Hands Off HealthShare Deployment Workflow with Gitlab Runners
Deploying InterSystems HealthShare code, supporting lookups and artifacts like ssl certs, keys etc is relatively straight forward using Gitlab Runners. Not only does this approach enable managing the code base and deploying with git type workflows, but it also lends to a speedy recovery and repeatable environments for some implementations.
For those of you with HealthShare specific experience, I think we could agree that is an oversimplification of the process with all the moving actors of a HealthShare implementation, but this does provide some insight on how to get things deployed with a simplistic example.
For this example, lets paint the picture of what the minimal deployment actually looks like, then demo the code promotion.
HealthShare
We have, two seperate HealthShare environments/servers in their own demarcation zone (VPC). Each is fairly identical, running 3 instances on each, ESB (HealthConnect), CV (Clinical Viewer) and UCR (Universal Care Record).
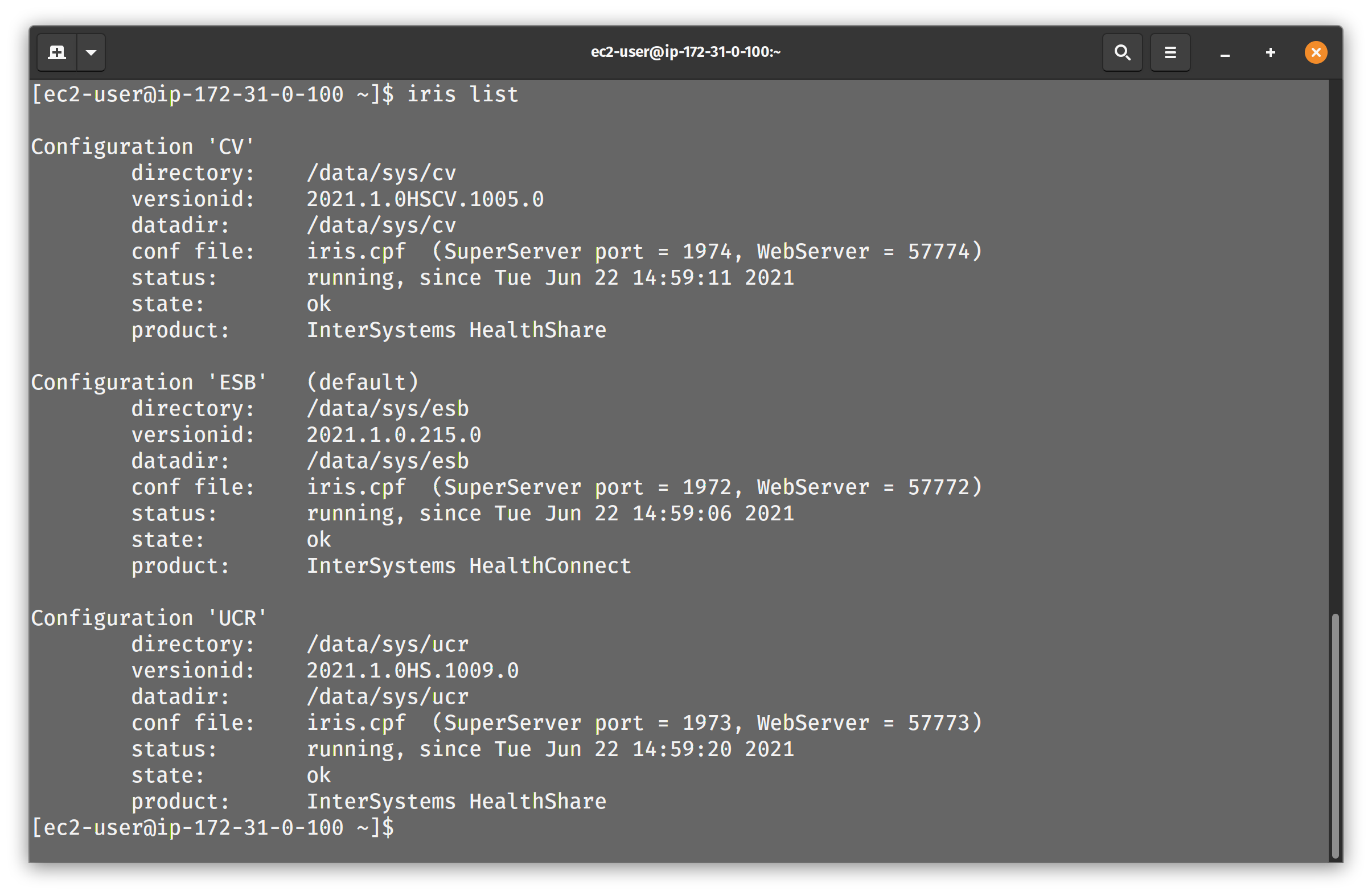
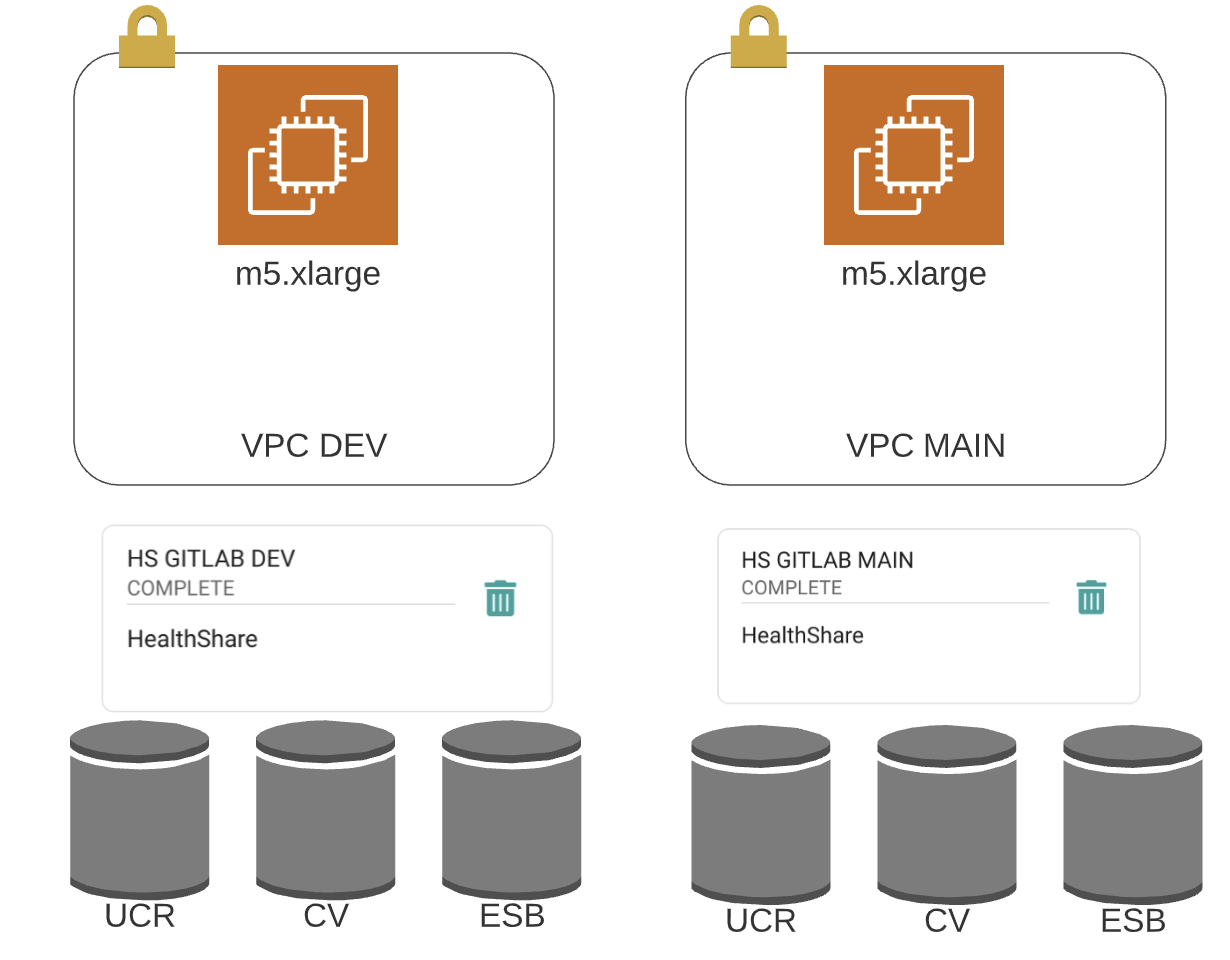 For the population of folks that can benefit from showing the running order of the instances on the back end of each of the servers, it looks like this:
For the population of folks that can benefit from showing the running order of the instances on the back end of each of the servers, it looks like this:
 With the Two HealthShare boxes and spinning, we delegate one of them to DEV and one of them to LIVE, and label them as such.
