Hi Community!
I'm super excited to be your on-the-ground reporter for the biggest developer event of the year - InterSystems Ready 2025!
As you may know from previous years, our global summits are always exciting, exhilarating, and packed with valuable knowledge, innovative ideas, and exciting news from InterSystems. This year is no different. But let's not get ahead of ourselves and start from the beginning.
Pre-summit day was, as usual, filled with fun and educational experiences. Those who enjoy playing golf (I among them) got up at the crack of dawn to tee off before the sun got too high up. Here's our dream team in action:

@sween, @Mark Bolinsky, @Anzelem Sanyatwe, @Iryna Mykhailova
 By update
By update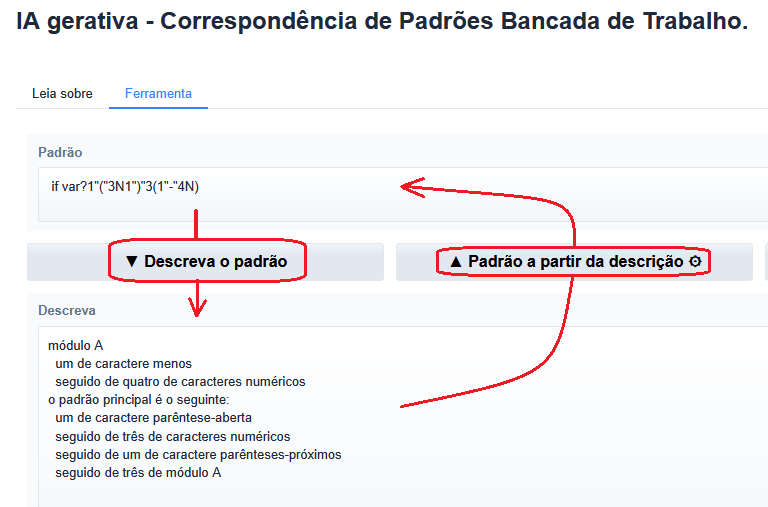
 Open Exchange app
Open Exchange app(2).jpg)

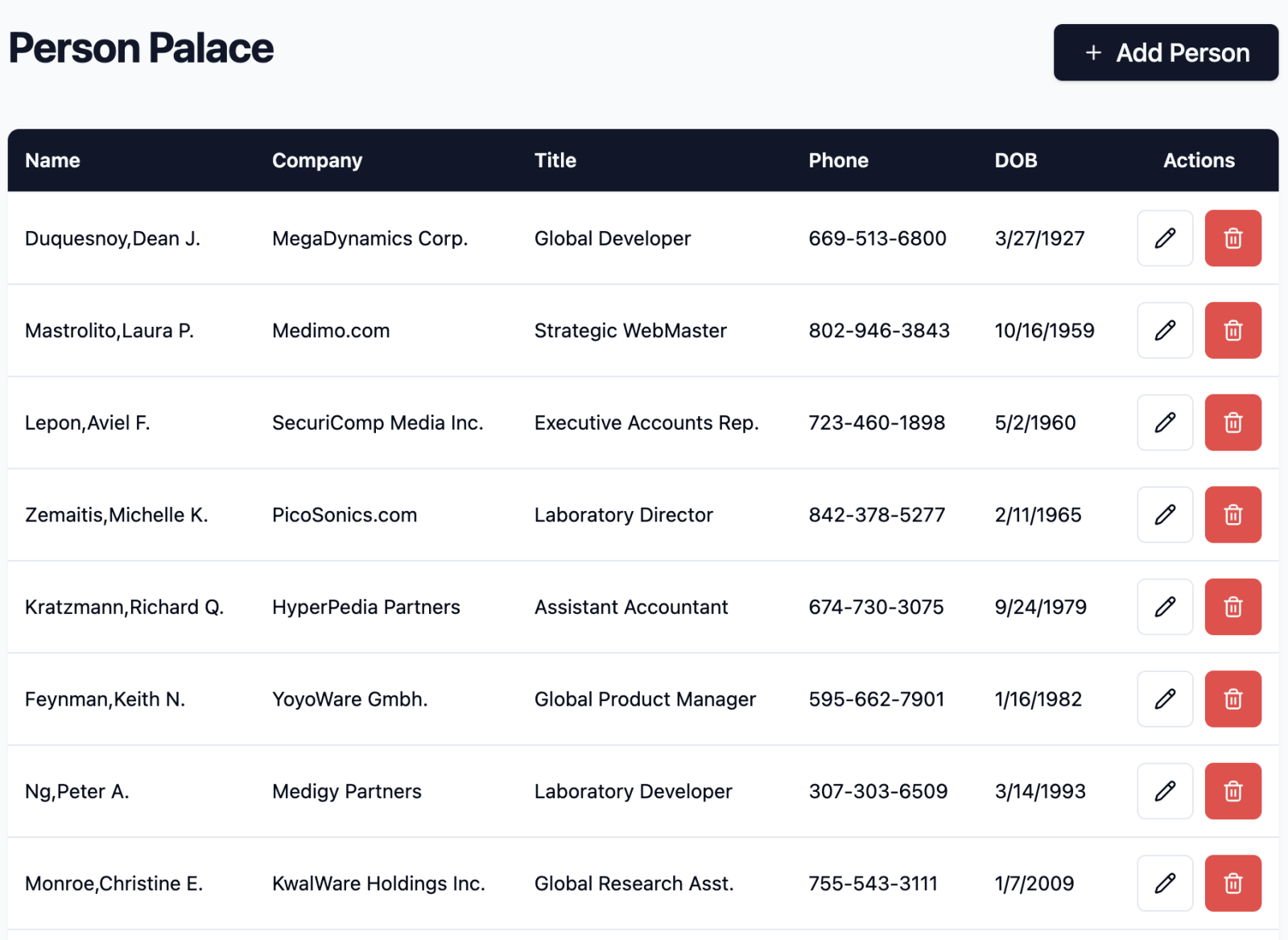




.png)