Horizontal Scalability with InterSystems IRIS
Last week, we announced the InterSystems IRIS Data Platform, our new and comprehensive platform for all your data endeavours, whether transactional, analytics or both. We've included many of the features our customers know and loved from Caché and Ensemble, but in this article we'll shed a little more light on one of the new capabilities of the platform: SQL Sharding, a powerful new feature in our scalability story.
Should you have exactly 4 minutes and 41 seconds, take a look at this neat video on scalability. If you can't find your headphones and don't trust our soothing voiceover will please your co-workers, just read on!
Scaling up and out
Whether it's processing millions of stock trades a day or treating tens of thousands of patients a day, a data platform supporting those businesses should be able to cope with those large scales transparently. Transparently means that developers and business users shouldn't worry about those numbers and can concentrate on their core business and applications, with the platform taking care of the scale aspect.
For years, Caché has supported vertical scalability, where advancements in hardware are taken advantage of transparently by the software, efficiently leveraging very high core counts and vast amounts of RAM. This is called scaling up, and while a good upfront sizing effort can get you a perfectly balanced system, there's an inherent limit to what you can achieve on a single system in a cost-effective way.
In comes horizontal scalability, where the workload is spread over a number of separate servers working in a cluster, rather than a single one. Caché has supported ECP Application Servers as a means to scale out for a while already, but InterSystems IRIS now also adds SQL sharding.
What's new?
So what's the difference between ECP Application Servers and the new sharding capability? In order to understand how they differ, let's take a closer look at workloads. A workload may consist of tens of thousands of small devices continuously writing small batches of data to the database, or just a handful of analysts issuing analytical queries each spanning GBs of data at a time. Which one has the largest scale? Hard to tell, just like it's hard to say whether a fishing rod or a beer keg is largest. Workloads have more than one dimension and therefore scaling to support them needs a little more subtlety too.
In a rough simplification, let's consider the following components in an application workload: N represents the user workload and Q the query size. In our earlier examples, the first workload has a high N but low Q and the latter low N but high Q. ECP Application Servers are very good at helping support a large N, as they allow partitioning the application users across different servers. However, it doesn't necessarily help as much if the dataset gets very large and the working set doesn't fit in a single machine's memory. Sharding addresses large Q, allowing you to partition the dataset across servers, with work also being pushed down to those shard servers as much as possible.
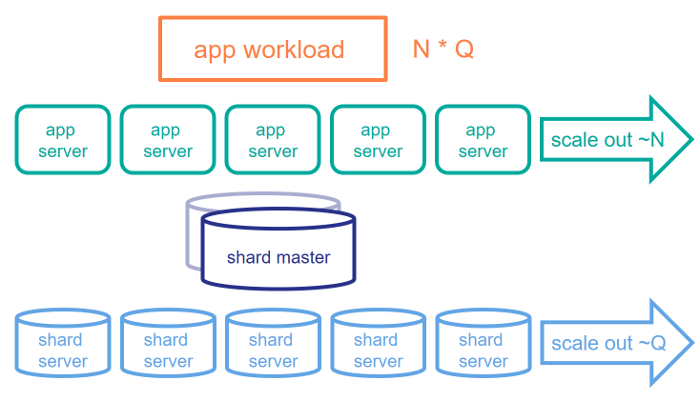
SQL Sharding
So what does sharding really do? It's a SQL capability that will split the data in a sharded table into disjoint sets of rows that are stored on the shard servers. When connecting to the shard master, you'll still see this table as if it were a single table that contains all the data, but queries against it are split into shard-local queries that are sent to all shard servers. There, the shard servers calculate the results based on the data they have stored locally and send their results back to the shard master. The shard master aggregates these results, performs any relevant combination logic and returns the results back to the application.
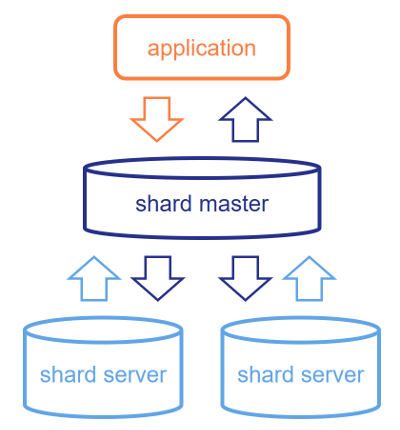
While this system is trivial for a simple SELECT * FROM table, there's a lot of smart logic under the hood that ensures that you can use (almost) any SQL query and a maximum amount of work gets pushed to the shards to maximize parallelism. The shard key, which defines which rows go where, is where you anticipate typical query patterns. Most importantly, if you can ensure that tables often JOINed together are sharded along the same keys, the JOINs can be fully resolved at the shard level, giving you the high performance you're looking for.
