This tag relates to the discussions on the development of analytics and business intelligence solutions, visualization, KPI and other business metrics management.
Preview Mode was added to InterSystems IRIS Business Intelligence to give designers a quick view of what their resulting Pivot Table will look like without needing to wait for the results to fully execute. This can be beneficial when designing pivot tables because if you are dragging and dropping elements to see how they look/work in your pivot table and seeing if they have the desired data. Since you are exploring and designing, you don't necessarily care about the results at the moment, but you would still like to see how your table looks with the changes you have made.
we are wondering if anybody has a reporting tool that is capable using IRIS Objects?
I know there are things like Crystal Reports and others out there who can read the SQL Data throug ODBC but we need the capability of using object methods while running the report.
Since now we where using a JAVA based report generator (ReportWeaver) but since the object binding for JAVA doesn't exist anymore in IRIS data platform, did any of you have an alternative report generator?
https://www.youtube.com/embed/CCyWcHi1wII [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
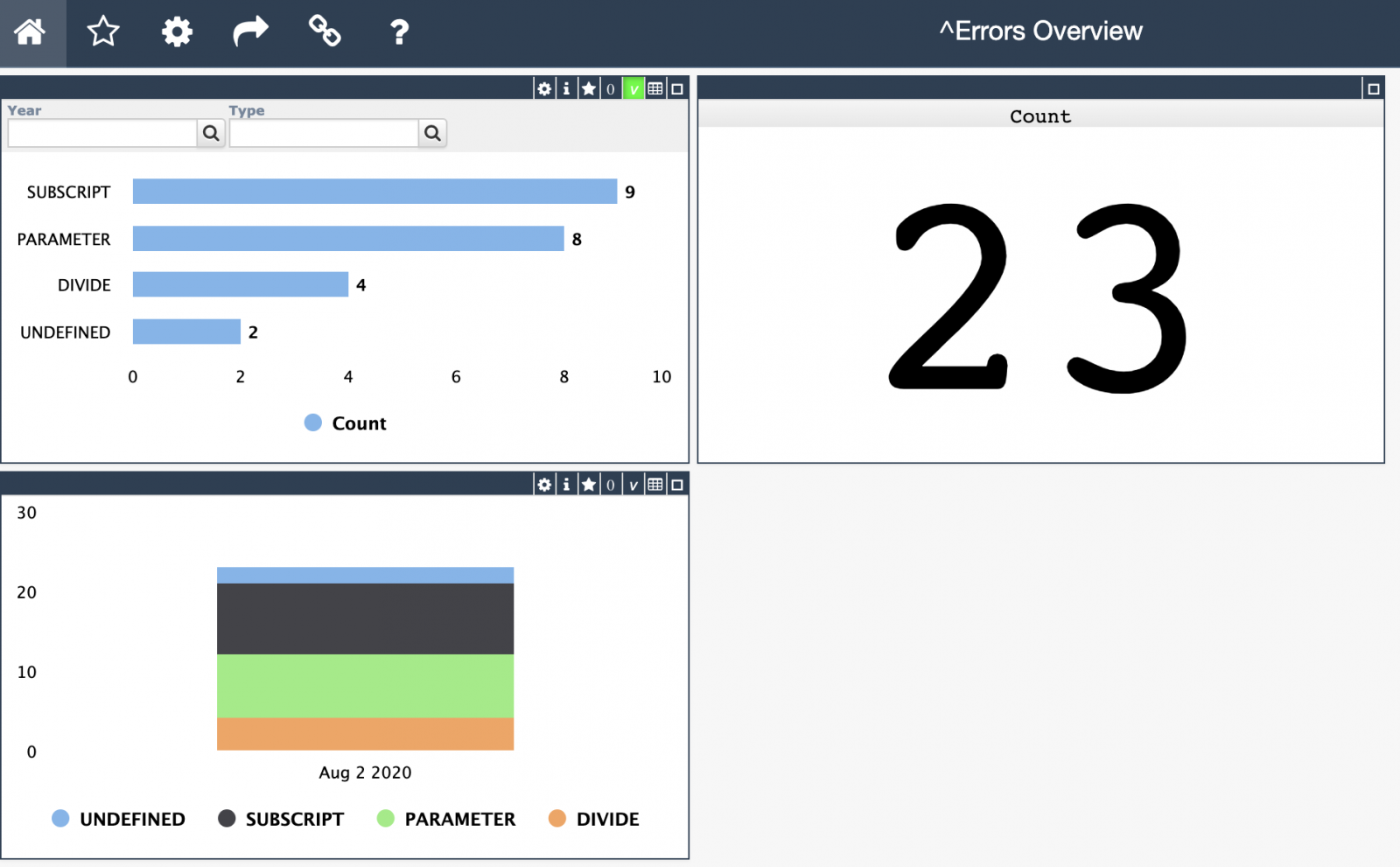
I recently discovered the Monitoring Activity Volume feature in IRIS and I was amazed by it. So, I put it to work in one of our productions. It is nice how easy it is to set up and all the possibilites that came with it.