With the Two HealthShare boxes and spinning, we delegate one of them to DEV and one of them to LIVE, and label them as such.
Gitlab
This sets us up to create in Gitlab:
- 1 Gitlab repository
- 2 Branches, dev and main
- 2 Project specific runners, one tagged "dev" and the other tagged "main" and installed on their perspective servers.
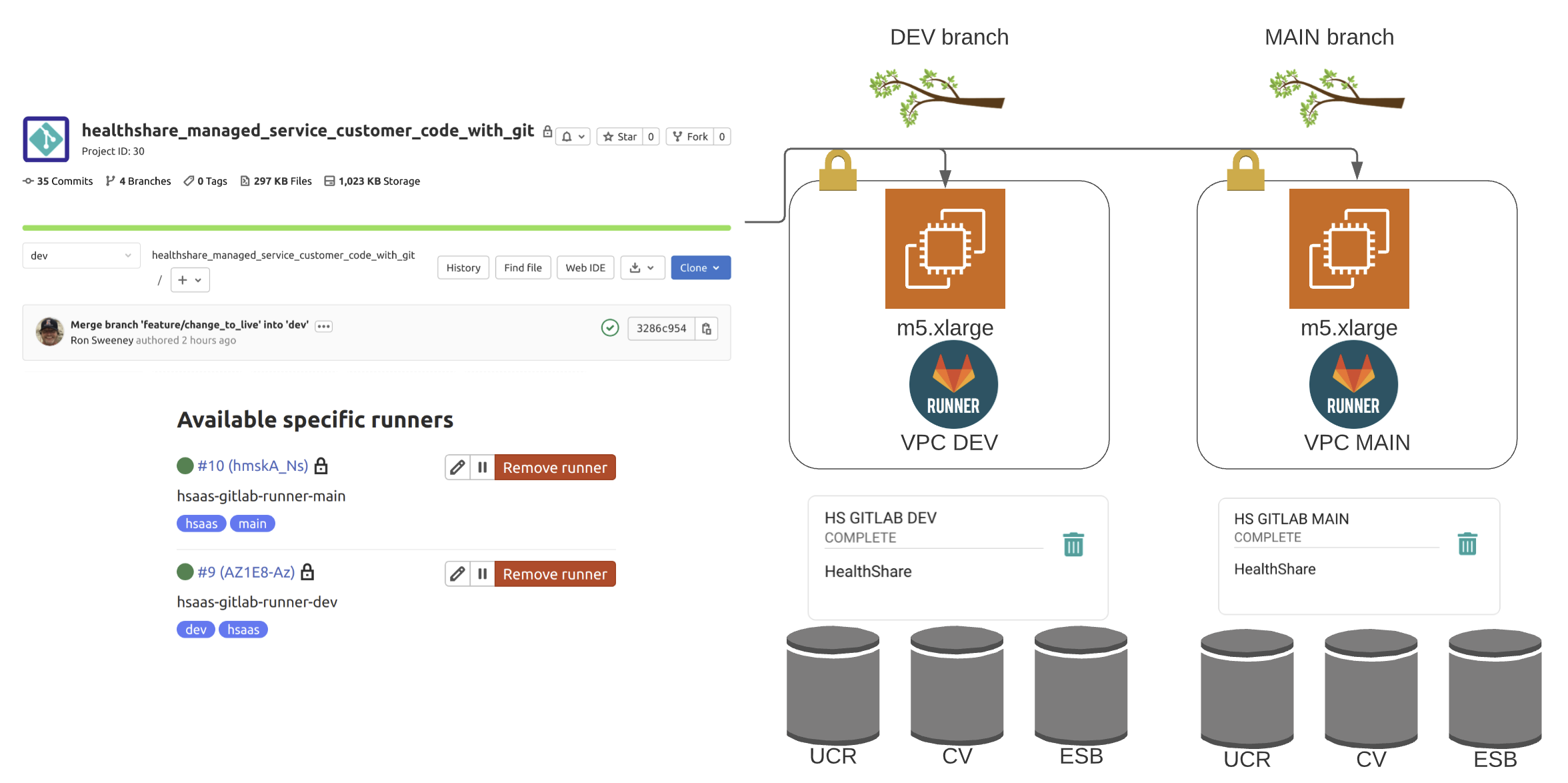
The idea here is that we are setting up our runners to execute deployment actions on merges to "dev" where we can iterate on the DEV branch/DEV environment and the after testing is complete, we can merge to "main" in a process, with the ultimate goal of a Hands Off! deployment to Production where humans make mistakes.
