IRIS AI Studio: A playground to explore the Generative AI & Vector Embedding capabilities

Problem
Do you resonate with this - A capability and impact of a technology being truly discovered when it's packaged in a right way to it's audience. Finest example would be, how the Generative AI took off when ChatGPT was put in the public for easy access and not when Transformers/RAG's capabilities were identified. At least a much higher usage came in, when the audience were empowered to explore the possibilities.
Motivation
Recently I got to participate in MIT Grand Hack, Boston where during my conversation with other participants, I noticed immense interest from physicians and non-technical veterans to explore the Generative AI capabilities in their domain. In one of the talks, a finest example, that showcased how the EHR's have a complicated UI being compared with a sleek UI of ChatGPT. Though they both address different needs and comes with it's own pros and cons, my key takeaway was, "The world is not going back towards, complicated user interfaces, or slow systems. And the future lies in systems characterized by intuitive design and optimized performance".
For the non-technical stakeholders who wanted to explore the Generative AI capabilities, is there a way to do it without much of technical hassle. Indeed, Co-lab/Jupyter notebooks have significantly simplified the process of running code. However, can we further streamline this to resemble the intuitive interfaces of platforms like OpenAI's Playground or Azure/Vertex AI Studio? Such a user-friendly environment would empower non-technical stakeholders to grasp the capabilities and constraints of Vector DB effortlessly.
⚡️ How might we enable non-technical individuals, to evaluate IRIS vector DB potential use cases for their products/services, without exhausting developer resources?
Solution
IRIS AI Studio— A no-code/low-code platform to explore the capabilities of vector embeddings in IRIS DB. User can seamlessly load data from various sources as vector embeddings into IRIS DB and then retrieve the information through multiple channels. Here, the loading of data is called Connectors and retrieval part can be done through Playground. At its core, IRIS AI Studio simplifies the process of working with vector embeddings and let user visualize the power of AI being harnessed for diverse applications.
Connectors
In connectors, the user starts with choosing the data source where they wanted to get the data from to load into IRIS DB as vector embeddings. They can upload files from their local system or retrieve data from cloud storage services as well. This feature has the potential to function as a data pipeline with the addition of CRON job capabilities.
Initially I have added 4 different data sources - Local Storage, AWS S3, Airtable and Azure Blob Storage.
After choosing the data source, user needs to input the concerned additional information, like client id and secret key for AWS S3 storage. Then, user can configure the embeddings, by choosing the indexing type, model they wanted to use, dimensions and enter the data table name in IRIS, this data needs to be loaded into. Currently indexing from OpenAI and Cohere embeddings are supported, but just with few lines of code, we could add support for many other embeddings.
After finishing the two steps, the data from the source is converted as vector embeddings and added to the IRIS data table.
.png)
Playground
Now that we have the vector embedded data in IRIS DB, letting user retrieve the contents in their preferred channels can be done from Playground. Here are few examples how that's done.
In Semantic Search user needs to enter the configurations that they've used to load the data and the semantic search query that they wanted to get executed on the vector embeddings. This will retrieve the contents from IRIS DB and return the results in a natural language format.

