 All time
All time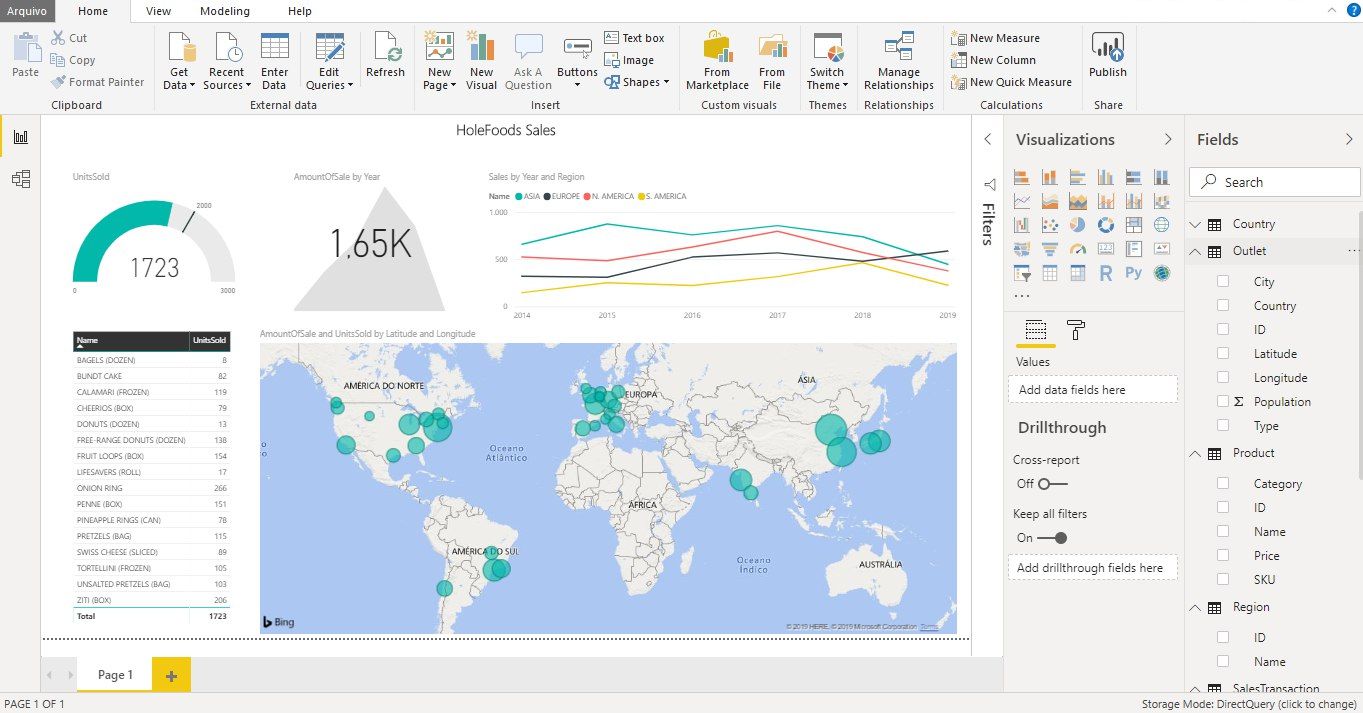
Apache Spark has rapidly become one of the most exciting technologies for big data analytics and machine learning. Spark is a general data processing engine created for use in clustered computing environments. Its heart is the Resilient Distributed Dataset (RDD) which represents a distributed, fault tolerant, collection of data that can be operated on in parallel across the nodes of a cluster. Spark is implemented using a combination of Java and Scala and so comes as a library that can run on any JVM.
