By views
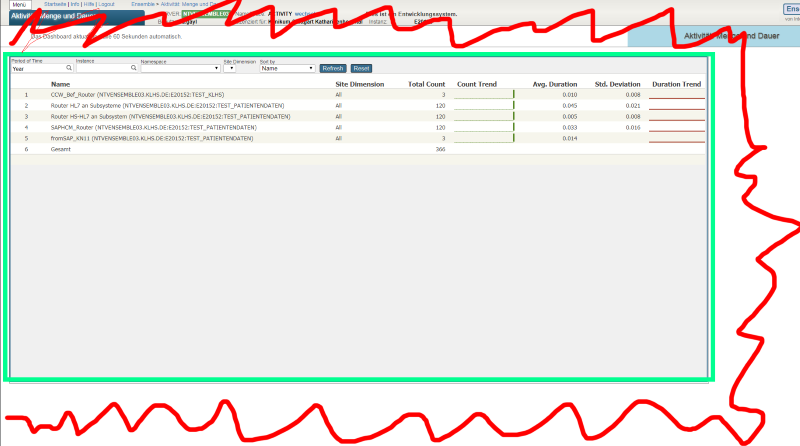
By viewsCan Cache Monitor (^MONMGR) and System Monitor be configured to also send 'OK' messages? With the first bad email, you still wonder if things are still broken, when in-fact normalcy has been restored, some even within some seconds.
typical examples : -
------ - - - -- - - - -- - -- --- - -- -- -- - - - -- -- -- - --- - - - -- - - -- - - -- --- - - -- -- -- - - --- - - - - --- -- --- - - -- -- --- - - --- - --- -- - - -- -
Sent: Monday, 14 November 2016 11:51 AM
To: Email
.png)