Step by step guide to create personalized AI with ChatGPT by using LangChain
.png)
As an AI language model, ChatGPT is capable of performing a variety of tasks like language translation, writing songs, answering research questions, and even generating computer code. With its impressive abilities, ChatGPT has quickly become a popular tool for various applications, from chatbots to content creation.
But despite its advanced capabilities, ChatGPT is not able to access your personal data. So in this article, I will demonstrate below steps to build custom ChatGPT AI by using LangChain Framework:
-
Step 1: Load the document
-
Step 2: Splitting the document into chunks
-
Step 3: Use Embedding against Chunks Data and convert to vectors
-
Step 4: Save data to the Vector database
-
Step 5: Take data (question) from the user and get the embedding
-
Step 6: Connect to VectorDB and do a semantic search
-
Step 7: Retrieve relevant responses based on user queries and send them to LLM(ChatGPT)
-
Step 8: Get an answer from LLM and send it back to the user
NOTE: Please read my previous article LangChain – Unleashing the full potential of LLMs to get more details about LangChain and about how to get OpenAI API Key
So, let's begin
Step1: Load the document
First of all, we need to load the document. So we will import PyPDFLoader for PDF document
ClassMethod SavePDF(filePath) [ Language = python ]
{
#for PDF file we need to import PyPDFLoader from langchain framework
from langchain.document_loaders import PyPDFLoader
# for CSV file we need to import csv_loader
# for Doc we need to import UnstructuredWordDocumentLoader
# for Text document we need to import TextLoader
#import os to set environment variable
import os
#Assign OpenAI API Key to environment variable
os.environ['OPENAI_API_KEY'] = "apiKey"
#Init loader
loader = PyPDFLoader(filePath)
#Load document
documents = loader.load()
return documents
}Step 2: Splitting the document into chunks
Language Models are often limited by the amount of text that you can pass to them. Therefore, it is necessary to split them up into smaller chunks. LangChain provides several utilities for doing so.
Using a Text Splitter can also help improve the results from vector store searches, as eg. smaller chunks may sometimes be more likely to match a query. Testing different chunk sizes (and chunk overlap) is a worthwhile exercise to tailor the results to your use case.
ClassMethod splitText(documents) [ Language = python ]
{
#In order to split the document we need to import RecursiveCharacterTextSplitter from Langchain framework
from langchain.text_splitter import RecursiveCharacterTextSplitter
#Init text splitter, define chunk size 1000 and overlap = 0
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
#Split document into chunks
texts = text_splitter.split_documents(documents)
return texts
}Step 3: Use Embedding against Chunks Data and convert to vectors
Text embeddings are the heart and soul of Large Language Operations. Technically, we can work with language models with natural language but storing and retrieving natural language is highly inefficient.
To make it more efficient, we need to transform text data into vector forms. There are dedicated ML models for creating embeddings from texts. The texts are converted into multidimensional vectors. Once embedded, we can group, sort, search, and more over these data. We can calculate the distance between two sentences to know how closely they are related. And the best part of it is these operations are not just limited to keywords like the traditional database searches but rather capture the semantic closeness of two sentences. This makes it a lot more powerful, thanks to Machine Learning.
Text embedding models take text input and return a list of floats (embeddings), which are the numerical representation of the input text. Embeddings help extract information from a text. This information can then be later used, e.g., for calculating similarities between texts (e.g., movie summaries).
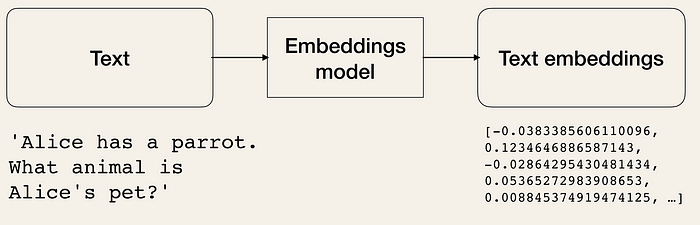
ClassMethod getEmbeddings(query) [ Language = python ]
{
#Get embeddings model from Langchain framework
from langchain.embeddings import OpenAIEmbeddings
#Define embedding
embedding = OpenAIEmbeddings()
return embedding
}
Step 4: Save data to the Vector database
ClassMethod saveDB(texts,embedding) [ Language = python ]
{
#Get Chroma db from langchain
from langchain.vectorstores import Chroma
# Embed and store the texts
# Supplying a persist_directory will store the embeddings on disk
# e.g we are saving data in myData folder in current application path
persist_directory = "myData"
vectordb = Chroma.from_documents(documents=texts, embedding=embedding, persist_directory=persist_directory)
#save document locally
vectordb.persist()
vectordb = None
}
Step 5: Take data (question) from the user and get the embedding
ClassMethod getVectorData(query) [ Language = python ]
{
#NOTE : We should have same embedding used when we saved data
from langchain.embeddings import OpenAIEmbeddings
#get embeddings
embedding = OpenAIEmbeddings()
#take user input (parameter)
query = query
#Code continue...
Step 6: Connect to VectorDB and do a semantic search
#code continue....
from langchain.vectorstores import Chroma
persist_directory = "myData"
## Now we can load the persisted database from disk, and use it as normal.
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
return vectordb
}Step 7: Retrieve relevant responses based on user queries and send them to LLM(ChatGPT)
Conversational memory is how a chatbot can respond to multiple queries in a chat-like manner. It enables a coherent conversation, and without it, every query would be treated as an entirely independent input without considering past interactions.
The LLM with and without conversational memory. The blue boxes are user prompts and in grey are the LLMs responses. Without conversational memory (right), the LLM cannot respond using knowledge of previous interactions.
The memory allows a Large Language Model (LLM) to remember previous interactions with the user. By default, LLMs are stateless — meaning each incoming query is processed independently of other interactions. The only thing that exists for a stateless agent is the current input, nothing else.
The ConversationalRetrievalChain is a conversational AI model that is designed to retrieve relevant responses based on user queries. It is a part of the Langchain team's technology. The model uses a retrieval-based approach, where it searches through a database of pre-existing responses to find the most appropriate answer for a given query. The model is trained on a large dataset of conversations to learn patterns and context in order to provide accurate and helpful responses.
ClassMethod retriveResponse(vectordb) [ Language = python ]
{
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
#Conversational memory is how a chatbot can respond to multiple queries
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
#The ConversationalRetrievalChain is a conversational AI model that is designed to retrieve relevant responses based on user queries
qa = ConversationalRetrievalChain.from_llm(OpenAI(temperature=0), vectordb.as_retriever(), memory=memory)
return qa
}
Step 8: Get an answer from LLM and send it back to the user
ClassMethod getAnswer(qa) [ Language = python ]
{
#Get an answer from LLM and send it back to the user
getAnswer = qa.run(query)
return getAnswer
}To check more details and features, please visit my application irisChatGPT
Related Video
Thanks