 By replies
By replies Open Exchange app
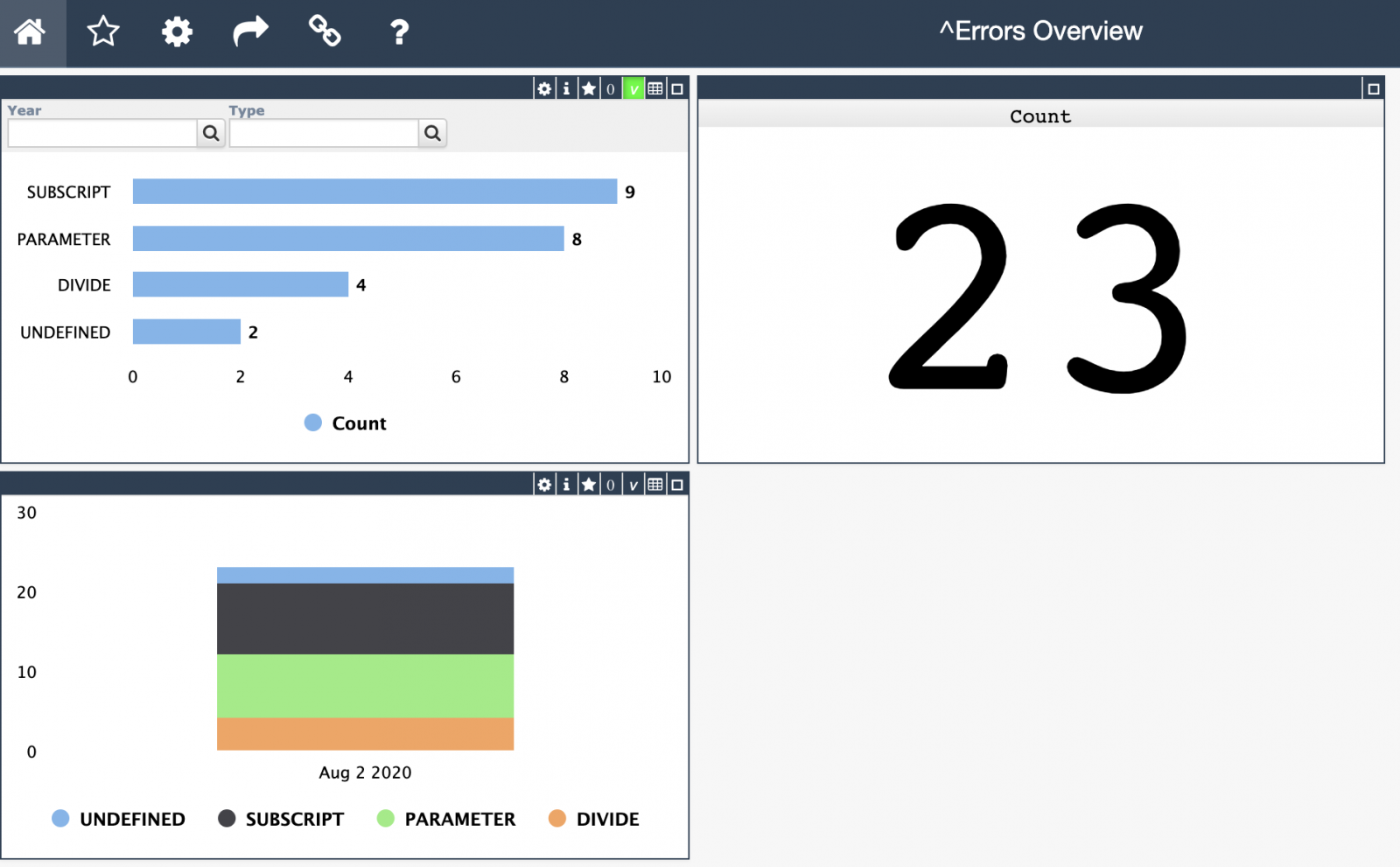
Open Exchange app> Customizable System Monitoring. ## Introduction The Polymetric Dashboard is a stand-alone module that provides enhanced monitoring tools for a Caché environment. Equipped with over one hundred sensors that monitor key system metrics, a robust REST API, and a modular AngularJS user interface, the Polymetric Dashboard is fully functional out of the box. However, the Polymetric Dashboard is designed to be customizable; any system metric can be monitored by creating a new sensor, and the visualization of collected data can be tailored to specific requirements and purposes.
.png)
.png)