 By likes
By likesBefore we start talking about databases and different data models that exist, first we'd better talk about what a database is and how to use it.
A database is an organized collection of data stored and accessed electronically. It is used to store and retrieve structured, semi-structured, or raw data which is often related to a theme or activity.
At the heart of every database lies at least one model used to describe its data. And depending on the model it is based on, a database may have slightly different characteristics and store different types of data.
To write, retrieve, modify, sort, transform or print the information from the database, a software called Database Management System (DBMS) is used.
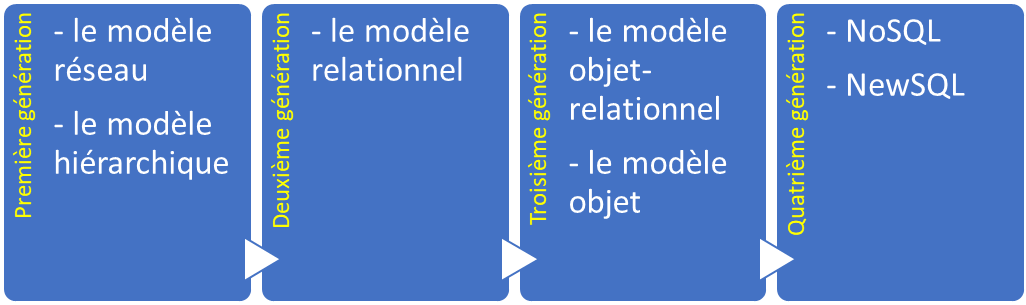
The size, capacity, and performance of databases and their respective DBMS have increased by several orders of magnitude. It has been made possible by technological advances in various areas, such as processors, computer memory, computer storage, and computer networks. In general, the development of database technology can be divided into four generations based on the data models or structure: navigational, relational, object and post-relational.

 Open Exchange app
Open Exchange app
.png)


