 By likes
By likesAPM normally focuses on the activity of the application but gathering information about system usage gives you important background information that helps understand and manage the performance of your application so I am including the IRIS History Monitor in this series.
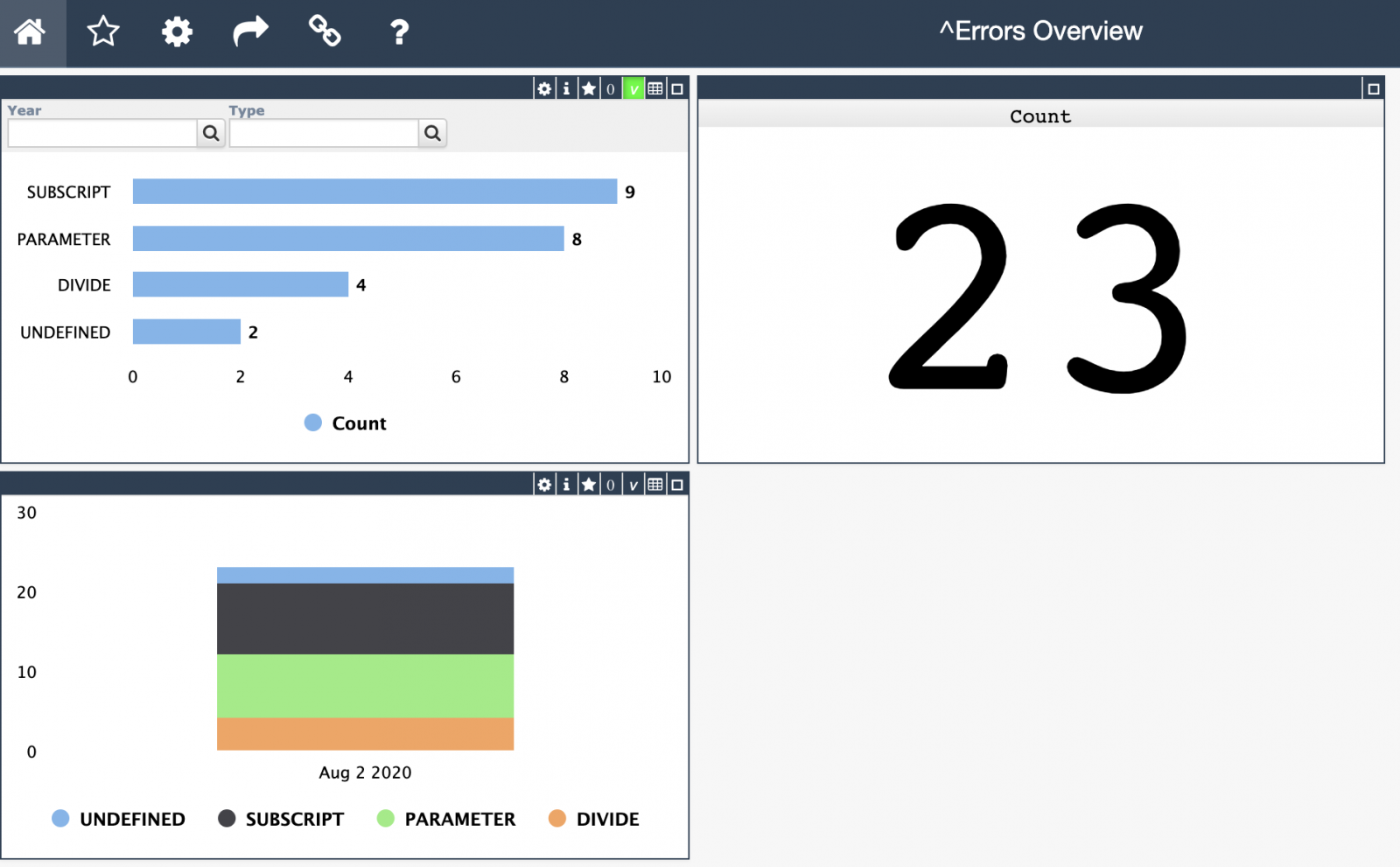
In this article I will briefly describe how you start the IRIS or Caché History Monitor to build a record of the system level activity to go with the application activity and performance information you gather. I will also give examples of SQL to access the information.
 Open Exchange app
Open Exchange app.png)
.png)
.png)