a number of recently issued alerts and advisories, including the following:
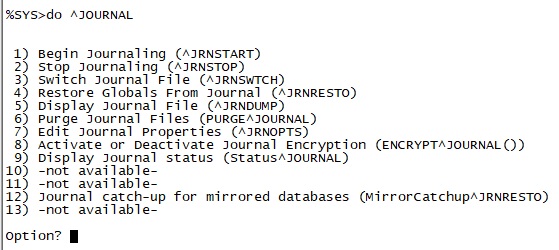
Global journaling records all global update operations performed on a database, and used in conjunction with backup makes it possible to restore a database to its state immediately before a failure or crash.
While backup is the cornerstone of physical recovery, it is not the complete answer. Restoring a database from backup does not recover global updates made since that backup, which may have been created a number of hours before the point at which physical integrity was lost. These post-backup updates can be restored to the database from journal files after the database is restored from backup, bringing the database up to date. Any transactions open at the time of the failure are rolled back to ensure transaction integrity.