What do you prefer use abbreviation or normal commands?
Hello Everyone,
I'm want to know, what is more common for your company to use, the abbreviation syntax or the complety name of commands, and why?
Ex.
S VAR=10 / D FUNC^ROUTINE F 1:1:1000
Set VAR=10 / Do Func^Routine / For 1:1:1000
set var=10 / do func^routine / for 1:1:1000
Here in my company, we are familiar with the abbreviation syntax, because to spell is more faster.
Comments
Don't even try to write code like this
Q N R,Q,C,D,E,W,B,G,H,S,T,U,V,F,L,P,N,J,A S N=$G(N),Q='N,F=Q+Q,P=F+F,W=$L($T(Q))
S W=$E(W,Q),S='N_+N,W=W-F*S,L=$G(L),R=$C(Q_F_P),R(F)=$C(F+Q_F),R(P)=$C(W-F) W #
S T=$E($T(Q+F),F,W\S)_$C(W+S+F) X T S B=$P(T,$C(P_P),F),C=B\(W*W),D=B-(C*W*W)\W
F G=S-Q:F:S+F+Q S E=B-(C*W*W+(D*W)),H=$E($T(Q),G),@H=$S(@H<S:'Q,Q:N)_@H,T=C_D_E
F A=Q:Q:W\S S J=$E(T,A),C(F)=$S(J>(F+Q)&(J<(S-F)):Q,Q:+N),C(P)=$S(J#F:Q,Q:+N) D
.S C(Q)=$S(J<(S-F):+N,Q:Q),C(F+Q)=$S(J>Q&(J<(S-F))&(J'=(P+'L))&(J'=(P)):Q,Q:+N)
.S H('L)=L F S H(N?.E)=$O(C(H('$G(N)))) Q:H('+L)=L S F(A,H('L))=C(H(W[(W\S)))
F U=Q:Q:P W !,R F V=Q:Q:P+F W $S(F(V,U):'Q,Q:$C(P_(W\S))) W:'(V#F) $C('N_F_F+F)
W !!,R(F)_C_R(P)_D_R(P)_E_R(F) X $RE($E($T(Q),Q+F,P+Q))_R(P)_'N W # G:N=L Q+F QFor sure full commands and functions more readable. Not only for your current developers but for any who will come later.
This is evil. I love it ![]()
Definately would always recommend full commands. I remember the day when we had to write code this way however it isn't the case anymore.
That said, it's good to be able to read code like this because it still exists out there.
This is a really good point I hadn't considered.
When I was working with legacy code bases, it was difficult. However, perhaps I'm blaming the wrong culprit. Looking back, the main issue is that all the variable names were two random letters (at least to me; by the end I could usually figure out what the two letters were supposed to mean). I'd be down 15 lines and then have to go back up to a variable's initialization to remember what the heck "cb", "sh", or "ac" actually were, semantically.
That was probably also done to save characters, and, as you said, is far more damaging than set -> s or if -> i.
I also agree that the lack of appropriate spacing makes a huge difference, as appropriate spacing can help show the control flow of the code. Thanks for commenting this; after reading it, I now think that of all the questionable (in today's world) space saving techniques used in the past, the single letter variable names might be the least offensive.
That said though, with respect to the seeing more at once, s -> set doesn't increase the vertical space at all, so in theory you can see the same number of lines. Also, I think it's very useful for coding languages to be written in English. Coding is complex enough as it is, so we might as well take advantage of the fact that we're already completely comfortable with English, and thus we don't need to waste any mental resources during the processing of English string -> semantic meaning. By using English, we're hijacking our preconceived notions of words like "while" such that the jump to the more complex control flow operator is less severe. I'd contend it would take far longer than a few hours to be able to really read "w" the way you can read "while".
It's just like learning a new (non-coding) language. Once I know what the vocabulary words mean, I can competently translate a passage in that language. But I can't read it yet, with a direct link from the text to the meaning.
1. Faster to type (as you said).
Every developer should think not only about himself but about the next developer, who will have to read his code. You can type it faster when you use IntelliSense, like in any modern IDE. Like we already have it with VSCode-ObjectScript. It now supports extending commands and functions, and I see the near future when it will be able to extend any old-school code, with dots, or inline do.
More compact. Allowing the reader to "see" more of the structure in one go.
So, you say that this very compact code, is readable because you can see all code at once? No, no, no, it makes the code completely unreadable. When you put many commands in one line, with one or even more F and D it makes so much pain, to understand what's going on there. And it very fast becomes like a black box, nobody understands how it works, and nobody wants to touch it, just to not break it completely.