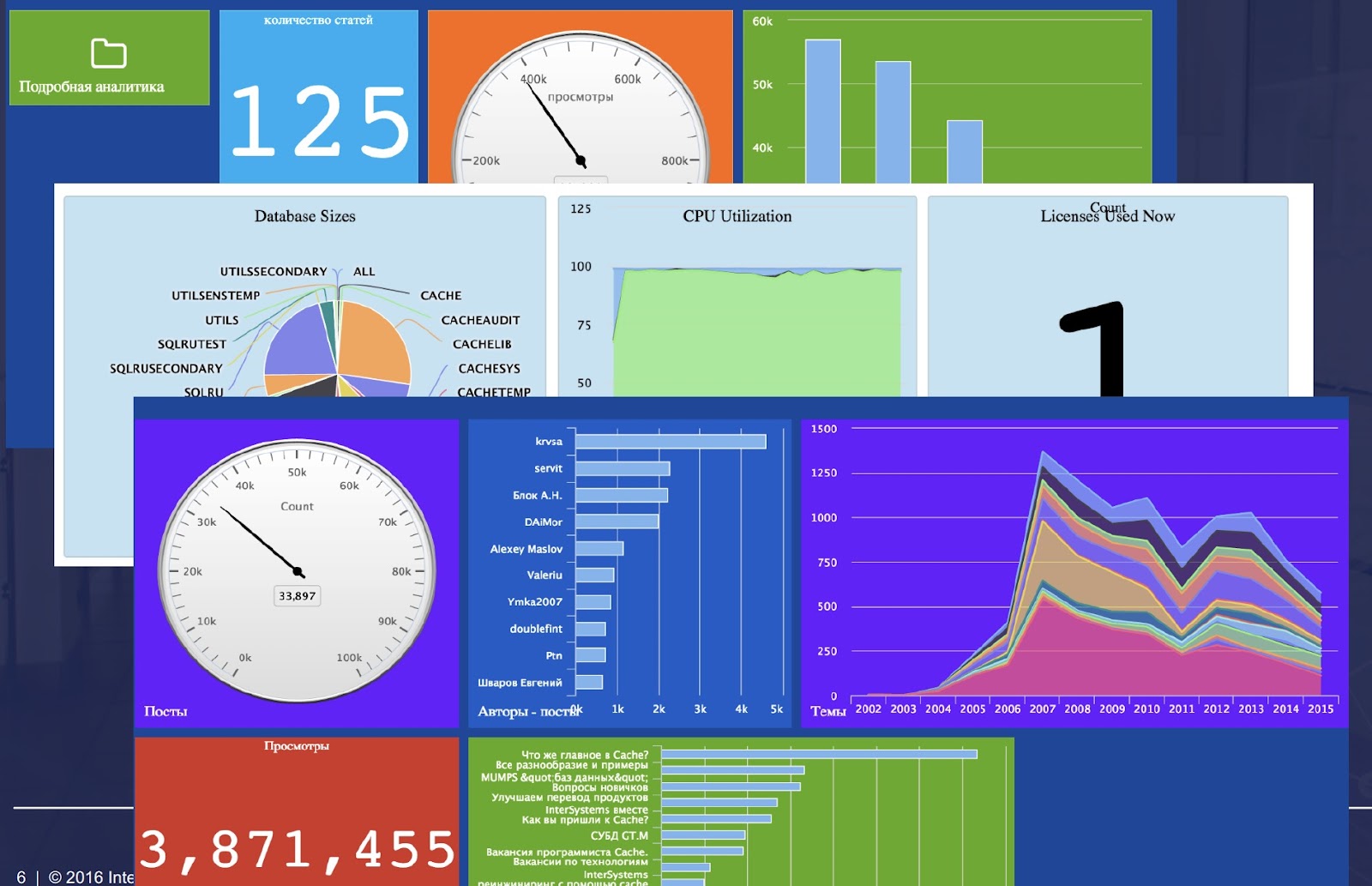

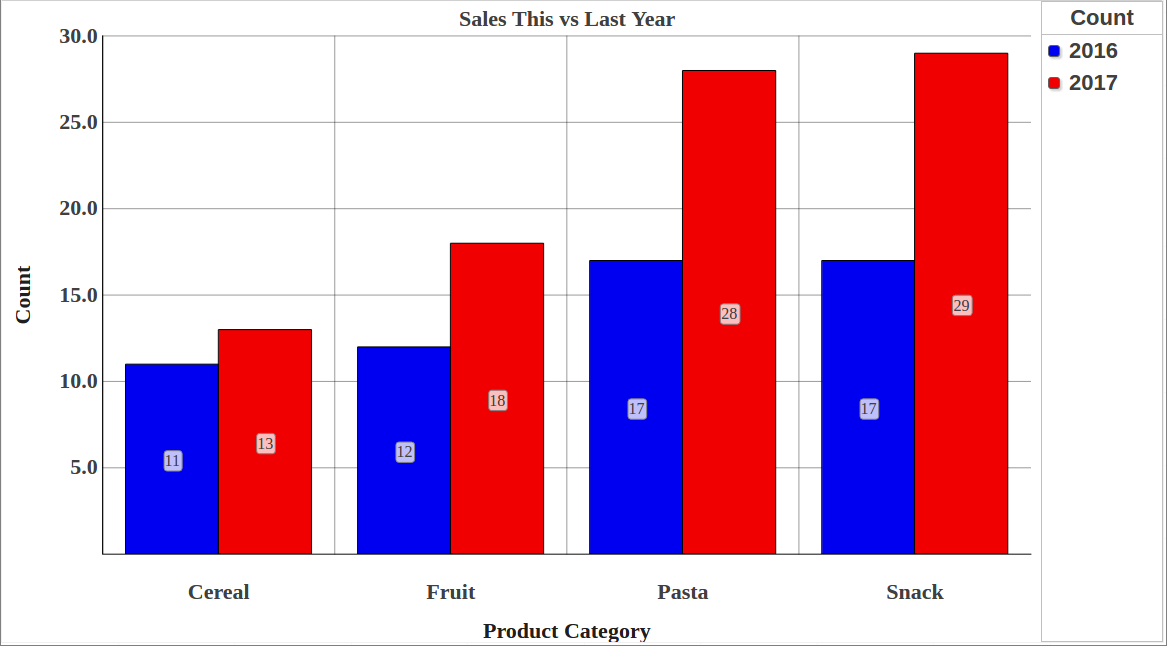
