I would like to know if anybody has any lessons learned implementing 508 compliance in Zen interfaces.
Thank you for any feedback.
I would like to know if anybody has any lessons learned implementing 508 compliance in Zen interfaces.
Thank you for any feedback.
We have a program set up in the HealthShare Facility Registry. And we have some patients enrolled into this program. In the HealthShare Registry management, we set up following consent policy for this facility (we call it program), Default Block Except: Block data except for the groups specified below, unless overridden by patient. There is no program in the Selected Programs so the consent should be applied to everybody.
Hi community ,
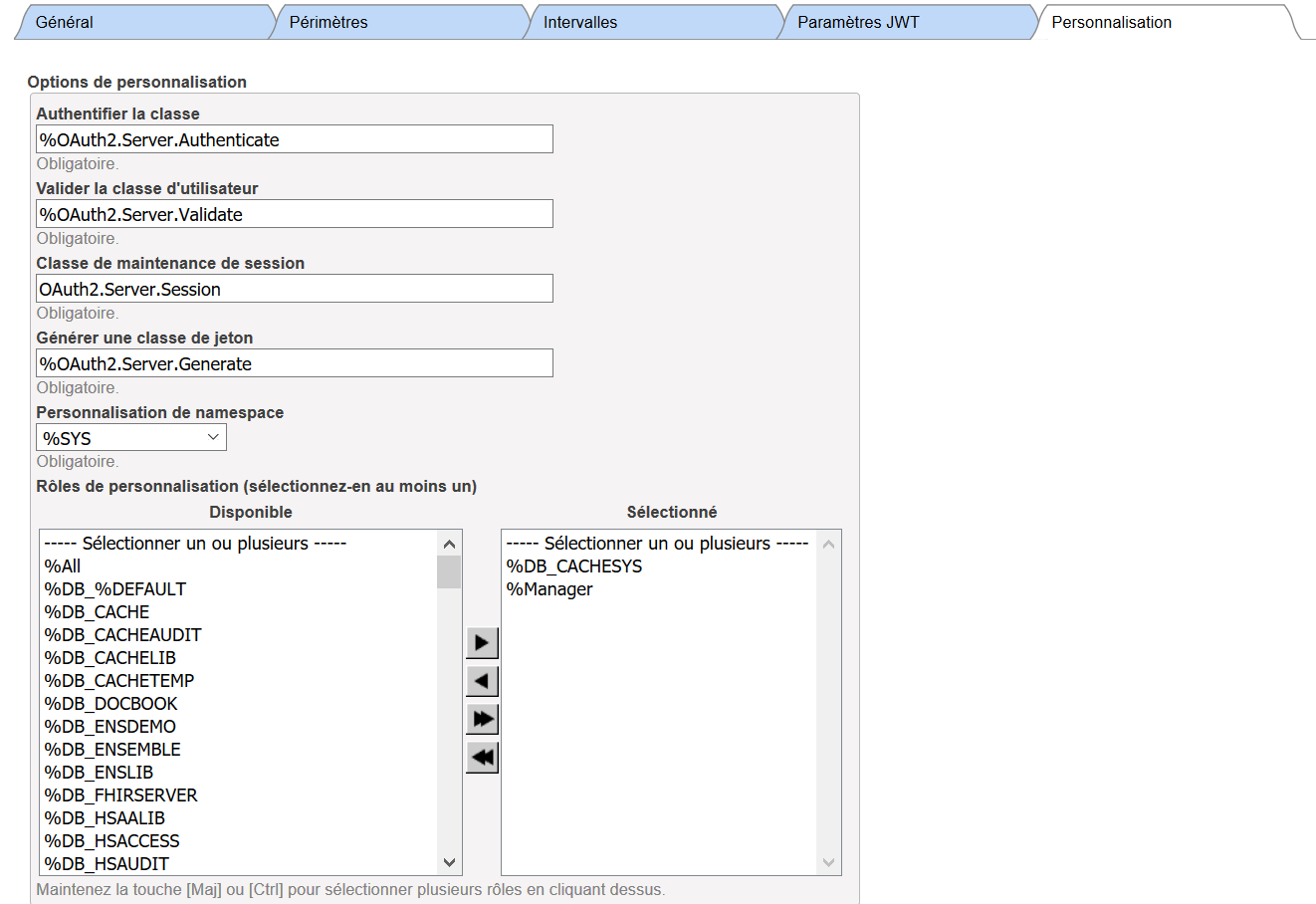
i develop my LogUser Method on my rest API , the scenario is as follow :
when user enter his login & password , i check first in my table if he exists (this stape is done), now i want know how generate acces token from authorization server , i've as idea to call the "%OAuth2.Server.Generate" which is implemented on the configuration party (we find the correspondint attached screenshot ), but i don't know if i'm sure , we find here the developped method:
ClassMethod LogUser(profile) As %Status
{
set user ={}.%FromJSON(profile)
set login=user.username
set password=user.password
// now we check on the security.users
set ID=Replace(login,"@","^")
//basculer vers le name space %sys
zn "%sys"
set x=$System.Security.Login(ID,password)
if x=0 { write "unknown user"}
else
// get role from resources BWX
{
set role=$roles
set a=[],sep=","
for i=1:1:$length($roles,sep) { do a.%Push($piece($roles,sep,i))}
w a.%ToJSON()
//generate acces token
}
quit $$$OK
}
I've written several custom classes to add additional search capabilities to the user / clinician search defined in HS.UI.Registry.User.Find. I've tested it out, and it looks and works how I'd like it to, but I've run into a snag when trying to implement it.