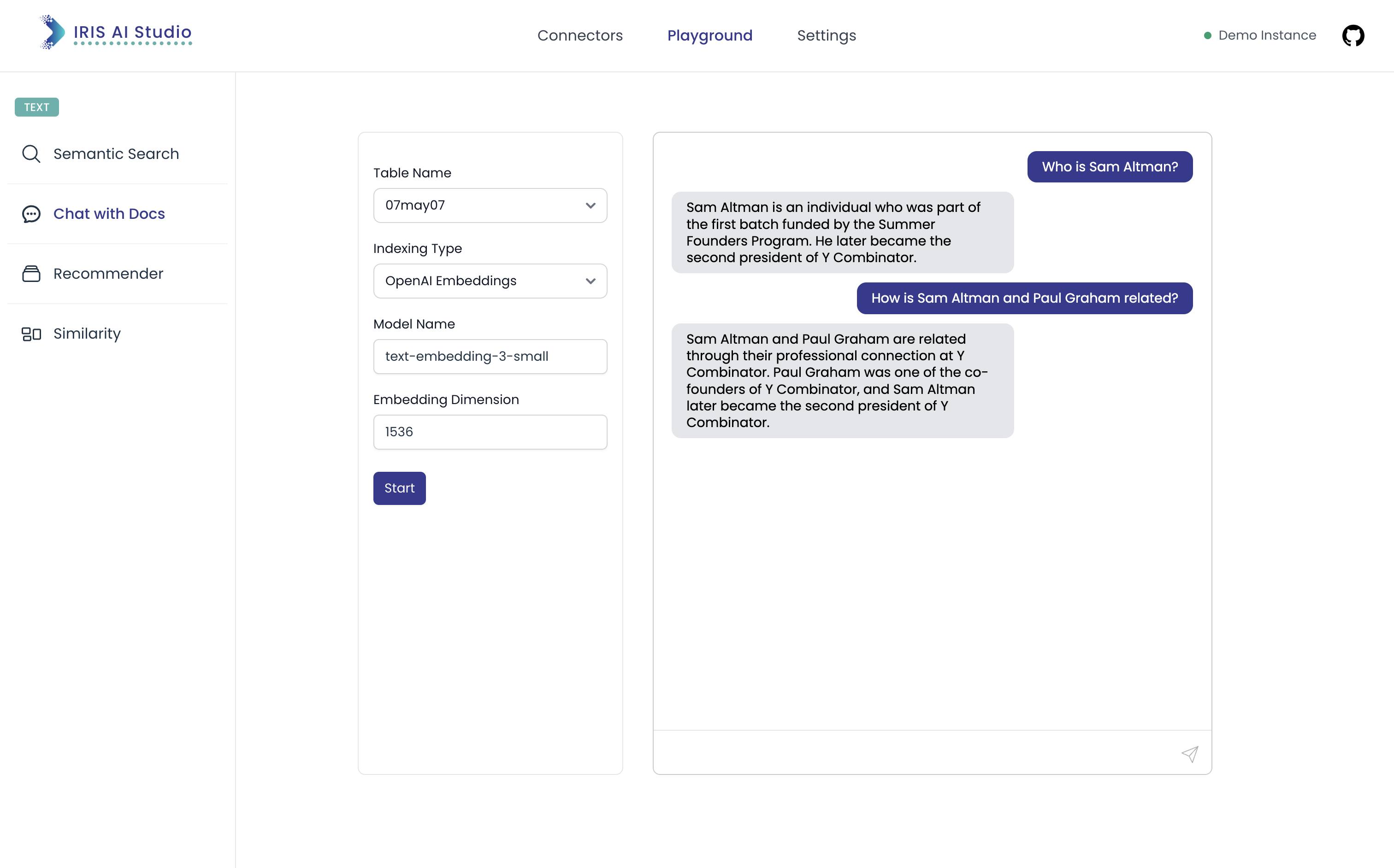
In the Chat with Docs user needs to enter the configurations that they've used to load the data and the chat query they wanted to make. The chat option gets differed from the query option significantly due to the context awareness. Also, in chat with docs we could plug in with many different LLM options to retrieve the contents and need not stick to the chosen indexing options (Currently OpenAI's GPT 3.5 turbo is added as default)
Settings
In the settings section, user could add multiple IRIS instance configurations which will be stored in the browser's local storage and user could choose which of them they wanted to actively engage with. This will make their work easier on managing multiple instances and choosing preferred ones to use. Also, here the LLM service's API Keys can be added (will be saved to browser's session storage) and automatically picked up during indexing or retrieval purposes. None of this information is being saved and it's been taken to the backend only for processing purposes.
.png)
Try it out
Clone the project repository from the following GitHub link: https://github.com/ikram-shah/iris-ai-studio.