But there's something weird: the numbers. Actually, one of the BP is stating a time of more than 6 seconds to process:
I was approached recently by and end use who wanted to perform analysis of their databases and see how they could save some space by picking data good for deletion without harming the application. As part of investigation, they wanted to know sizes of globals within datasets. This can be achieved by various means but all of them provide data in text form only.
I thought I might be a good tool for database administrators in general - to see global sizes in a graphical way.
https://www.youtube.com/embed/47M8FWB5C5Y [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
https://www.youtube.com/embed/W53PSUkiuS0 [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
I am trying to create a query that returns the best and worst performing products for a given customer, based on this year's net sales versus last year's net sales, weighted by the total net sales for all of the products sold to this customer in the last two years.
I have created Last Year Net Sales (up to the last month end): AGGREGATE(PERIODSTODATE([Invoice Date].[H1].[YEAR],[Invoice Date].[H1].[Month].[NOW-13]),measures.[Net Sales])
I asked previously about the DR server in the cloud but actually, I'm curious about the backup server to use as analytics server more than for recovery in DR case.
There is a recommended practice to use an async mirror as a server for BI (InterSystems Analytics, DeepSee)
The question is if I have PRIMARY in the cloud (AWS, Google, Azure, etc) "how far" should async mirror member be placed? Same cloud, same private cloud or it doesn't matter at all for analytics purposes?
Learn about InterSystems Reports, powered by Logi Analytics, a report-generation tool that enables you to rapidly create and view visual reports of your data.
https://www.youtube.com/embed/mmA5ArAMLSU [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
I want to have a generic PercentOfAll measure that can be used for any dimension of the cube. This PercentOfAll should act like Count, but instead of showing the number of rows in a cell, it will show the percentage (100*number of rows for that member/all rows) .It should not matter what dimension is being viewed. Ex
There are a total of 100 rows in the source class.
See how cubes are constructed for use in business intelligence, and learn about SQL and MDX query languages. Physical and virtual cubes are used in InterSystems IRIS® Business Intelligence and Adaptive Analytics:
https://www.youtube.com/embed/l6XFj1JQ5Fw [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
Has anyone ever estimated the amount of disk space consumed by the iKnow indexing process ? I know this will be a rough estimate, but, I imagine that for sizing purposes, that would be enough.
The language the unstructured text is in is English.
I am looking for a reporting tool (Analytics purpose) which can be built using cache object script/MUMPS. Basically my requirement is to find a tool where I can implement cache code to report data for my application.
I am unaware of DeepSee and how it works. Please assist for the same.
I have an SDA feed from an Edge server that eventually is fed into HSHI / Analytics. This edge server is loading up patient demographics (in the Patient object), which feeds the HSAA.Patient table in HSHI / Analytics.
However, we have other edge servers also feeding into the same HSHI database, and these other edge servers have better demographic information.
Previously I have already tried to play with Google Data Studio when I connected it to InterSystems FHIRaaS. It has quite a nice UI, with a few chart types available out of the box, it can be quite easily connected to some plain tables (stored as CSV or JSON, for instance), and gives the ability to build quite flexible analytics over it. So, I have decided to implement a new connector to InterSystems Analytics (DeepSee), with the ability to select a cube and do some queries on it.
https://www.youtube.com/embed/66rZCdX7m8U [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
InterSystems has been at the forefront of database technology since its inception, pioneering innovations that consistently outperform competitors like Oracle, IBM, and Microsoft.
In the previous part of this series, we saw how to include data in a portlet from within DeepSee. This used the built in data controller. In this part, we are going to be pulling in data from outside of DeepSee. This will include both information from within InterSystems IRIS and from the OS.
Why use this?
This is useful if you would like to create a dashboard that only contains information about your system. It is also useful if you want to display data about your system along side data that you have stored in DeepSee.
Recently, I get interest in FHIR in order to run for the IRIS for Health FHIR
contest. As a beginner on this topic, I've heard somewhat about it, but I didn't know how complex and powerful was FHIR. As pointed out by @Henrique.GonçalvesDias here, you can model several aspects of the patient history and other related entities.
https://www.youtube.com/embed/PbSKedG25eA [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
I am receiving Mirroring updates to an IRIS for Health async reporting server and need to pause the mirroring journal processing to periodically quiesce the database to rebuild cubes and custom staging tables.
What API or web service can I use to quiesce the reporting server and then later initiate catch up?
Today, is important analyze the content into portals and websites to get informed, analyze the concorrents, analyze trends, the richness and scope of content of websites. To do this, you can alocate people to read thousand of pages and spend much money or use a crawler to extract website content and execute NLP on it. You will get all necessary insights to analyze and make precise decisions in a few minutes.
https://www.youtube.com/embed/ouvGTFHgmiM [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
 By views
By views.png)

 Open Exchange app
Open Exchange app.png)

.png)