IRIS in Astronomy
In this article we are going to show the results of the comparision between IRIS and Postgress when handling Astronomy data.
Introduction
Since the earliest days of human civilization we have been fascinated by the sky at night. There are so many stars! Everybody has dreamed about them and fantasized about life in other planets.
Astronomers have been identifying and classifying stars since many centuries ago. There are star catalogues compiled in Mesopotamia and Egypt from the 2nd millennium BC [1]. In modern times there have been two main catalogues: Hipparcos [2] and Gaia [3]. Both are the European Space Agency (ESA) missions with a spacecraft dedicated to mapping and characterizing stars and meteorites.
Hipparcos was a pioneering project, launched in 1989, which pinpointed the positions of 100000 stars with high precision and more than 1 million with lesser precisions. In year 2000 a new catalogue was published, which brings the total number of stars to 2.5 million and includes 99% of all stars down to magnitude 11 (unitless measure of brightness, see [4]). This catalogue is still being used by astronomers.
In 2013 ESA launched Gaia [4], a new spacecraft dedicated to mapping the Milky Way and any other star which it detects. Not only it maps their positions, but also their velocities and many other physical parameters: brightness in the Red and Blue color bands, effective temperatures, luminosity, radius, and also it includes tens of thousands of meteorites of the solar system. In total the catalogue has almost 100 columns with the different physical properties and their corresponding errors. All the stars have been treated with the same level of precision, but only a subset of them has all the data available. Scientists have worked hard in order to make the data as reliable as possible.
There have been several releases of the Gaia catalogue, and in this comparison we will use Data Release number 2, which is the first one which includes the results for 1.6 billion of stars and several hundreds of thousands meteorites. So far the different Data Releases have been used in thousands of scientific papers.
Gaia catalogues are redefining the foundation of astronomy and a huge step forward compared to Hipparcos. They are open, anyone can access and download them from the Gaia Archive, which is hosted in the European Space Astronomy Centre (ESAC), located in Madrid (Spain). ESAC is responsible for hosting and archiving all the missions data, which is available to the entire scientific community and general public.

Representation of the area of Milky Way being mapped by Gaia. (All materials released under the Creative Commons By Attribution 4.0 license. Credit is "galaxymap.org, Twitter: @galaxy_map").
Gaia aims to map about 1-2 per cent of the whole Galactic stellar population.
Cache and IRIS in the daily processing of Gaia data
The Gaia satellite in the Sun-Earth Lagrange point 2 about 1.5 million kilometres from Earth. It is always spinning and collecting data, which is received on Earth using antennas in Cebreros (Spain), New Norcia (Australia) and Malargüe (Argentina). Each antenna first sends its data to Germany, where Mission Operation Centre (MOC) receives the telemetry consisting of scientific data from the onboard telescope and auxiliary data. After checking the spacecraft health MOC sends the data to the Science Operation Centre (SOC) In ESAC (Spain). SOC receives a daily average of 40GB of data that can fluctuate depending on the area of the Galaxy being scanned by the satellite. When Gaia observes the center of the Milky Way the total volume reaches 110GB.
The role played by the InterSystems Caché back-end system is paramount, thanks to its processing speed and ability to access approximately 40 terabytes of online information. As the telemetry is received, the data is decompressed and incorporated into InterSystems Caché. The InterSystems technology acts as the working database for the software systems that perform the tasks of pre-processing and verifying the data and the state of the onboard science systems, as well as initial processing and treatment of the images. These operations must be carried out in 24 hours, as there may be spacecraft problems or science alerts like a supernova explosion, and the role played by the InterSystems Caché back-end system is paramount. Its processing speed and ability to access roughly 40 terabytes of information, which is the average saved data volume required to produce all calculations, is key. The database was chosen to perform these complex procedures thanks to its reliability and performance. Currently it is being migrated to InterSystems IRIS, the new evolution of InterSystems Caché.
Thanks to this, scientists can determine the correct status of the instruments onboard the satellite. They can also assess the quality of the scientific data that will subsequently be sent to other centers belonging to DPAC (Data Processing and Analysis Consortium), which is responsible for the data processing and is formed by scientific organizations, universities, study centers, and observatories from different European countries. The results of the studies done by these institutions are collected back in ESAC and from time to time are published as Gaia catalogues.
