Data models in InterSystems IRIS
Before we start talking about databases and different data models that exist, first we'd better talk about what a database is and how to use it.
A database is an organized collection of data stored and accessed electronically. It is used to store and retrieve structured, semi-structured, or raw data which is often related to a theme or activity.
At the heart of every database lies at least one model used to describe its data. And depending on the model it is based on, a database may have slightly different characteristics and store different types of data.
To write, retrieve, modify, sort, transform or print the information from the database, a software called Database Management System (DBMS) is used.
The size, capacity, and performance of databases and their respective DBMS have increased by several orders of magnitude. It has been made possible by technological advances in various areas, such as processors, computer memory, computer storage, and computer networks. In general, the development of database technology can be divided into four generations based on the data models or structure: navigational, relational, object and post-relational.
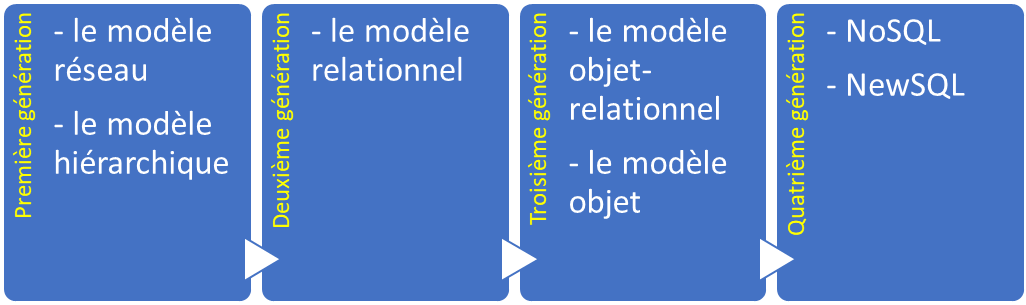

Unlike the first three generations, which are characterized by a specific data model, the fourth generation includes many different databases based on different models. They include column, graph, document, component, multidimensional, key-value, in-memory etc. All these databases are united by a single name NoSQL (No SQL or now it is more accurate to say Not only SQL).
Moreover, now a new class appears, which is called NewSQL. These are modern relational databases that aim to provide the same scalable performance as NoSQL systems for online transaction processing workloads (read-write) while using SQL and maintaining ACID.
Incidentally, among these fourth generation databases are those that support multiple data models mentioned above. They are called multi-model databases. A good example of this type of database is InterSystems IRIS. That is why I will use it to give examples of different types of models as they appear.
The first generation databases used hierarchical or network models. At the heart of the former is a tree structure where each record has only one owner. You can see how this works using the example of InterSystems IRIS, because its main model is hierarchical and all data is stored in globals (which are B*-trees). You can read more about globals here.

We can create this tree in IRIS :
Set ^a("+7926X", "city") = "Moscow"
Set ^a("+7926X", "city", "street") = "Req Square"
Set ^a("+7926X", "age") = 25
Set ^a("+7916Y", "city") = "London"
Set ^a("+7916Y", "city", "street") = "Baker Street"
Set ^a("+7916Y", "age") = 36And see it in the database:

After Edgar F. Codd proposed his relational algebra and his theory of data storage, using relational principles, in 1969. After, the relational databases were created. The use of relations (tables), attributes (columns), tuples (rows), and, most importantly, transactions and ACID requirements made these databases very popular and they remain so now.
For example, we have the schema:

We can create and populate tables:
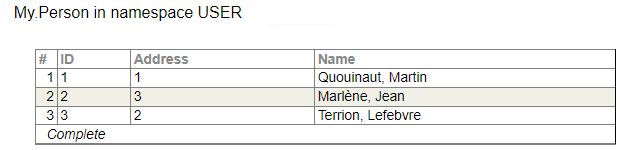
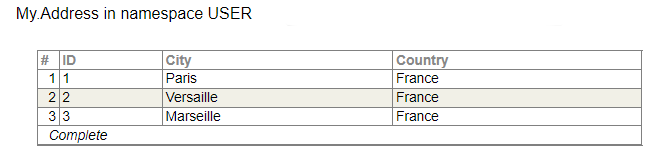
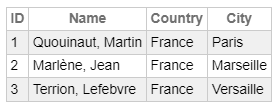
And if we write the query:
select p.ID, p.Name, a.Country, A.City
from My.Person p left join My.Address a
on p.Address = a.IDwe will receive the answer:
Despite the significant advantages of relational databases, with the spread of object languages, it became necessary to store object-oriented data in databases. That's why in the 1990s the first object-oriented and object-relational databases appeared. The latter were created on the basis of relational databases by adding add-ons to simulate the work with objects. The former were developed from scratch based on the recommendations of the OMG (Object Management Group) consortium and after ODMG (Object Data Management Group).
The key ideas of these object-oriented databases are the following.
The single data warehouse is accessible using:
- object definition language - schema definition, allows defining classes, their attributes, relations, and methods,
- object-query language - declarative, almost SQL-like language that allows getting objects from the database,
- object manipulation language - allows modification and saving data in the database, supports transactions and method calls.
This model allows obtaining data from databases using object-oriented languages.
If we take the same structure as in the previous example but in the object-oriented form, we will have the following classes:
Class My.Person Extends %Persistent
{
Property Name As %Name;
Property Address As My.Address;
}Class My.Address Extends %Persistent
{
Property Country;
Property City;
}And we can create the objects using the object-oriented language:
set address = ##class(My.Address).%New()
set address.Country = "France"
set address.City = "Marseille"
do address.%Save()
set person = ##class(My.Person).%New()
set person.Address = address
set person.Name = "Quouinaut, Martin"
do person.%Save()Unfortunately, object databases did not succeed in competing with relational databases from their dominant position, and as a result, many ORMs appeared.
In any case, with the spread of the Internet in the 2000s and the emergence of new requirements for data storage, other data models and DBMSs started to emerge. Two of these models that are used in IRIS are document and column models.
Document-oriented databases are used to manage semi-structured data. This is data that does not follow a fixed structure and carries the structure within it. Each unit of information in such a database is a simple pair: a key and a specific document. This document is formatted usually in JSON and contains the information. Since the database does not require a certain schema, it is also possible to integrate different types of documents in the same warehouse.
If we take the previous example again, we can have documents like these:
{
"Name":"Quouinaut, Martin",
"Address":{
"Country":"France",
"City":"Paris"
}
}
{
"Name":"Merlingue, Luke",
"Address":{
"Country":"France",
"City":"Nancy"
},
"Age":26
}These two documents with a different number of fields are stored in the IRIS database without any problem.