Of course this is only a teaser and there is much more to explore, but the essence is what's pictured above: SQL sharding is a new recipe in the book of highly scalable dishes you can cook up with InterSystems IRIS. It's complementary to ECP Application Servers and focuses on challenging dataset sizes, making it a good fit for many analytical use cases. Like ECP app servers, it's entirely transparent to the application has a few more creative architectural variations for very specific scenarios.
Where can I learn more?
Recordings from the following Global Summit 2017 sessions on the topic are available on http://learning.intersystems.com:
- What's Lurking in Your Data Lake, a technical overview of scalability & sharding in particular
- We Want More! Solving Scalability, an overview of relevant use cases demanding for a highly scalable platform
See also this resource guide on InterSystems IRIS on learning.intersystems.com for more on the other capabilities of the new platform. If you'd like to give sharding a try on your particular use case, check out http://www.intersystems.com/iris and fill out the form at the bottom to apply for our early adopter program, or watch out for the field test version due later this year.
Comments
Great article!
awesome
But what will this do with Object storage/access or (direct) global storage/access ? Is this data SQL-only ?
Hi Herman,
We're supporting SQL only in this first release, but are working hard to add Object and other data models in the future. Sharding any globals is unfortunately not possible as we need some level of abstraction (such as SQL tables or Objects) to hook into in order to automate the distribution of data and work to shards. This said, if your SQL (or soon Object) based application has the odd direct global reference to a "custom" global (not related to a sharded table), we'll still support that by just mapping those to the shard master database.
Thanks,
benjamin
Can we infer form this that sharding can be applied to globals that have been mapped to classes (thus providing SQL access)?
Hi Warlin,
I'm not sure whether you have something specific in mind, but it sort of works the other way around. You shard a table and, under the hood, invisible to application code, the table's data gets distributed to globals in the data shards. You cannot shard globals.
thanks,
benjamin
Let's say I have an orders global with the following structure:
^ORD(<ID>)=customerId~locationId.....
And I create a mapping class for this global: MyPackage.Order
Can I use sharding over this table?
To my understanding the structure of your global is irrelevant in this context.
If you want to use sharding forget about ALL global access.
You only access works over SQL ! (at least at the moment, objects may follow in some future)
It's the decision of the sharing logic where and how data are stored in globals.
If you ignore this and continue with direct global access you have a good chance to break it.
I understand the accessing part but by creating a class mapping I'm enabling SQL access to the existing global. I guess that the question is more in line on whether sharding will be able to properly partition (shard) SQL tables that are the result of global mapping? Are there any constraints on how the %Persistent class (and the storage) is defined in order for it to work with sharding? Should they all use %CacheStorage or can they use %CacheSQLStorage (as with mappings)?
If you have a global structure that you mapped a class to afterwards, that data is already in one physical database and therefore not sharded or shardable. Sharding really is a layer in between your SQL accesses and the physical storage and it expects you not to touch that physical storage directly. So yes you can still picture how that global structure looks like and under certain circumstances (and when we're not looking ;-) ) read from those globals, but new records have to go through INSERT statements (or %New in a future version), but can never go against the global directly.
We currently only support sharding for %CacheStorage. There's been so many improvements in that model over the past 5-10 years that there aren't many reasons left to choose %CacheSQLStorage for new SQL/Object development. The only likely reason would be that you still have legacy global structures to start from, but as explained above, that's not a scenario we can support with sharding. Maybe a nice reference in this context is that of one of our early adopters who was able to migrate their existing SQL-based application to InterSystems IRIS in less than a day without any code changes, so they could use the rest of the day to start sharding a few of their tables and were ready to scale before dinner, so to speak.
With the release of InterSystems IRIS, we're also publishing a few new great online courses on the technologies that come with it. That includes two on sharding, so don't hesitate to check them out!