IRIS performance benchmark
In order to test InterSystems IRIS 2020.1 against Postgress 12 the contents of the Gaia DR2 were downloaded in CSV format from Gaia Archive. As the total catalogue is 1.1 TB only a subset of 99 GB (the machine used for the tests doesn't have enough disk space) corresponding to the CVS files which follow this pattern: Gaia_Source_1*.csv was used in this article.
In this Github repository you can find detailed instructions which can be used to reproduce these results.
Preparation
Server: Ubuntu 20.04 with latest patches. 32GB of RAM. i7-4790 @ 4.00 GHz 4 physical cores.
Disk: Sabrent 1TB NVME
Query tool DBeaver 21.0.1, uses appropiate JDBC drivers in order to connect to each instance.
IRIS: Release 2020.1, 10GB of RAM for 8K DB.
Postgres: Release 12, default ubuntu install
Data Ingestion
The catalogue CSV files have been concatenated on a single big file.
Ingest 115453122 rows with star information (94 columns, full Gaia DR2 catalogue)
IRIS
In order to do the ingestion the IRIS utility SimpleDataTransfer (distributed with IRIS) is used. This tool uses java and IRIS jdbc driver in order to do the ingestion. The ingestion is run in parallel using 10 jobs, each one ingests 200000 CSV lines at a time.
Postgres
The utility pg_bulkload has been used, this tool runs in parallel and writes directly into the database files, so no journal is active.
Results
Time needed to complete the ingestion:
IRIS: 1525 s
Postgres: 2562 s
Simple queries
The following queries are simple, they provide a set of stars which have a given property:
Positions: stars with small error
Find those stars with a small error in their position. The query is:
SELECT * FROM gdr2 WHERE parallax_over_error > 1000The results are:
IRIS: 645 rows .5 s
Postgres: 645 rows 108 s
Blue stars
Select those stars with a significant blue emissions, the query is:
select count(*) from gdr2 where bp_rp < -2The results are:
IRIS: 515 rows 2ms
Postgres: 515 rows 150s
Stars with high proper motions
This query selects those stars whose transversal velocity with respect to Earth is important:
select * from public.gdr2 where (
pmra < -707.1
or pmra > 707.1
or pmdec < -707.1
or pmdec > 707.1
)
and sqrt(pmra * pmra + pmdec * pmdec) > 1e3IRIS 94 rows 34 ms
PG 94 rows 153 s
Good quality results of Gaia DR2 archive
Anthony Brown, the leader of the Gaia consortium Data Processing, has created in his github an example of a query which selects a sample of sources with a recommended quality filter (it selects stars with small errors):
select source_id, ra, ra_error, dec, dec_error, parallax, parallax_error, parallax_over_error, pmra,
pmra_error, pmdec, pmdec_error, ra_dec_corr, ra_parallax_corr, ra_pmra_corr, ra_pmdec_corr,
dec_parallax_corr, dec_pmra_corr, dec_pmdec_corr, parallax_pmra_corr, parallax_pmdec_corr,
pmra_pmdec_corr, radial_velocity, radial_velocity_error,
phot_g_mean_mag, phot_bp_mean_mag, phot_rp_mean_mag, bp_rp, g_rp, bp_g,
2.5/log(10)*phot_g_mean_flux_over_error as phot_g_mean_mag_error,
2.5/log(10)*phot_bp_mean_flux_over_error as phot_bp_mean_mag_error,
2.5/log(10)*phot_rp_mean_flux_over_error as phot_rp_mean_mag_error,
sqrt(astrometric_chi2_al/(astrometric_n_good_obs_al-5)) as uwe
from gaiadr2.gaia_source
where parallax_over_error>5
and radial_velocity is not null
and astrometric_params_solved=31
and rv_nb_transits > 3Results:
IRIS: After 14m 22s a complete list of 736496 stars was provided.
PG: After more than 20m only 495895 stars had been found (the query was still running).
