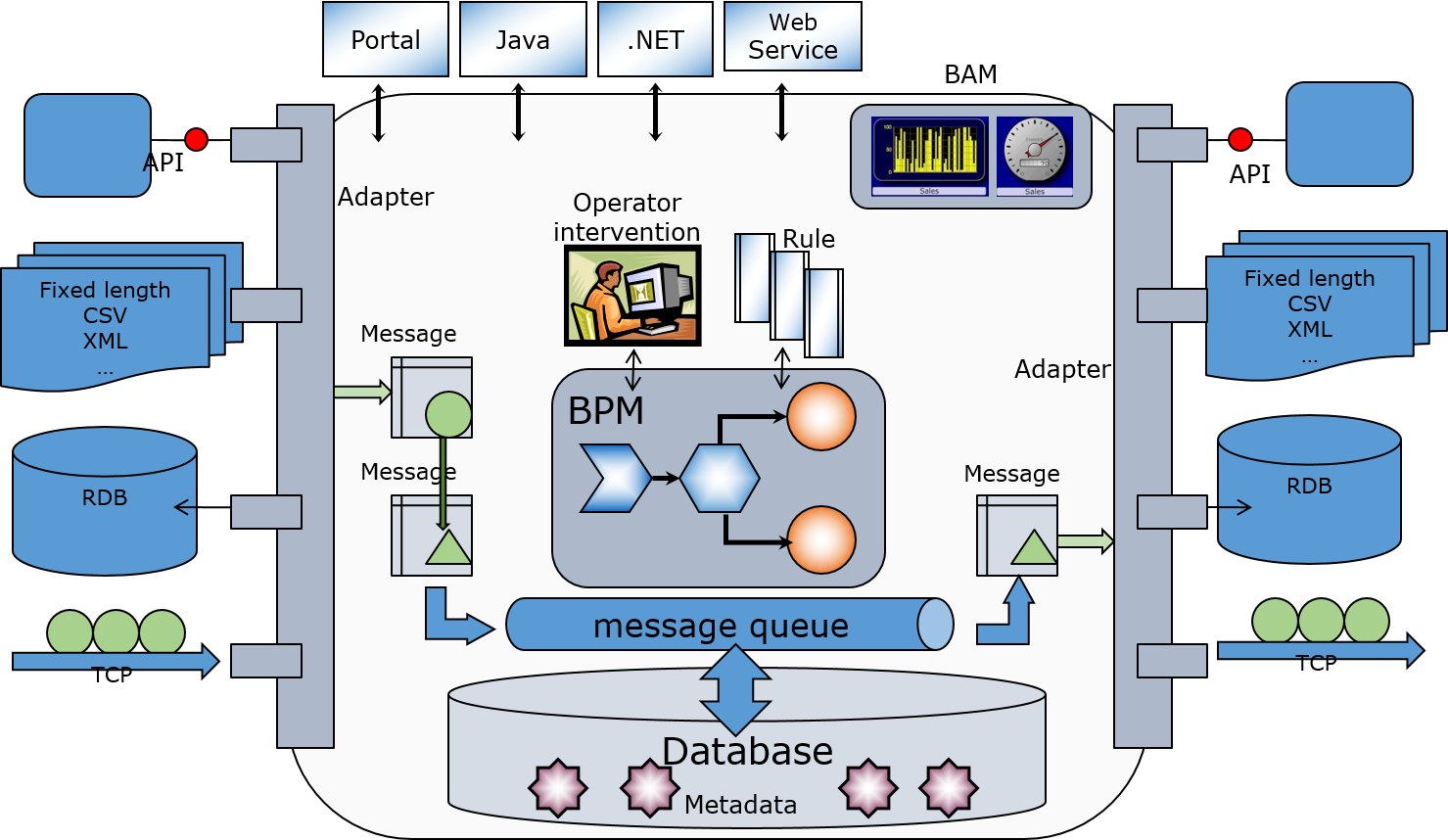
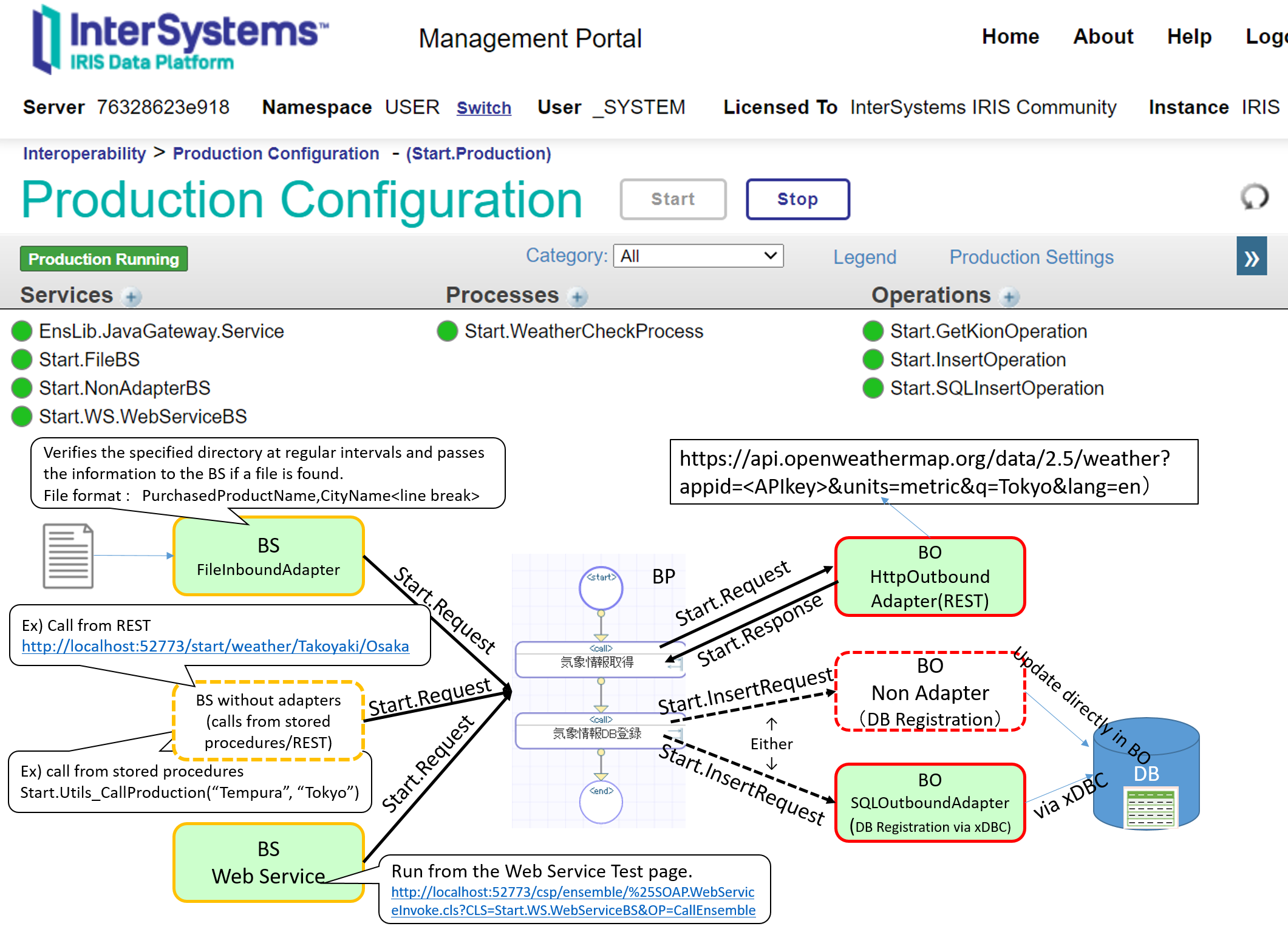
Hi all, I am new to IS Objectscript and I would appreciate some assistance regarding this.
I am trying to find out how to count the number of elements within a dynamic abstract object and I am having some trouble using the size method.
Here is the code below:
The key value pairs are originally in JSON and I would have converted it in to an object for use.
Class JSON.Test {
ClassMethod Test()
{
set obj = {"byr:":"1937", "iyr:":"2017", "eyr:":"2020", "hgt:":"183cm", "hcl:":"#FFFFFD","ecl:":"grey", "pid:":"028048884"}
set passport1 = {"ecl:":"grey","pid:":"860033327", "eyr:":"2020","hcl:":"#FFFFFD","byr:":"1937", "iyr:":"2017", "cid:":"147", "hgt:":"183cm" }
do ..FirstPassport(passport1)
}
ClassMethod FirstPassport(passport1 As %DynamicObject, property = "")
{
write !
set iterator = passport1.%GetIterator()
write "Number of properties: "
set property = _passport1.%Size
// I would like to be able to save the above mentioned property as an value and use this as a condition to determine if the property is 8 then write the key value on to the screen.
while iterator.%GetNext(.key, .value) {
write key_value, !
}
write !
}
}