The current version of SAM creates Prometheus metric endpoints which appear to be handled correctly by the current prometheus scraper, however the metrics do not confirm to the current prometheus standard. The standard states:
Has anyone done any kind of integration with Dynatrace, which is a JVM transaction monitoring tool? Our organization uses this extensively with our Java and .Net applications and we wanted to know if it is even possible.
InterSystems IRIS Business Intelligence provides the Cube Registry as an interface for managing and scheduling build and synchronize tasks for your cubes.
We have multiple implementations spanning many namespaces and edges. I would like to see if I could identify a single place, perhaps on HSREGISTRY or HSBUS, that I could capture certain events like searches (from all customers) and record transfers (with requester and provider).
The goal is to have a dashboard that would show simple stats such as searches by participant, records shared by participant and records consumed by participant. These are the 3 most important.
I appreciated the feedback on the other question of "how" but now I'm hoping to find the "Where".
I installed a community version of Intersystems IRIS in a Large AWS EC2 instance to do some testing. I installed SAM and when I try to "Add a new cluster" I receive the following: "ERROR #5005: Cannot open file '/config/prometheus/isc_tmp_yml_file.yml'"
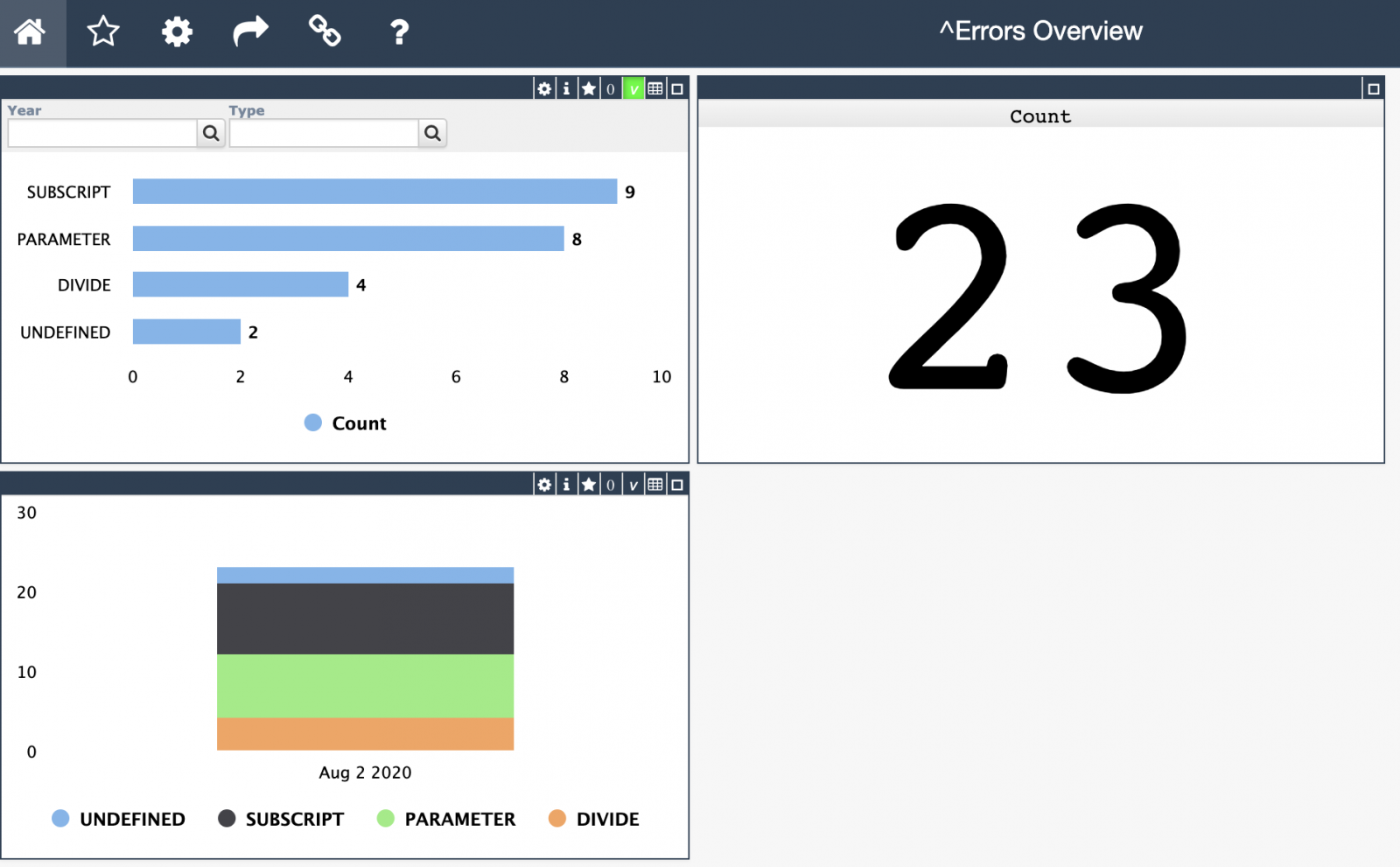
I recently discovered the Monitoring Activity Volume feature in IRIS and I was amazed by it. So, I put it to work in one of our productions. It is nice how easy it is to set up and all the possibilites that came with it.
