New
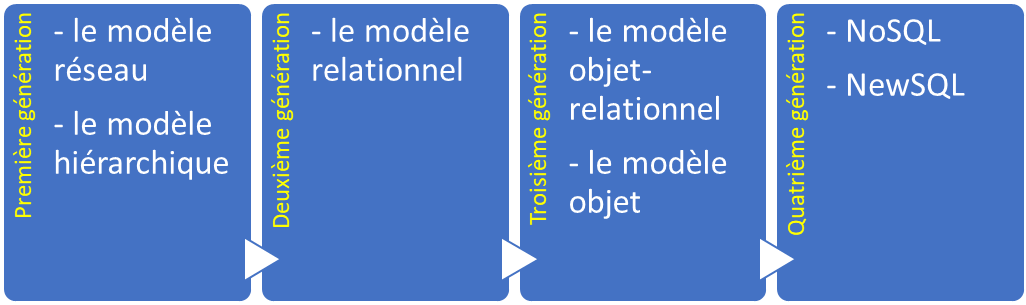
In the modern world, data is rarely uniform. Applications often require the structural rigidity of a relational database, the flexibility of a document store, and the performance of a high-speed key-value storage. Luckily, InterSystems IRIS solves this complexity by providing a single, unified engine that natively supports multiple distinct data models:
- Hierarchical
- Key-value
- Object
- Document (JSON)
- Relational
- Columnar
Crucially, all of these models access exactly the same physical data.

To illustrate this approach, let's examine all these data models using the same conceptual structure: The Record of Patient P101 (John Doe).

 .
.