Follow the provided instructions to set up the project locally on your machine. Please note, as on May 12, 2024 for some modules, development is still in-progress, but the functionality discussed above should work like a charm 💪🏻 Let know if something doesn’t work as expected through DM or issues section in Github.
Tech Stack
Frontend: VueJS, TailwindCSS, Flowbite
Backend: Python, Flask
Database: InterSystems IRIS
Frameworks/Libraries/Services: Llama-Index, SQLalchemy-iris, OpenAI, Cohere
Infrastructure: Vercel (frontend hosting), Render (backend hosting)
Credits
Thanks to the detailed documentation on Vector Search by InterSystems
Thanks to IRIS Vector Search template for simplifying the modules and capabilities by @Alvin Ryanputra
Thanks to llama-iris library by @Dmitry Maslennikov
Thoughts and Feedback
I come from Product Innovation and Engineering background, and for over a year now, I've been exploring the technological advancements in the healthcare sector. I'm here learning more from the ISC developers community and I am positive that this AI Studio platform would be of help in your work, say developers could share it with Program Managers / Physicians to get their inputs on the quality of data thats been retrieved and many others use cases. If this article resonated with you or sparked any thoughts, please give it a thumbs up 👍 and feel free to share your thoughts in the comments section below. I'd love to connect with anyone interested in discussing further!
🚀 Vote for this application in Vector Search, GenAI and ML contest, if you find it promising!
I will share few more posts that does technical deep dive of this platform.
Comments
Great application, do you know that iris now support wsgi app : https://docs.intersystems.com/iris20241/csp/docbook/Doc.View.cls?KEY=AWSGI
For the more, you did a pretty good job with a python only app, can you have a look at this one and tell me if you wish to learn more about Iop (Interoperability on python, the backend framework of this app): https://community.intersystems.com/post/vector-search-and-rag-retrieval-augmented-generation-models
Thank you, @Guillaume Rongier
This sounds interesting. Previously, I explored a few interoperability adapters for a different use case. But this example of performing vector operations through a lighter model seems exciting. I did go for llama-index for its connectors mainly, but I believe going through the interoperability route would be leaner, especially for some retrieval use cases, that I could think in terms of no. of operations.
I would definitely love to learn more, and this has sparked my excitement about having this capability in the playground. Let me look into it further!
Great idea, I've been using open-webui to do similar stuff but without IRIS obviously! There may be some ideas there, but the one I think may be good to plug into this would be the built in liteLLM integration it has to proxy out LLM connections to various providers. It's pretty simple to setup within the open-webui interface as well and then through the UI you can hit multiple LLMs easily, even doing multiple LLMs at once to compare results.
Could also be used to expose different embedding models for usage as well.
https://github.com/open-webui/open-webui
https://litellm.vercel.app
Thanks for sharing this @Richard Burrell . So helpful and relevant ones!
liteLLM sounds like a perfect need for a studio concept like this, which could help user explore possibilities from various different vendors. And it's nice they have a hosted UI for configuration too. That was actually an limitation for me while trying to scale up for more models, having a clear distinction of available Vendors, Models along with it's configuration wasn't easy to put through on a lean UI. OpenWebUI looks interesting too, but it would be more on the retrieval side alone right?
Yeh the OpenWebUI would be more on the retrieval side - though they do have their own RAG and vector storage built in - to go a level further would it be an idea be to build the IRIS capabilities around/into OpenWebUI as it is open source? so that way you save the effort on the front end retrieval/chat interface (and LLM integration and Ollama integrations for local models) that are then managed there by others and then build the functionality you have for IRIS around that? eg. add a section for direct semantic search and for the documents piece to be able to configure an IRIS DB as a target for vector/document data storage? (understand this might be a bit too much for now though!)
Yeah, that's a very fair point. Leveraging OpenWebUI would help scale up to bringing in more possibilities that IRIS could do with comparatively lower efforts than native UI stack. I wish I had known this before, would have been a different play on scaling up capabilities.