If you have an app that uses some Caché client Windows components that are not included into CacheODBC distribution (e.g. CacheActiveX.dll), you need to proceed Caché client installation on end user's client computers and/or MS Terminal Servers. Being a part of Caché client's installation, Caché Cube is installed along with other components and is autostarted with every user's session. So, it becomes visible to every user.
To make it completely invisible, you can just move CACHE.lnk file from
Now the Classes/Rutines/DeepSee files will be automatically exported to the working directory after saving or compiling and files will be automatically deleted .
https://www.youtube.com/embed/B1pmqAQqd4M [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
Installation
To install isc-dev , you just need to download and import the file isc-dev.xml from last release.
Some ways to import isc-dev .xml file:
Go to Management Portal -> System Explorer -> Classes -> Import and select the XML file.
This is my first post in the developer community - would appreciate any feedback!
For testing or demo purposes, you may want to send emails from your Interoperability Production. In this post then I will walk you through connecting an InterSystems IRIS Production to Gmail so you can use it to send emails alerts.
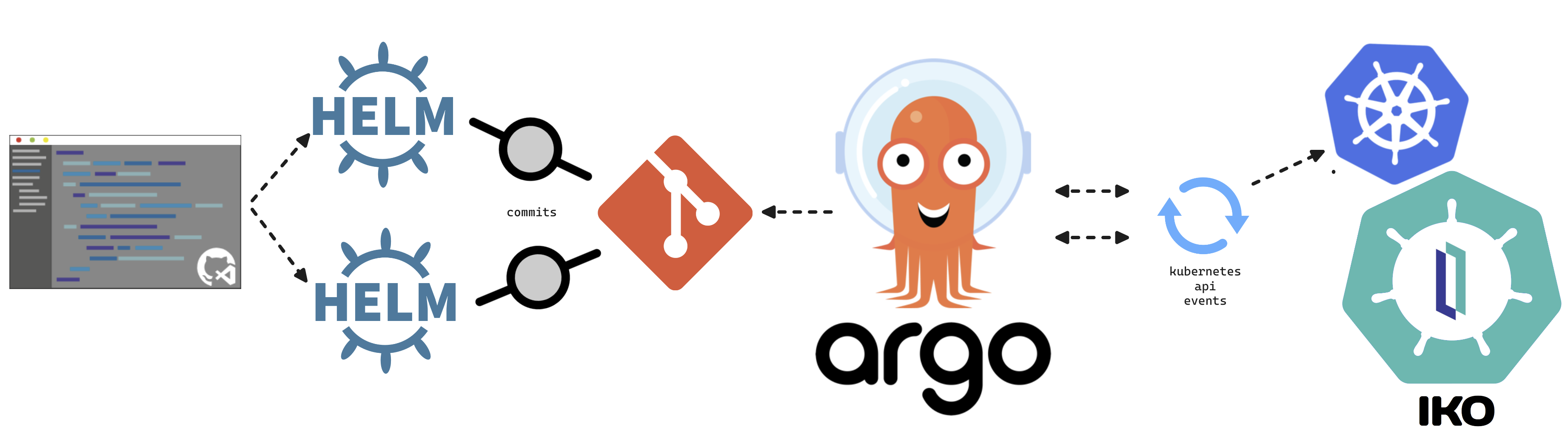
This article will cover turning over control of provisioning the InterSystems Kubernetes Operator, and starting your journey managing your own "Cloud" of InterSystems Solutions through Git Ops practices. This deployment pattern is also the fulfillment path for the PID^TOO||| FHIR Breathing Identity Resolution Engine.
Creating your own commands or shortcut is one of the strongest features of ObjectScript If you create your own Language Extensions to ObjectScript you mostly have to find the proper %ZLANGC00 or %ZLANGV00 or %ZLANGF00 and add the extensions manually.
A few utilities do it already automatically (ZPM, ZME, ..) This utility allows you to add your extensions also programmatically.