Hands Off Live Environment Demo
Pipeline Code
The pipeline code in the demo is available as a gist here. You can see below that the example has two stages, one for dev and one for main, that are exclusively locked to branches. The main point I am trying to drive home with this pipeline is you can pretty much remotely control the implementation of your HealthShare completely through code through the use of Installers, or just by importing and having the ability to run cos and or operating system commands using the gitlab runner.
Spoiler
variables:
GIT_CLONE_PATH: "/home/sween/builds/src"
GIT_STRATEGY: clone deploy hsaas_dev:
stage: deploy
tags:
- dev
script:
- echo "Initializing hsaas CI/CD Build DEV..."
- git checkout dev
- git reset --hard FETCH_HEAD
- git clean -df
- echo "Importing Code into DEV..."
- |
/usr/bin/irissession ESB <<EOFESBSETUP
irissys
password
zn "CUSTOMER"
w ##class(%SYSTEM.OBJ).LoadDir("/home/sween/builds/src/customer/cls/ESB","ck",,1)
EOFESBSETUP
- echo "Running System Commands DEV..."
- sudo cp /etc/hosts /tmp/
- echo "Running Supporting COS Commands DEV..."
- |
/usr/bin/irissession ESB <<EOFESBCOMMAND
irissys
password
zn "CUSTOMER"
set sc = ##class(Ens.Director).UpdateProduction()
EOFESBCOMMAND
- |
/usr/bin/irissession CV <<EOFCVSETUP
irissys
password
zn "HSLIB"
w ##class(%SYSTEM.OBJ).LoadDir("/home/sween/builds/src/customer/cls/CV","ck",,1)
EOFCVSETUP
- |
/usr/bin/irissession UCR <<EOFUCRSETUP
irissys
password
zn "HSLIB"
w ##class(%SYSTEM.OBJ).LoadDir("/home/sween/builds/src/customer/cls/UCR","ck",,1)
EOFUCRSETUP
only:
- dev
deploy hsaas_main:
stage: deploy
tags:
- main
script:
- git checkout main
- git reset --hard FETCH_HEAD
- git clean -df
- echo "Importing Code into LIVE..."
- |
/usr/bin/irissession ESB <<EOFESBSETUP
irissys
password
zn "CUSTOMER"
w ##class(%SYSTEM.OBJ).LoadDir("/home/sween/builds/src/customer/cls/ESB","ck",,1)
EOFESBSETUP
- echo "Running System Commands LIVE..."
- sudo cp /etc/hosts /tmp/
- echo "Running Supporting COS Commands LIVE..."
- |
/usr/bin/irissession ESB <<EOFESBCOMMAND
irissys
password
zn "CUSTOMER"
set sc = ##class(Ens.Director).UpdateProduction()
EOFESBCOMMAND
- |
/usr/bin/irissession CV <<EOFCVSETUP
irissys
password
zn "HSLIB"
w ##class(%SYSTEM.OBJ).LoadDir("/home/sween/builds/src/customer/cls/CV","ck",,1)
EOFCVSETUP
- |
/usr/bin/irissession UCR <<EOFUCRSETUP
irissys
password
zn "HSLIB"
w ##class(%SYSTEM.OBJ).LoadDir("/home/sween/builds/src/customer/cls/UCR","ck",,1)
EOFUCRSETUP
only:
- main Comments
@sween - this is really great, thank you!
My team at InterSystems is actually working on a project to move diff-based code changes between environments using GitLab. My question for you is whether you have a suggestion for a strategy for only importing the changed files in the target environment? As you know, applications can get large and complex and build-times can get pretty long. If only a handful of files have changed, reimporting the entire application (or in the case of your example, 3 applications) would cause excess and unnecessary downtime for users. What we have been doing with CCR around the world at HealthShare and TrakCare sites for over a decade is executing targeted imports which only reload changed code. Is there a Git-based strategy that you can recommend for building out the foundation of doing something similar? I.e. isolating the files impacted by the merge and only pulling those in?
Thanks for any thoughts on this.
(note: @Timothy Leavitt )