Hi,
I am using embeded python to utilize some pythonic library but i got a problem on my hand.
One of the python function i am using return multiple values
in python you would do something like that :
val1, val2, val3, = function(params)
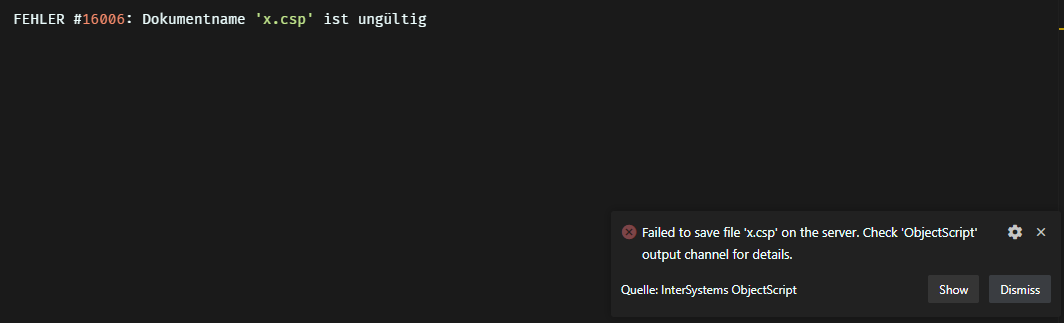
In COS I got something like that :
lib = ##class(%SYS.Python).Import("lib")
val1 = lib.function(params)And I don't know how to get the second and third values.
Is there a way to get them?
.jpg)
.png)

.png)

.png)