Galaxy density map
The website https://www.galaxymap.org has been providing maps of the Milky Way since 2009. It has many resources, including a beautiful and complete density map which contains density isosurfaces akin to those found in medical MRI scans. Using this technique we generate 3D surfaces consisting of a common density value, much like we can use contour lines on topographic maps to show regions of common elevation. In MRI scans this is human tissue density. For galaxy mapping we can use star density, counting the number of stars per cubic parsec [5]. We can, in a way, use Gaia data to do an MRI scan of the Milky Way.
The map was created using Gaia data using the code which can be located in github. We used the same queries with IRIS and Postgres in order to compare the time needed to fetch the data used to create the map:
SELECT source_id,designation , l , b , parallax , parallax_over_error , phot_g_mean_mag , bp_rp , priam_flags , teff_val , a_g_val FROM gdr2 WHERE ( parallax_over_error > 10 ) and (parallax >= 1.0) and (parallax < 1.1)Results:
IRIS: 11m 49s
PG: timeout
Example image of the map, the colours show the different star densities in each region:
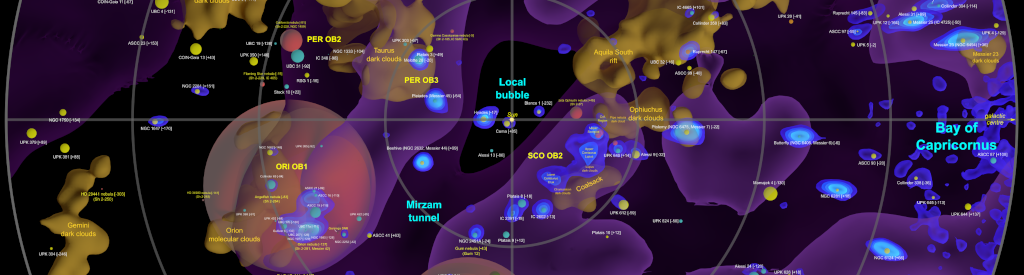
As the author says in his blog the official Gaia archive has a maximum query limit of 30 minutes, so he had to make several queries in order to obtain the data and he needed almost 24 hours to obtain all the data. IRIS is much faster and can provided the data in less time.
Here you can see a video showing an animation of the isosurfaces:
and a complete description of the results:
All materials released under the Creative Commons By Attribution 4.0 license. Credit: "galaxymap.org, Twitter: @galaxy_map".
Conclusion
IRIS is a robust platform which can handle the most complex queries without a glitch and at top speed. IRIS is really well suited for advanced Scientific Research and its speed enables tackling complex projects in a very short time. Also, thanks to it's interoperability extensions it is possible to ingest data in different formats (CSV, XML, TCP, Files), and analyse it using standard SQl or more advanced Machine Learning or Advanced Analytics tools. For more details see InterSystems IRIS Data Platform: High Performance DBMS.
References
[1] Ancient Star Catalogs. Star chart - Wikipedia
[2] ESA Hipparcos mission. Hipparcos - Wikipedia
[3] ESA Gaia mission. ESA Science & Technology - Gaia
[4] Magnitude: Star brightness. Magnitude (astronomy) - Wikipedia
[5] Parsec: Astronomy unit of length corresponding to 3.26 light years Parsec - Wikipedia
Comments
Postgres: Release 12, default ubuntu install
Default install hardly had a chance to win. Why didn't you use IRIS default install?
For fair play, each DBMS should be best tuned by the appropriate specialist.
It is a default install of IRIS and Postgres.
Am I reading this right: 99 GB and not a single index? The IRIS numbers are incredible under those circumstances, but surely one would put some effort into the schema before issuing non-trivial queries against a large data set. There's a lot of low-hanging fruit here, at least for PostgreSQL.
Of course both IRIS and Postgres have indexes created
Unless pg_bulkload or SimpleMover are doing some kind of magic, I don't see any evidence of indexes in the GitHub repo. gaia_source.pgsql contains a single CREATE TABLE statement, and gaia_source.irissql contains a list of field names.
I don't think the repo is sufficient to reproduce your results.
This article refers to https://github.com/es-comunidad-intersystems/IRIS-in-Astronomy but when I tried going there you get a 404 Page not found. Maybe the repo is not public?
The repo was private, now it is public.