...in order to initialize the data model and form with data from another object.
Our Zen MVC project recently had an issue with a child object being assigned to multiple parent objects (the design calls for one parent per child). The root cause of this issue was the use of a %session variable to pass the ID of the parent object to the OnLoadModel method of the DataModel associated with the child object.
Hi!
I'm trying to connect to one of our Ensemble servers Cache database from a C#-windows form . I'm running the client from my local computer with OS win7. Using .NET FW ver 4.5.2 in the client.
ODBC local setup using "InterSystems ODBC35"
In this ODBC konfigurationview i can put my userID and password and try a testconnect (or ping). And that run successful.
However, we don't want to leave credentials in the ODBC-configuration it self (open up for anybody to use the source) but instead send it from the klients.
I have try all three ways from https://www.connectionstrings.com/cache/
I'm VERY novice on all things "OpenAM", and beyond knowing that Caché supports working with OpenAM, I have nothing else to go on.
The documentation doesn't seem to be very deep on the nature of how this works beyond a single paragraph saying it's supported for Single Sign On (SSO).
For Caché to use this, I get that there is an environment variable (REMOTE_USER) which is set to "something", but it's not clear to me how this ends up mapping to a provisioned caché user (or LDAP provisioned user for that matter) and ultimately to the %Roles in effect and subsequent system access.
Hi, Community,
This post will demonstrate how to display data on the web by using Embedded Python , Python Flask Web Framework and Jquery datatable
We will display processes from %SYS.ProcessQuery table.
<table id="myTable" class="table table-bordered table-striped">
</table> <script>
$(document).ready(function() {
// parse the data to local variable passed from app.py file
let my_data = JSON.parse('{{ my_data | tojson }}');
let my_cols = JSON.parse('{{ my_cols | tojson }}');
$('#myTable').DataTable( {
"data": my_data,
"columns": my_cols,"} );
} );
How to check if the password is strong enough, so it will not be cracked very fast? And how to make a strong password?
I've developed a tool that may help with this. You can find it on OpenExchange. Install it with zpm
zpm "install passwords-tool"
This module will install just one class caretdev.Passwords, which contains a few helpful methods in it
To get a secure password it's usually enough to use letters in upper and lower case, digits, and special symbols, and it should be at least 8 symbols long.
I'm looking for guidance on how best to normalize Height and Weight values to standard units. For example, to accept height as Feet/Inches, Inches, and Centimeters from various sources, but always display Feet/Inches in Clinical Viewer, etc.
If anyone has done this before, please share details of how it was implemented. Things I'd be specifically interested in:
Let's consider you would like to efficiently store your historical data in a similar structure than the one used for your current data, but without sharing the same physical storage (ie : not in the same global). What is the most efficient way to do it ?
Below a simple class of your current data :
Class data.current.person Extends (%Persistent, %Populate)
{
Parameter DEFAULTGLOBAL = "^on.person";
If one of your packages on OEX receives a review you get notified by OEX only own YOUR package. The rating reflects the experience of the reviewer with the status found at the time of review. It is kind of a snapshot and might have changed meanwhile.
New with this edition:
Reviews by other members of the community are marked by * in the last column.
User calls my REST service. I need:
Is it possible? How?
Can you please provide ORM Sample HL7 for Version 2.8.2?
Also, give me all the HL7 Versions supported list for ORM message type.
Hey Community,
Enjoy watching the new video on InterSystems Developers YouTube channel:
⏯ Creating Virtual Models with InterSystems IRIS Adaptive Analytics
Hi Developers!
Suppose you want to create your ObjectScript library to be distributed via ObjectScript Package Manager. And there is an obvious question: what is the naming convention on the packages and class names?
Naming packages and classnames
There is already some accepted practice with package managers and we will follow the best practices in this field. The most reasonable and simple looks the approach with having company as the first package then project as the second and then classes and subpackages of the project.
Hi developers!
As you probably noticed in IRIS 2021 the names of globals are random.
And if you create IRIS classes with DDL and want to be sure what global was created you probably would want to provide a name.
And indeed you can do it.
Use WITH %CLASSPARAMETER DEFAULTGLOBAL='^GLobalName' in CREATE Table to make it work. Documentation. See the example below:
Python is 31 today ; let’s celebrate it 🎂
And special thanks to Guido van Rossum
Creating REST API using InterSystems ObjectScript is very easy, but some recipes can help you into this process:
1) To create your REST API extends %CSP.REST and Go to System Administration > Security > Applications > Web Applications > Click the button Create New Web Application and set the Name, REST Dispatch Class with your package and classname and choose the Allowed Authetication Methods. See this example:
Edit Web Application
.png)
2) Configure your REST API using ZPM configuration. To do this follow this sample (watch the tag <CSPApplication>):
ZPM Code to Create REST API
Hi Community,
This post is a introduction of my openexchange iris-python-apps application. Build by using Embedded Python and Python Flask Web Framework.