By default, Analyzer executes queries as components are added. Often, there are times where you may know exactly what you are looking to do, and you do not want Analyzer to execute 5 queries as you drag and drop items onto rows/columns and select your filters. This is where toggling Auto-execute off can help.
The simple answer is: a custom widget. A portlet can exist by itself on a DeepSee dashboard, it can be used along side standard DeepSee widgets, or along side other portlets. The rendering of the custom widget is completely user defined. This means you can embed a web page, create a form to perform any sort of action needed based on the data on your dashboard, use third party charting libraries, or simply display data from outside of a DeepSee cube.
You can hide the source by exporting/importing only the *.obj that is generated after compiling the source program.
The command execution example specifies EX1Sample.obj and EX2Sample.obj, which are generated by compiling EX1Sample.mac and EX2Sample.mac, as export targets and exports them to the second argument file.
After moving to another namespace, I am using the exported XML file to perform the import.
In the first installment of this article series, we discussed how to read a “big” chunk of data from the raw body of an HTTP POST method and save it to a database as a stream property of a class. Now let’s look at how to save such data and metadata in JSON format.
During the last weeks, I was working on various issues and problems related to SW development. I found that quite often problem analysis was mostly chasing issues just on the surface but not really attacking the deeper reasons of the problem and follow the consequences. It's like the doc that stops your leg bleeding but doesn't see that it is broken.
If you read my previous post that introduced QEWD Micro-Services, you're hopefully eager to learn how to use them. So in this post I'll explain what you need to know in order to get started.
If you look in the QEWD repository, you'll find the folder:
It is often necessary to sort the results of a query on a string field containing a combination of alphabetic and numeric characters. In cases like this the default string collation may not always return the data in the expected sequence.
An example of this may be where a select from Samples.Person should order the results by the street address, but firstly ordered by the street number part as numeric, and then by the street name.
The default query will return the results as follows:
Effective documentation is a cornerstone of software development, aiding in code comprehension, maintenance, and collaboration. By harnessing the power of Doxygen and the ObjectScript filter I've created, you can generate rich static documentation from your source code. This approach does not require a running IRIS instance and thus is a good choice in situations when access to IRIS is not possible. Static documentation may be provided to end-users as-is, together with the source code.
For those of you who might be new to IRIS, and even those who have used Cache or IRIS for some time but want to explore beyond its usually-assumed boundaries and practices, you might want to dive into this detailed exploration of the database engine that is at its heart, and discover just what you can really do with it, going way beyond what InterSystems have done with it for you.
Those of you who are following the FullStack competition here in the Developer Community will know that I submitted an entry named qewd-conduit. I wanted to summarise why I think it's something worth you taking a bit of time to check out.
qewd-conduit uses the Node.js-based QEWD framework alongside IRIS to implement the back-end REST APIs for something known as the RealWorld Conduit application:
Presenter: Matt Spielman Task: Use the FHIR standard with HealthShare-based solutions Approach: Provide an overview of how HealthShare will support the evolving FHIR
The next major release of HealthShare will be the first version to support the emerging HL7 FHIR standard. This presentation will discuss InterSystems’ involvement with the FHIR standard, detail the new FHIR functionality, and review our long term plans for FHIR in the HealthShare platform.
Content related to this session, including slides, video and additional learning content can be found here. Please note that this content is available only to HealthShare customers and attendees of the Global Summit. On the learning web site you will be prompted for your Global Summit credentials to access this content.
Despite the fact that InterSystems has long recommended using external backup tools, many users have opted to use the internal Online Backup facility, which is included in all distributions of InterSystems products (IRIS Data Platform, Caché, etc.). The reasons why are quite obvious:
A group of students at the Chalmers University of Technology (Gothenburg, Sweden) tried different approaches to automatically rating the quality of emergency calls, including iKnow.
Excerpt: "The most impressive results produced by iKnow is its ability to correctly classify 100% of the calls using the Average algorithm. This is quite surprising since iKnow only compares low-level concepts, how words relates to each other."
 By views
By views Open Exchange app
Open Exchange app