And the last example of a model that will be available in version 2022.2 is the column model. In this case, the DBMS stores the data tables per column and not per row.
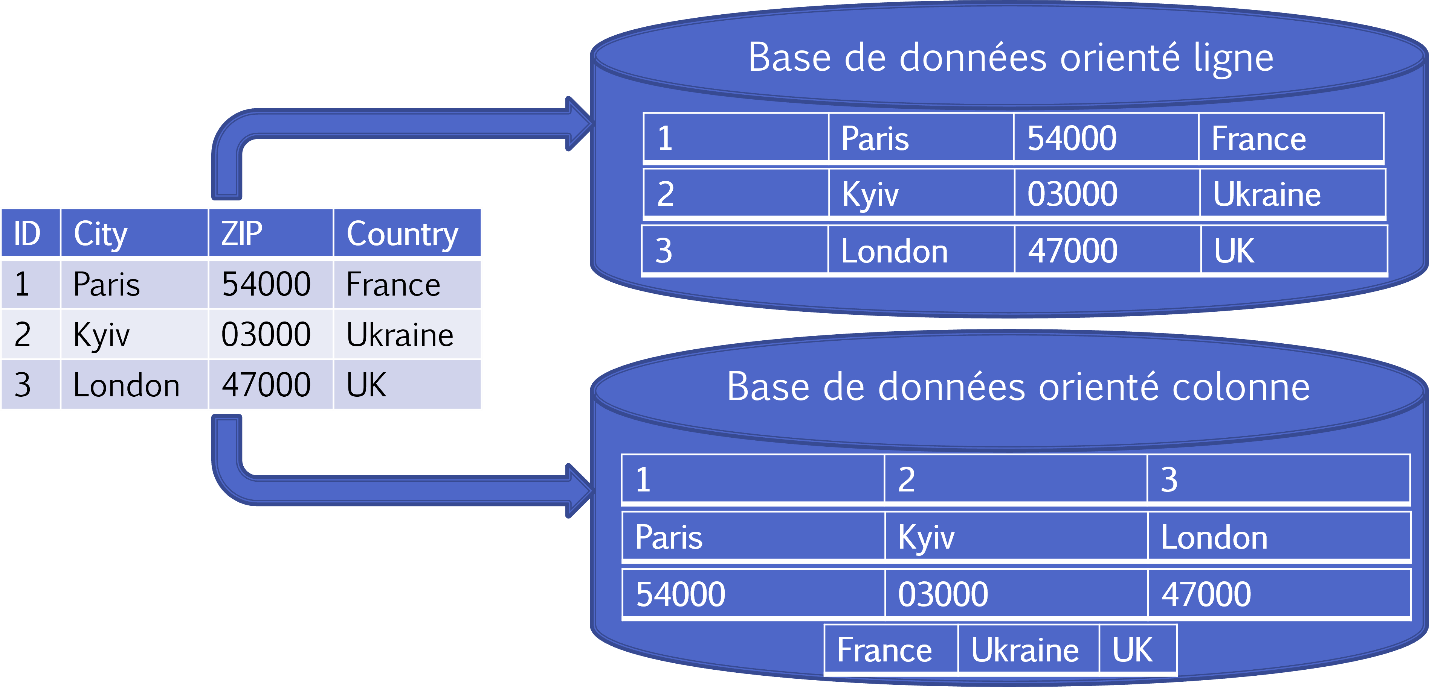
Column orientation allows more efficient access to data for querying a subset of columns (eliminating the need to read columns that are not relevant), and more options for data compression. Compression by column is also more efficient when the data in the column is similar. However, they are generally less efficient for inserting new data.
You can create this table:
Create Table My.Address (
city varchar(50),
zip varchar(5),
country varchar(15)
) WITH STORAGETYPE = COLUMNARIn this case, the class is like this:
Spoiler
Class My.Address Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {UnknownUser}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = Address ]
{
Property city As %Library.String(COLLATION = "EXACT", MAXLEN = 50) [ SqlColumnNumber = 2 ];
Property zip As %Library.String(COLLATION = "EXACT", MAXLEN = 5) [ SqlColumnNumber = 3 ];
Property country As %Library.String(COLLATION = "EXACT", MAXLEN = 15) [ SqlColumnNumber = 4 ];
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
/// Bitmap Extent Index auto-generated by DDL CREATE TABLE statement. Do not edit the SqlName of this index.
Index DDLBEIndex [ Extent, SqlName = "%%DDLBEIndex", Type = bitmap ];
Storage Default
{
<Data name="_CDM_city">
<Attribute>city</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V1</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_country">
<Attribute>country</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V2</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<Data name="_CDM_zip">
<Attribute>zip</Attribute>
<ColumnarGlobal>^q3AW.DZLd.1.V3</ColumnarGlobal>
<Structure>vector</Structure>
</Data>
<DataLocation>^q3AW.DZLd.1</DataLocation>
<ExtentLocation>^q3AW.DZLd</ExtentLocation>
<ExtentSize>3</ExtentSize>
<IdFunction>sequence</IdFunction>
<IdLocation>^q3AW.DZLd.1</IdLocation>
<Index name="DDLBEIndex">
<Location>^q3AW.DZLd.2</Location>
</Index>
<Index name="IDKEY">
<Location>^q3AW.DZLd.1</Location>
</Index>
<IndexLocation>^q3AW.DZLd.I</IndexLocation>
<Property name="%%ID">
<AverageFieldSize>3</AverageFieldSize>
<Selectivity>1</Selectivity>
</Property>
<Property name="city">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<Property name="country">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<Property name="zip">
<AverageFieldSize>7</AverageFieldSize>
<Selectivity>33.3333%</Selectivity>
</Property>
<SQLMap name="%%DDLBEIndex">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="IDKEY">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_city">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_country">
<BlockCount>-4</BlockCount>
</SQLMap>
<SQLMap name="_CDM_zip">
<BlockCount>-4</BlockCount>
</SQLMap>
<StreamLocation>^q3AW.DZLd.S</StreamLocation>
<Type>%Storage.Persistent</Type>
}
}
Then we insert the data:
insert into My.Address values ('London', '47000', 'UK')
insert into My.Address values ('Paris', '54000', 'France')
insert into My.Address values ('Kyiv', '03000', 'Ukraine')In the globals we see:

If we open the global with the city names, we will see :

And if we write a query:
select City
from My.Addresswe receive data:

In this case, the DBMS just reads a global to get the whole result. And it saves time and resources when reading.
So, we have talked about 5 different data models supported by the InterSystems IRIS database. These are the hierarchical, relational, object, document, and column models.
Hope you will find this article useful when trying to figure out which models are available. If you have any questions feel free to ask them in the comments.
Comments
Very nice article
Excellent article - thank you very much for taking the time to write this up!!!
💡 This article is considered as InterSystems Data Platform Best Practice.
Thanks @Iryna Mykhailova for this brilliant article !
Very clear and cleverly presented.
NB : for column-oriented storage specified at the table level via the statement WITH STORAGETYPE = COLUMNAR , it should be noted that IRIS leaves itself free to choose for you the most commonly optimal storage (in row or in column), according to the types of data.
Example :
the following statement :
CREATE TABLE a.addressV1 (
city varchar(50),
zip varchar(15),
country varchar(15)
)
WITH STORAGETYPE = COLUMNAR
Will not create any column-oriented storage, due to the risk of too disparate data, due to the number of characters allowed in each column (15 or 50) :
Class a.addressV1 Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {_SYSTEM}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = addressV1 ]
{
Property city As %Library.String(COLLATION = "EXACT", MAXLEN = 50, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 2 ];
Property zip As %Library.String(COLLATION = "EXACT", MAXLEN = 15, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 3 ];
Property country As %Library.String(COLLATION = "EXACT", MAXLEN = 15, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 4 ];
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;
while the example given in the article, retains a column (and only one) in column-oriented storage, since having only 5 characters allowed for the zip column.
CREATE TABLE a.addressV2 (
city varchar(50),
zip varchar(5),
country varchar(15)
)
WITH STORAGETYPE = COLUMNAR
Class a.addressV2 Extends %Persistent [ ClassType = persistent, DdlAllowed, Final, Owner = {_SYSTEM}, ProcedureBlock, SqlRowIdPrivate, SqlTableName = addressV2 ]
{
Property city As %Library.String(COLLATION = "EXACT", MAXLEN = 50, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 2 ];
Property zip As %Library.String(COLLATION = "EXACT", MAXLEN = 5) [ SqlColumnNumber = 3 ];
Property country As %Library.String(COLLATION = "EXACT", MAXLEN = 15, STORAGEDEFAULT = "ROW") [ SqlColumnNumber = 4 ];
Parameter STORAGEDEFAULT = "columnar";
Parameter USEEXTENTSET = 1;