Hi,
During the implementation of iris-history-monitor using ZPM, I'm bumping on the following scenario:
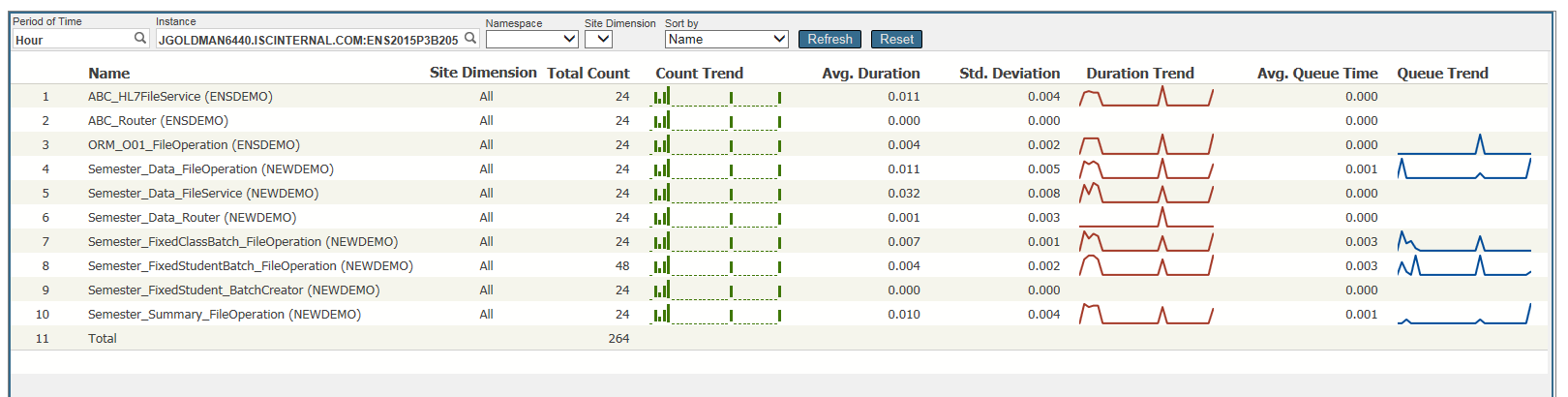
My Installer.cls has a call for the Custom Sensors Class method. The Custom information looks like a charm as I described in this article:
IRIS History Monitor using custom built-in REST API /api/monitor/metrics
But, now I'm trying to replicate the same behavior using the module.xml to work with ZPM.
<?xml version="1.0" encoding="UTF-8"?>
<Export generator="Cache" version="25">
<Document name="iris-history-monitor.ZPM">
<Module>
<Name>iris-history-monitor</Name>
<Version>1.2.2</Version>
<Packaging>module</Packaging>
<SourcesRoot>src</SourcesRoot>
<Resource Name="diashenrique.historymonitor.dashboard.PKG"/>
<Resource Name="diashenrique.historymonitor.util.PKG"/>
<Invokes>
<Invoke Class="diashenrique.historymonitor.util.customSensors" Method="CustomApplicationMetrics"></Invoke>
<Invoke Class="diashenrique.historymonitor.util.Favorite" Method="%AddFavorite">
<Arg>HistoryMonitor</Arg>
<Arg>/csp/irismonitor/dashboard.csp</Arg>
</Invoke>
</Invokes>
<CSPApplication
Url="/csp/irismonitor"
Path="/src/csp"
Directory="{$cspdir}/irismonitor"
ServeFiles="1"
Recurse="1"
CookiePath="/csp/irismonitor"
UseCookies="2"
MatchRoles=":%DB_${Namespace}"
PasswordAuthEnabled="1"
UnauthenticatedEnabled="0"
/>
</Module>
</Document>
</Export>.png)