 Open Exchange app
Open Exchange app



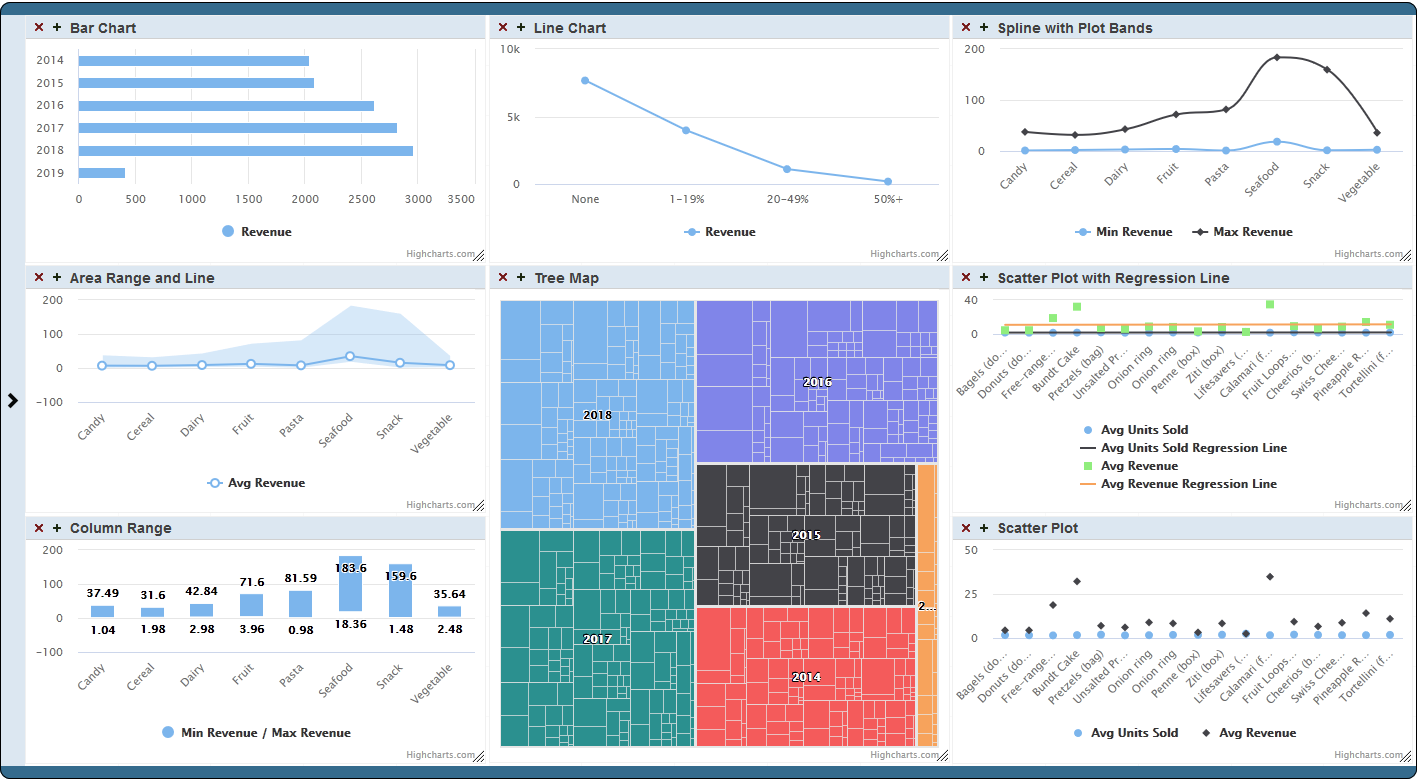
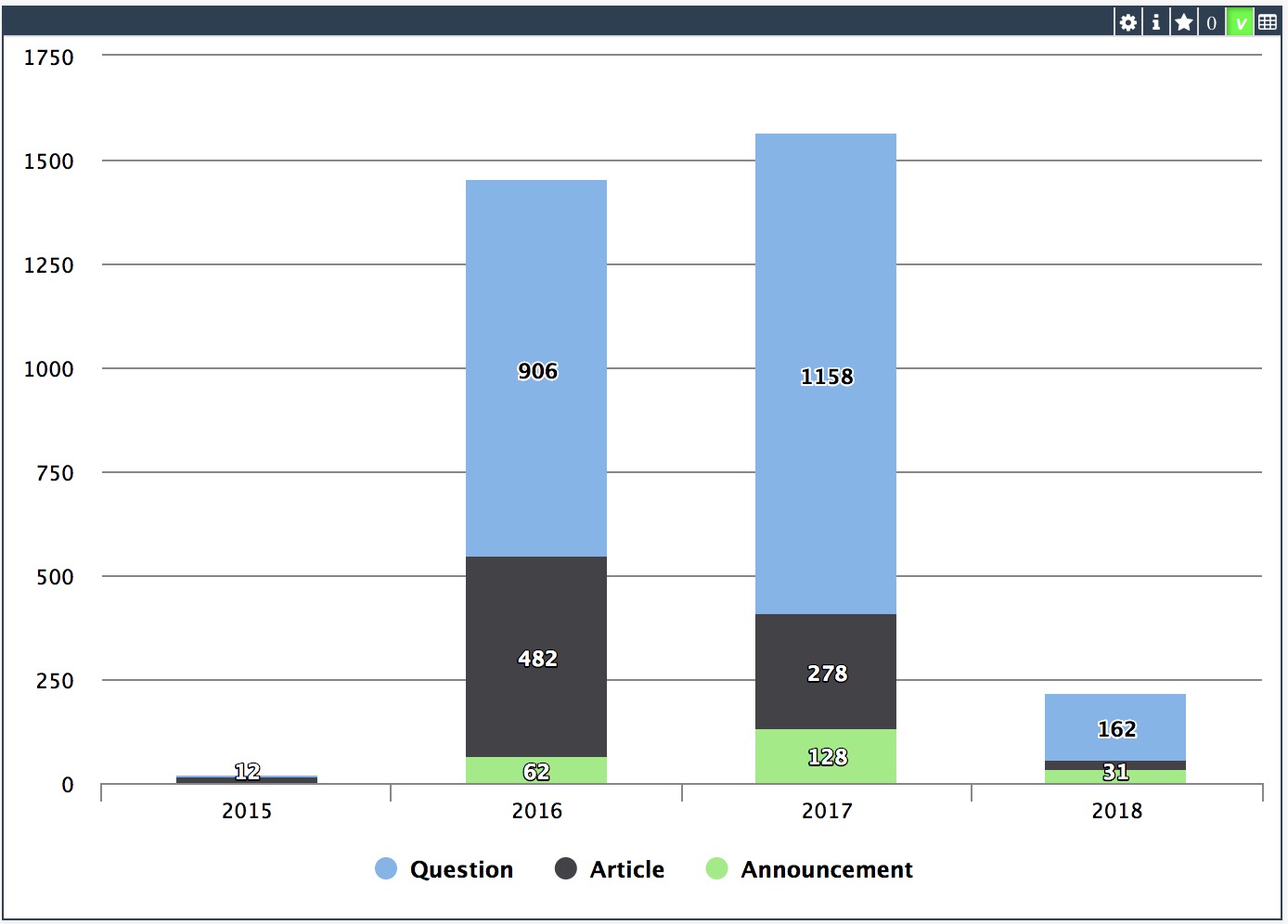
.png)