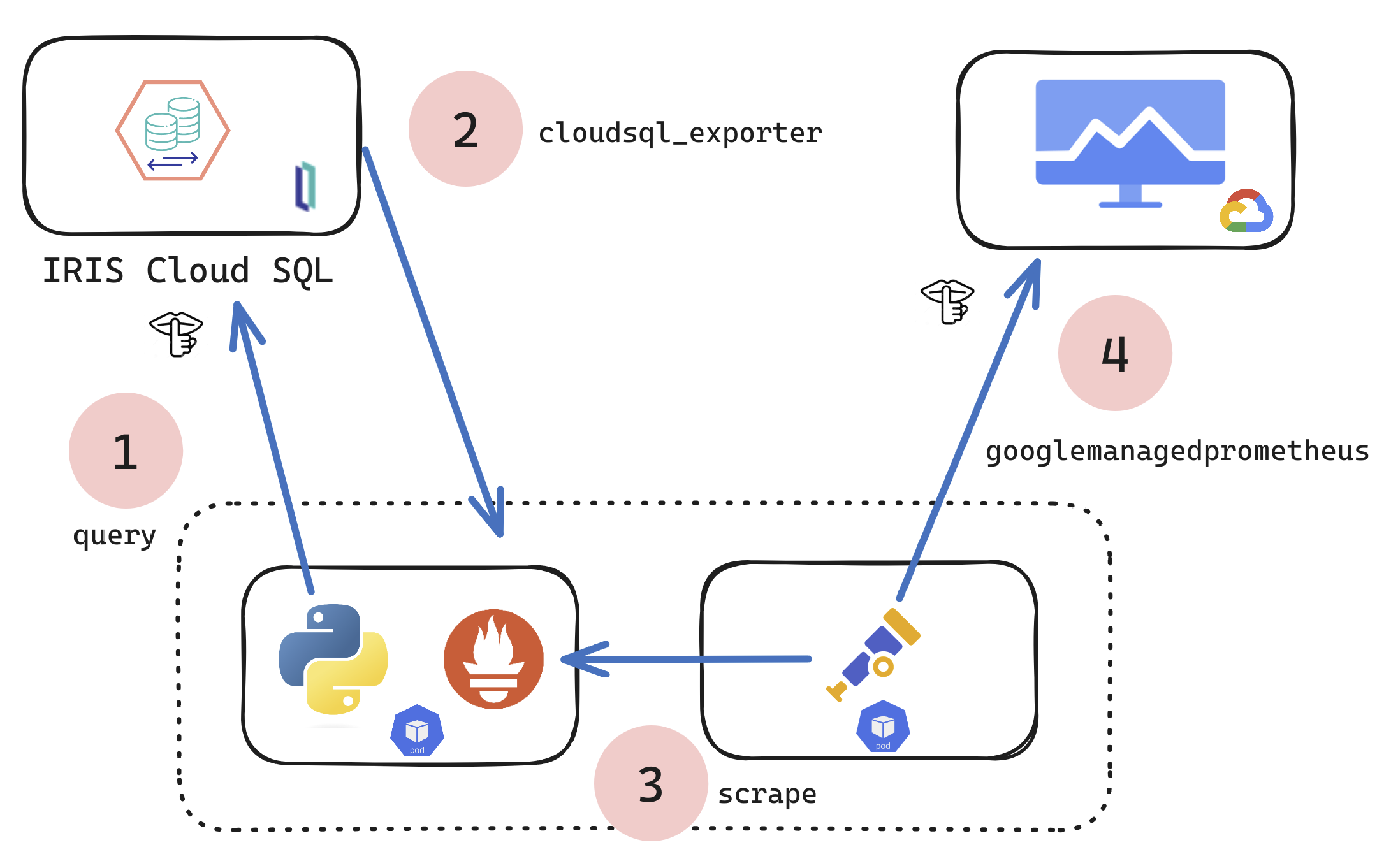
The problem
How many times have we migrated an IRIS Instance to another machine, maybe even another version, and after a few days realized we forgot that one SSL Configuration critical for a Business Operations to work? Or maybe a credential, or a lonely class in a package by itself?
The solution
The simple solution is to make a checklist¹. A checklist of the entities we have to move. But simple checklists on Word documents are often forgotten, or just ignored.

.png)
.png)

.png)
.png)