@Dmitry Maslennikov, you say VSCode has ObjectScript beautifier? Could you please demo the feature?
Honestly, the beautifier is not as functional as I wanted, yet. But you can look at some demo in the latest release notes here in the chapter about Formatting.
This should have been the accepted answer. :) It is more important for code to be easy to read than for it to be easy to write.
I find myself agreeing with Mike W on this one in being generally in favor of (some) abbreviations, though I can certainly understand the "fully written out = easier to read (and thus maintain) code" argument.
I should also add: I have found I apply abbreviations inconsistently (Much to my internal engineer's chagrin)
s/set is an easy one and as mentioned, quickly becomes comfortable. I also tend to use d/do.
However, for control-flow items (for/if/while) i find myself always writing these out. After reading John's subcomment above, I wonder if indeed this could be related to the larger "semantic gap" that develops in (for example) parsing "f" vs "for" / "i" vs "if" - it is harder for NLP english brain to quickly internalize the true meaning.
One additional point touched on: preserving spacing. Abbreviations won't usually save vertical space, but I would contend that sometimes horizontal space (which they do save) is a premium as well. Lines running offscreen can be annoyance at best, but at worst can cause a programmer to misparse or even completely miss sections of code. For this reason, I will usually try to break long lines (ie, a long concatted string) over multiple lines with an indented "_". Abbreviating saves hspace as well - albeit moreso $ objs functions than commands.
Speaking of which... Wasn't asked by OP, but similarly for objs functions: I will almost always use $P over $Piece, $S over $Select (but not $C for $CASE ![]() ). I can understand rationale for spelling these out but as these (especially some $S) expressions can get complex, I find abbreviating the func itself helps keep focus on the expression logic itself. Sometimes an extra space between parens can go a long way towards maximizing this clarity. Oh, and $ZDT >> $ZDATETIME any day :) Similarly, would anyone actually ever write $HOROLOG over $H ?
). I can understand rationale for spelling these out but as these (especially some $S) expressions can get complex, I find abbreviating the func itself helps keep focus on the expression logic itself. Sometimes an extra space between parens can go a long way towards maximizing this clarity. Oh, and $ZDT >> $ZDATETIME any day :) Similarly, would anyone actually ever write $HOROLOG over $H ?
In a similar, related vein of "cautionary M tales" - found this lovely gem crawling some forums last year (from a much older post from the days where the Cache tech stack was perhaps a bit less mature) :
"The following is a valid line of MUMPS code:
A B:C D E F G=H:I:J K:L M N O,P Q:R S T=UVW X YZ
It means "Line is labelled A. Breakpoint if C is true. Do the E subroutine. For G=H to J, incrementing by I. If L is true, kill (unset) the M variable. Create new variables O and P. If R is true, quit. Set the T variable = the UVW variable. Execute the contents of the YZ variable as if it contains valid MUMPS code." I remember showing some code to a college friend when I'd been working with it for a few months, and he asked why my printer was spewing line noise."
From <https://what.thedailywtf.com/topic/508/intersystems-cach-233-gateway-to-hell/21>
"cautionary M tales" is really ages old and outdated.
But see it from reverse side: You can run without any change code that was written 40 years ago on PDP-11
I've seen it and can confirm it.
I know of no other system that allows spanning that range of time without touching the code.
But you are not forced to write that style. Or you can even write your code in BASIC if you dislike COS.
I am in the same position as you, only selectively using full commands or function names, being too much in the habit of MUMPs abbrevations. Like you though I tend to extend when iterating or using something less usual in the code, I have also found curly braces to be much better for readability than the old block structure.
I also agree that I find it faster to read and write abbrevated code for things like sets and do's and especially for functions such as $p and $g. Hopefully I can get into the habit of less abreviation as I do notice the new programmers finding this harder.
Probably the biggest habit I have broken is also shown in the bad examples given and shows how long I have been using MUMPS, yes it's entering everything in UPPERCASE. I finally use camel case and also more meaningful/longer routine and variable names.
That makes a lot of sense that you naturally avoid the abbreviations where the English word carries some significant meaning. Also, it seems like you naturally avoid abbreviations where the abbreviation carries a sort of misleading semantic meaning. With $case vs $c, $c at first glance looks like some sort of character function, whereas $s and $H don't immediately appear to be something that they're not.
And I forgot about horizontal space; on lines that get long it's not trivial. That said, things like $select, $HOROLOG, and $piece carry a lot of meaning through the full word, and I think there's value in that.