But there's something weird: the numbers. Actually, one of the BP is stating a time of more than 6 seconds to process:
I want to create a dashboard with a line graph that shows system availability over time. I used this code to create a Dashboard:
Set tItem = ##class(%DeepSee.UserLibrary.Link).%New()
Set tItem.fullName = "Availability"
Set tPage = "Availability.UI.CSVImport.zen"
Set tItem.href = $system.CSP.GetPortalApp($namespace,tPage)_tPage
Set tItem.title = "Availability"
Set tSC = tItem.%Save()
My group needs to be able to monitor items / tasks, and let a non-management-portal user see the monitoring. Is it possible to run DeepSee queries on Production items? I feel like I should not be recreating the production environment or the task manager just so that I can query on the items that are running, and on their states (like "successful" or "send email").
Also, I need to log custom events for each task, and I'm running into difficulties with the task manager in this regard; hence the question about using the Production instead, but querying it.
after updating from 2018.2.1 to 2021.1 we observe a change in the behaviour of the Messagebank Enterprise Monitor.
In 2018.2.1, when clicking on a specific line inside the configured systems the system dashboard opened, giving insights about queue counts and error conditions.
https://www.youtube.com/embed/EYLHIEAxHLk [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
https://www.youtube.com/embed/XtXzvN3Gqgw [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
Our first Online Developer Roundtable of 2024 will take place on March 5th at 9 am ET | 3 pm CET.
Tech talks:
ObjectScript Unit Testing Tools, Techniques and Best Practices - by @Timothy Leavitt , Development Manager, Application Services, InterSystems
Monitoring and Alerting Capabilities of InterSystems IRIS - by @Mark Bolinsky, Principal Technology Architect, InterSystems Mark's presentation is rescheduled for the roundtable in April.
▶ Update: watch the recording of the roundtable below:
https://www.youtube.com/embed/mIAMvaCHlk8 [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
With more and more hospital applications built, business interface data processing may be affected by a variety of factors (network, consumer systems, etc.), there is an excessive accumulation of messages or even cause interface lag, affecting the routine performance of hospital IT systems , so the monitoring of the business interface components queue is increasingly important.
While current Intersystems IRIS platform's built-in queue monitoring only displays real-time queue information for interface components, which is limited in providing the queue data information needed by hospitals. The queue monitoring component program is based on the Intersystems IRIS platform and can monitor all interface components and display component queue information within 24h of the component, as well as query component historical queue data by setting a time period to better meet the needs of current in-hospital applications.
In response to the infrastructure needs of our company's service, I've created a small API that sends SNMP queries to InterSystems to visualize relevant data for retrieval when the infrastructure implements monitoring.
However, I'm experiencing a timeout issue when attempting to collect information using an SNMP walk. Here is the code for my API's SNMP service:
https://www.youtube.com/embed/T_RK5QzRZ0Q [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
I believe most of you have encounted this problem: a healthconnect/ensemble user get a slow response and ask measurement on how long it takes ensmeble to process this request, the ensemble 'activity data' gives no clue of the delay.
The reason is HealthConnect message measurement was based on ensemble message, which can’t give a correct answer on when ensmeble recevie the request and what time it send back response. when there is delay on inbound/outbound adpter, or csp gateway, there is no way to find out the delay from "activity data" .
Presenter: Kerry Kirkham Task: Prevent application-to-application interface problems from escalating Approach: Give examples of using alerts to get the right person working on a problem as soon as possible
Problems with application-to-application interfaces are inevitable but in most cases they can be fixed with little disruption as long as the right person gets to know about it as soon as possible. But delays in attention cause problems to escalate, pressure mounts and business suffers. This session looks at how monitoring and alerting can be set up to recognize problems and get the right person working on the problem in the shortest possible time so that small problems don’t turn into major issues.
Solution: Using alerts to minimize interface problems
Content related to this session, including slides, video and additional learning content can be found here.
I've setup ODBC connection so I can access Cache data within SQL Server.
I want to be able to write SQL queries for internal monitoring purposes, similar to what's possible with SQL Server. Specifically I want to be able to check mirroring status (i.e. check which is the current primary mirror member), check the status of any Ensemble productions (started/stopped), check the status of business hosts etc. I want to do all of this from SQL Server to go with our other system monitoring solutions.
Alerts are messages generated by production components. InterSystems IRIS automatically writes the alerts to a log file and sends then to the production component named Ens.Alert. If your production does not have a component named Ens.Alert, then InterSystems IRIS writes alerts to the log file but does not send them to any component. The component named Ens.Alert can be of any class. The most frequently used classes for Ens.Alert are:
 By views
By views Open Exchange app
Open Exchange app.png)