Application also demonstrates some of the Python functionalities like Data Science, Data Plotting, Data Visualization and QR Code generation.

If one of your packages on OEX receives a review you get notified by OEX only on YOUR package.
It reflects my experience with the status I found at the time of my review.
It is kind of a snapshot and might have changed meanwhile.
Receiving this error ERROR #5002: Cache error: <MAXSTRING>zgetAtFromArray+28^EnsLib.HL7.Segment.1
what is the max size for an encoded PDF using the GetFieldStreamRaw code
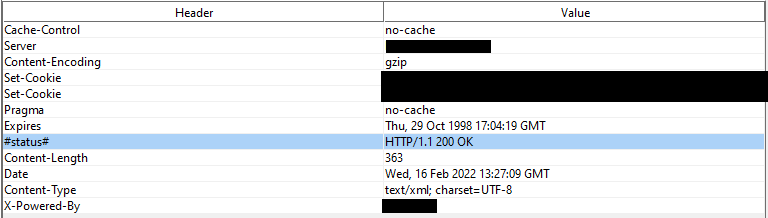
After invoking a SOAP call in a SOAP Outbound Adapter Operation, how do we get the header information? For example, the HTTP 200 response code.
In SoapUI we can read the header information, but we're trying to view it in Production.
In the class HS.Util.Zip.Operations the OnInit method does a get value for ZipUtility, ZipCommand, UnZipCommand.
What is not clear in documentation is where/how those key/values are set. Any assistance would be appreciated.
Method OnInit() As %Status
{
If (##class(HS.Registry.Config).GetKeyValue("\ZipUtility\ZipCommand")="") || (##class(HS.Registry.Config).
This post provides guidelines for configuration, system sizing and capacity planning when deploying IRIS and IRIS on a VMware ESXi. This post is based on and replaces the earlier IRIS-era guidance and reflects current VMware and InterSystems recommendations.
Last update Jan 2026. These guidelines are a best effort, remember requirements and capabilities of VMware and IRIS can change.
I jump right in with recommendations assuming you already have an understanding of VMware vSphere virtualization platform.
Hello everyone. I present this project to the contest. The export module is essential in many of my projects and is often used in all my product servers.
I have implemented various scenarios in the invoke attribute initialization module, both maximalistic with many additional projects to demonstrate in GCR , and minimalistic to install natively in production instance
zpm "install appmsw-sql2xlsx -Dzpm.demo=none"
To demonstrate the possibilities, I used the fileserver and csvgen projects.
Hi Community, we continue to gather feedback about Data Loading & Packaging. In particular, we're interested in hearing your impressions on some of the new capabilities added with InterSystems IRIS 2021.2 We'll be using this feedback to improve InterSystems IRIS, so please feel free to share any details and feedback:
>> Link to the survey (14 questions, 5 min) <<
Note: this is the same survey we already published during the contest, on Global Masters and Discord. If you already participated, you don't have to do it again. Thank you for the feedback!
.png)
Hey developers!
Sometimes we need to insert or refer to the data of classes directly in globals.
And maybe a lot of you expect that data structure of global with records is:
^Sample.Person(Id)=$listbuild("",col1,col2,...,coln).And this article is a heads up, that this is not always true, don't expect it as granted!
Hi all,
I am trying to use a %Status property on some of my Response classes. If the execution of a service goes wrong, I set the %Status property on Response with the value $$$ERROR($$$GeneralError, "pre-defined error message").
When I check the visual trace for this message and look for the %Status (property "status_code" on the image), it is displayed like this:
.png)
If I select to display the Body of the Response, I get the 'readable' form of %Status:
According to the documentation, this is expected as %Status properties are encoded in base64 during Projection to XML.
Update 7 includes a number of stability improvements over previous updates and support for support for all of the planned 2022.1 features. If you notice any problems at all, now's the time to let us know. The docker pull commands below have been updated with the latest build numbers. Enjoy!
As this is InterSystems' first developer preview release, let's take a moment to describe what these are. The developer preview program enhances the previous IRIS preview program with approximately bi-weekly releases that add features as they are ready. This allows us to get feedback on capabilities and enhancements as they're available. You'll see below a list of enhancements that are targeted for 2022.1, which are not included in the first developer preview. Look for those over the coming weeks.
We are eager to learn from your experiences with this new release ahead of its General Availability release. Please share your feedback through the Developer Community so we can build a better product together.
InterSystems IRIS Data Platform 2022.1 is an extended maintenance (EM) release. 2022.1 includes the many important new capabilities and enhancements have been added in 2021.2, the continuous delivery (CD) release, since 2021.1, the previous EM release. Please refer to the release notes for 2021.2 for an overview of these enhancements.