Side note: for some reason I always want to use $g instead of $get (I don't, but it feels natural). I think that's because, as a single syllable word which is a very simple operation, after seeing the definition for $get once, $g seems to fit it just as well as the full "get".
Please keep in mind, that W means write and not while.
@hans was a typo, thanks for the catch; i have corrected it. ;)
I think full commands are much easier to read for those that might be coming into your organization and will be taking over development of your projects in the future.
It's pretty easy to convert from one to the other using the Expand and Compress commands option in Studio.
For those that might be visually impaired, it would be a lot easier to dictate expanded commands than abbreviated versions.
Just my 2 cents
It's pretty easy to convert from one to the other using the Expand and Compress commands option in Studio.
Or Alt+Shift+F in VSCode-ObjectScript
Thank you
Simply select the code to convert and then select Edit -> Advanced -
And then either Expand or Compress Commands.
My studio does not have that option.
What version are you running?
2019.1
Interesting, what platform (win/linux, etc)
Windows. Are you able to attach a screenshot to show what you mean so I can find it here?
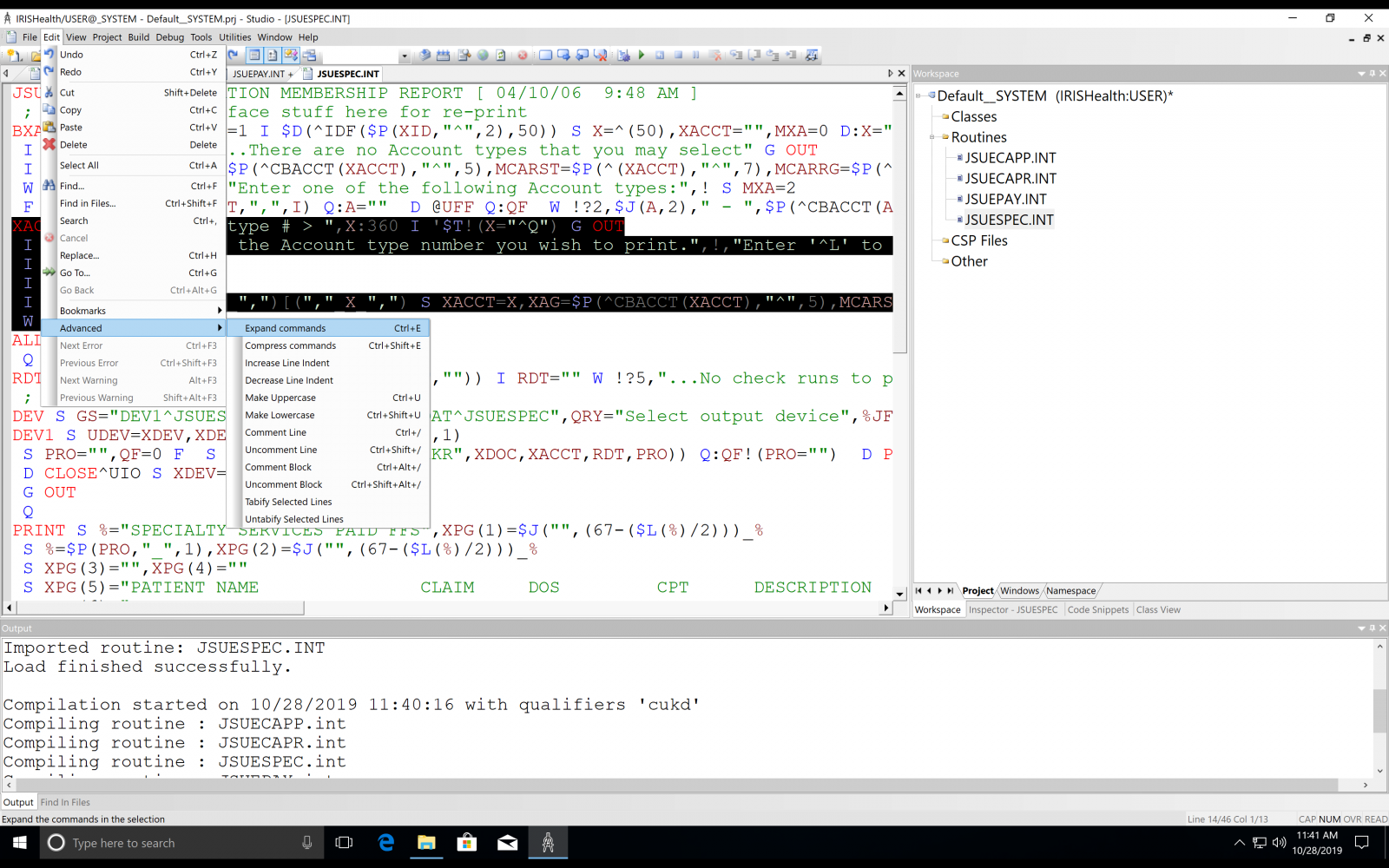
I see. You have Iris for Health I suppose.
