 By replies
By repliesHi Developers,
In the previous article, we describe how to use config-api to configure IRIS.
Now, let's try to combine the library with the ZPM client.
The goal is to load a configuration document during zpm install at the configure phase.
For this exercise, a template repository is available here (this is based on objectscript-docker-template ).
 Open Exchange app
Open Exchange app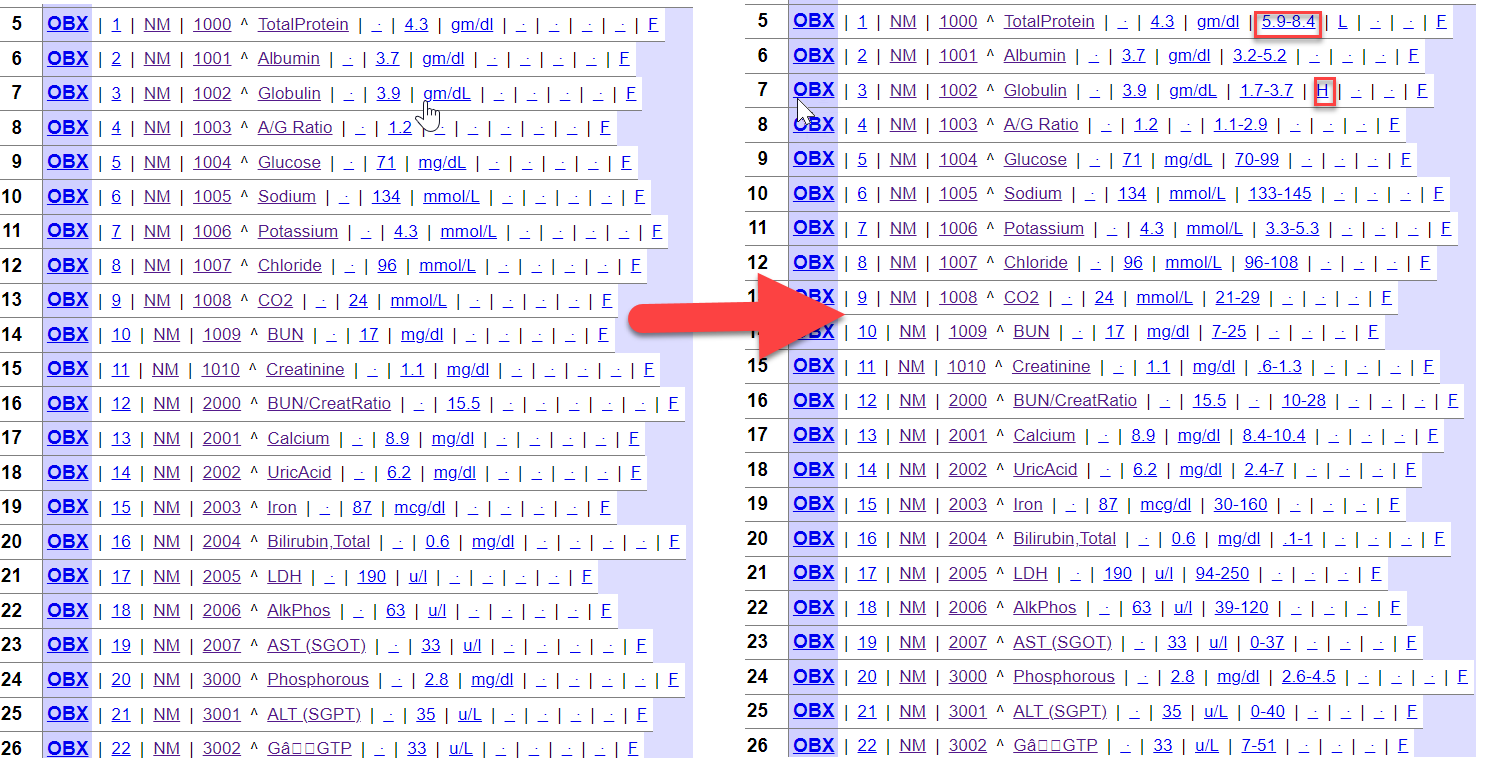
.png)