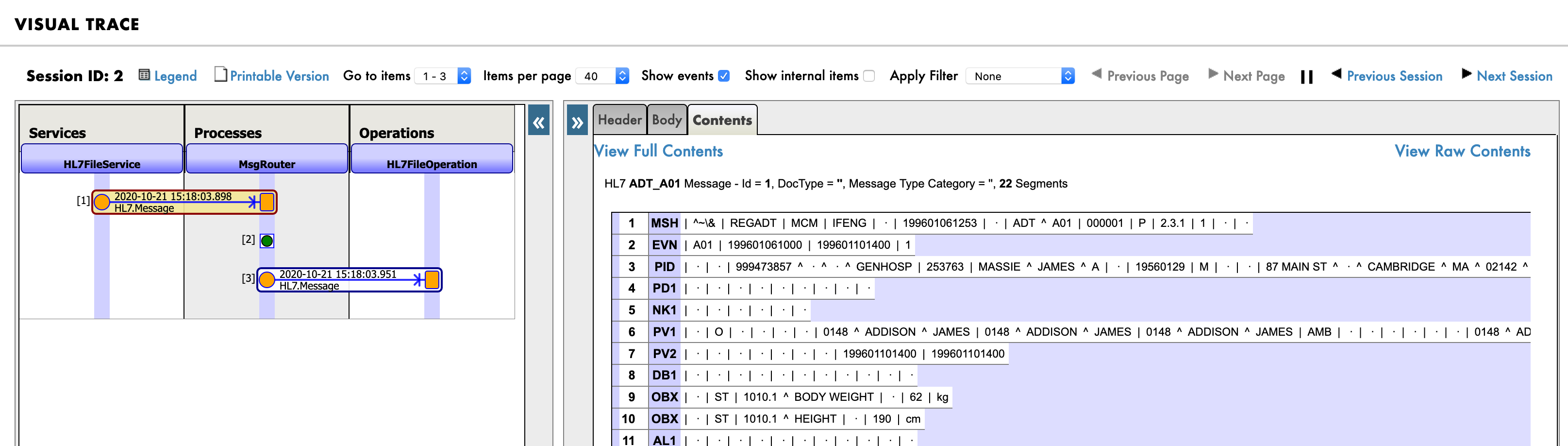
This code snippet determines the day of the week associated with a date. The class method "test" takes a date as a string in "mm/dd/yyyy" format, and returns an integer corresponding to a day of the week:
Class cartertiernan.getDayfromDate Extends %RegisteredObject
{
classmethod test(date) as %Integer {
//Set date = $ZDATE(date) // Looks like: mm/dd/yyyy
Set monthList = $LISTBUILD(0,3,3,6,1,4,6,2,5,0,3,5) // (Jan,Feb,Mar,Apr,...)
Set centuryList = $LISTBUILD(6,4,2,0) // first two digits divisiable by 4, then subsequent centuries. EX (2000, 2100, 2200, 2300)
Set dayList = $LISTBUILD("Sunday","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday") // Index goes from 0-6
Set day = $PIECE(date,"/",2) // get the day
Set monthVal = $LIST(monthList,($PIECE( date,"/",1 ))) // get the month value
Set first2DigsYear = $PIECE( date,"/",3 ) \ 100 // get the last 2 digits of the year
Set last2DigsYear = $PIECE( date,"/",3 ) # 100 // get the first 2 digits of the year
// Used for DEBUG perpouses
/*write !,"day: ",day
write !,"Month: ",monthVal
write !,"last2: ",last2DigsYear
write !,"first2: ",first2DigsYear
write !,"cen Val: ",$LIST(centuryList,(first2DigsYear # 4) + 1),!!*/
// Look here for formula explination (its the "Basic method for mental calculation")
// http://en.wikipedia.org/wiki/Determination_of_the_day_of_the_week
Set dayOfWeekVal = ( day + monthVal + last2DigsYear + (last2DigsYear\4) + $LIST(centuryList,(first2DigsYear # 4) + 1 ) ) # 7
Quit dayOfWeekVal
}
}
Here's a link to the code on GitHub
(originally posted to CODE by Carter Tiernan, 6/18/14)
 By replies
By replies
 Open Exchange app
Open Exchange app
 (*)
(*).png)

 Beginning -
Beginning -