We have HealthConnect. It's a Different destribution.
Thank you.
I've seen that option now.
It does show up in some files but not with classes for me.
Thanks anyway. :-)
Oh, it must assume that you wouldn't need it for classes. :(
you wouldn't need it for classes
... while it's available using Ctrl-E / Ctrl-Shift-E shortcuts, in classes as well.
Full names always.
Check this guide.
From what I understand, the single character command names are an anachronism from a time when the actual space the code took up was more of a limiting factor. Nowadays, that's not relevant at all, so the added readability of the full words is optimal.
I remember my first time looking at code bases using the single letters. One of the worst offenders, 'i' instead of 'if' was very annoying; it makes reading the code more like translating and less like reading.
Sadly, in my team we've all been writing MUMPS for so long that the abbreviated style comes naturally and is a hard habit to break. Yes, expanded is better for new starters in the language.
However... Playing devil's advocate you could say that abbreviated commands are:
1. Faster to type (as you said).
2. More compact. Allowing the reader to "see" more of the structure in one go.
You see, you can expand things out too much, in my opinion. Also, it only takes a few minutes for a (reasonable) programmer to get that "S" means "set", "I" means "if", etc. Commands always appear in the same part of the code (unlike some languages), there are not that many to learn, and once you know them, you can read them! So why bother with extra letters? After all "set" is itself only a token for "put the value on the right of the = into the variable on the left" or something like that. It could be "make" or "update" or "<-" (look up the programming language "APL" on Wikipedia if you want a real scare).
I think the main problem with "old fashioned" code is usually poor label/variable names, squeezing too much on one line, and lack of indenting. It's hard to read mainly because of the other parts of the code, not because the commands are single characters. Some things should be longer to better convey what they are for (though not as long as COBOL), and more lines can help convey program structure.
While I'm here, I'm not that keen on spurious spaces in "set x = 1", as opposed to "set x=1". It just spreads out the important stuff - spaces are there to split out the commands. :-)
Mike
I started as an M guy, abbreviating everything, for many years. Once extra spaces were allowed in ObjectScript, I re-trained myself to use extra spaces and fully spelled out commands and $functions. When I'm writing code for myself in the Terminal, I don't always spell everything out. But any code I write that others will see, I spell everything out.
Some folks in this thread talk about abbreviating some commands but not others, or some $functions and not others. Imagine code at one company written by 10 programmers, all of whom choose their own way of abbreviating or not abbreviating. A new programmer joining the company will see a mess. Then imagine trying to come up with an agreed upon set of standards at the company ("you can abbreviate these commands but not those, and you can abbreviate these functions but not those") so that the code appears (at least) consistent. A new programmer joining the company will still see a messy standards document that they'll have to keep checking until they have it memorized.
Compare that to: "spell everything out, spaces around all operators, a space after every comma" (what I do) or something similar. I think the end result justifies the extra typing.
Joel,
I completely agree with you!
Within InterSystems we have at least one development team that has codified this via serverside source control hooks which automatically expand use standard case for all commands (there was a presentation on this at last year's Global Summit). Adopting this tool is on my list of process/tools improvements for my development team in internal apps. There will be a discontinuity in the source control branches when we turn this on and standardize everything in one check-in, but I think the benefits of having a standard way to representing commands without developers having to personally remember to do it the same way will be pretty considerable!
While I agree with what a lot of people said here - you probably should use the the expanded syntax - it doesn't exactly address the fact that it is much quicker (or FEELS much quicker) to type the abbreviations. Especially when I'm in the coding groove and trying to get stuff done. The fact is your IDE can can expand all the commands. My take is this: let your developers do whatever makes their job easier. It's easier to write shorthand, but read longhand - make a tool that converts shorthand to longhand and put that into your source control.
I prefer abbreviated...but I am the old school mumps coder and that is the version I used for years.
Spelled out is nice, but I find it slower to read.
My company doesn't have a preference...at least not one that they have shared with me.