 By likes
By likesHi colleagues!
Every day Johns Hopkins University publishes new data on coronavirus COVID-19 pandemic status.
I built a simple InterSystems IRIS Analytics dashboard using InterSystems IRIS Community Edition in docker deployed on GCP Kubernetes which shows key measures of the disease outbreak.
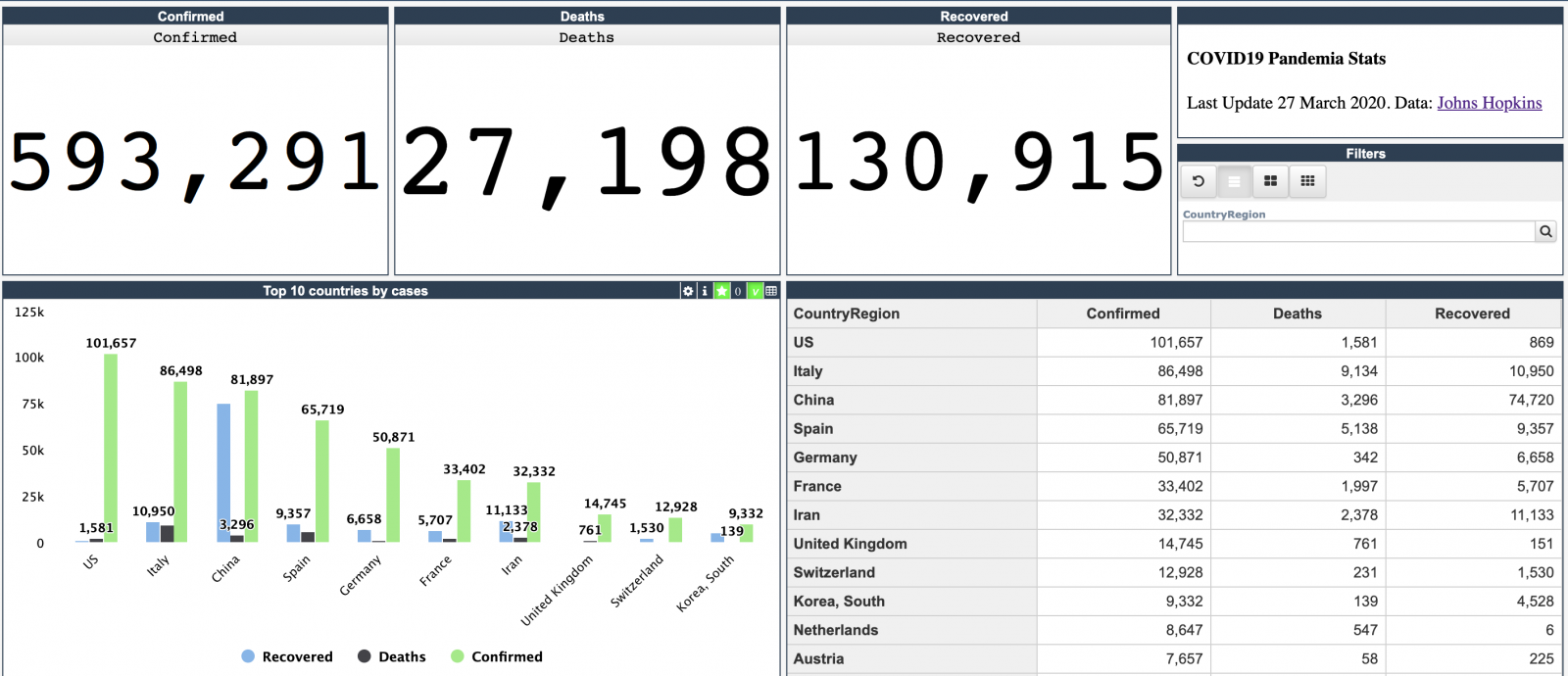
This dashboard is an example of how information from CSV could be analyzed with IRIS Analytics and deployed to GCP Kubernetes in a form of InterSystems IRIS Community Edition.
Added the interactive map of the USA:
 Open Exchange app
Open Exchange app

.png)
.png)