The PACELC theorem was created by Daniel Abadi (University of Maryland, College Park) in 2010 as an extension of the CAP theorem (created by Eric Brewer - Consistency, Availability, and Partition Tolerance). Both help design how to architect the most suitable operation of data platforms in distributed environments under the aspects of consistency versus availability. The difference is that PACELC also allows analysis of the best option for non-distributed environments, making it the gold standard for considering all possible scenarios to define your deployment topology and architecture.
The CAP theorem states that in distributed systems, it is not possible to have consistency, availability, and partition tolerance simultaneously, requiring a choice of two out of three, according to the following diagram.
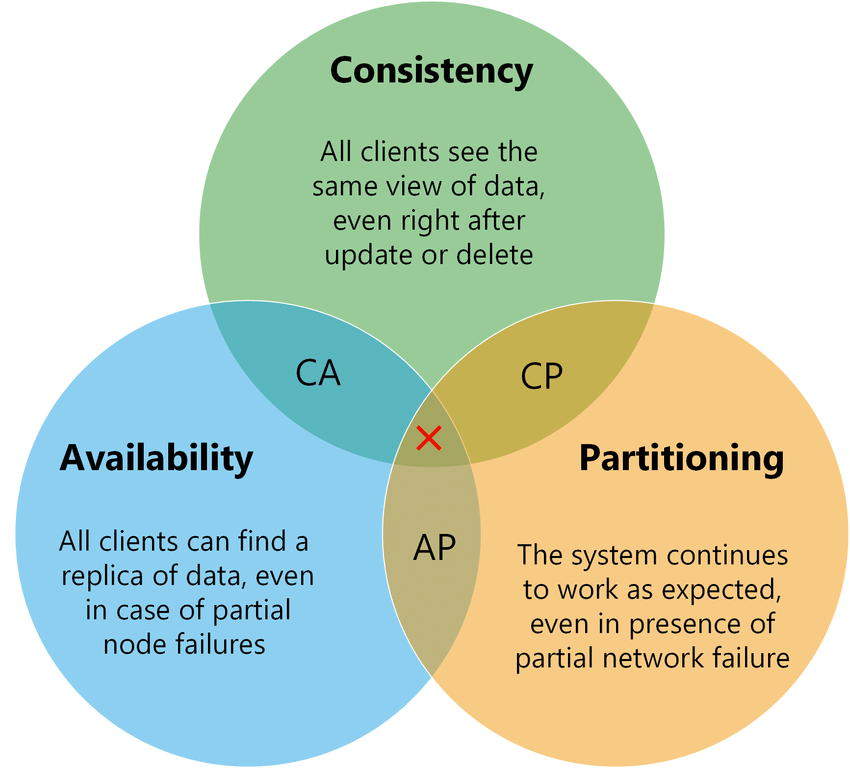
Source: https://medium.com/nerd-for-tech/understand-cap-theorem-751f0672890e
.png)