In healthcare,interoperability is the ability of different information technology systems and software applications to communicate, exchange data, and use the information that has been exchanged.
The InterSystems IRIS has a series of facilitators to capture, persist, interoperate, and generate analytical information from data in XML format. This article will demonstrate how to do the following:
Capture XML (via a file in our example);
Process the data captured in interoperability;
Persist XML in persistent entities/tables;
Create analytical views for the captured XML data.
Capture XML data
The InterSystems IRIS has many built-in adapters to capture data, including the next ones:
There is a Link Procedure Wizard option within the Management Portal (System > SQL >Wizards > Link Procedure) which I had reliability issues with so I decided to use this solution instead.
The Telegram Adapter for InterSystems IRIS serves as a bridge between the popular Telegram messaging platform and InterSystems IRIS, facilitating seamless communication and data exchange.
Recently I needed to restore a version of a production class, which was overwritten by compilation and running UpdateProduction. As the correct version was unavailable in the source control, I used journals to restore the data. Journals store a plethora of information about what's happening in the system and are quite a powerful tool. This article explains how to work with journals to extract the data you require.
I'm sharing a tool for data ingestion that we have used in some projects.
DataPipe is an interoperability framework for data ingestion in InterSystems IRIS in a flexible way. It allows you to receive data from external sources, normalize and validate the information and finally perform whatever operation you need with your data.
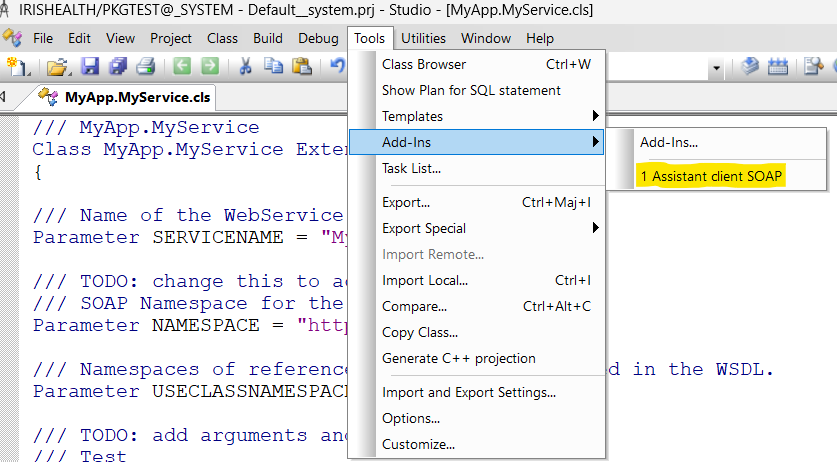
I would like to take advantage of our topic on capture for Health Data Warehouses (on DC-FR) to show you how to quickly create HTTP SOAP and REST clients. IRIS, as well as applications available on Open Exchange offers solutions to generate them from a WSDL or a swagger specification.
SOAP client
Nothing could be easier than creating a SOAP client. All you need is the WSDL.A wizard is available from the IRIS Studio. It allows you to generate not only your classes for a web service client but also the “Business Services” and “Business Operations” if you want to consume them with the interoperability framework.
InterSystems IRIS 2020.1 includes PEX (Production EXtension Framework) to facilitate the development of IRIS Interoperability productions with components written in Java or .NET.
Thanks to PEX, an integration developer with knowledge of Java or .NET can benefit from the power, scalability, and robustness of the InterSystems IRIS Interoperability framework and be productive in no time.
Check out this short demo on the InterSystems Developer YouTube channel showing how the new Production Component Driver can be used for Source Control of Interoperability Productions.
The driver enables highly granular management of interoperability productions with tight integration into the InterSystems IRIS management portal.
https://www.youtube.com/embed/xAT4PZ6n3eM [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
FTP (File Transfer Protocol) is a network protocol for transmitting files over TCP/IP connections in a network (including the Internet) configured to transfer files via this protocol. In an FTP transaction, a file sender is called a local host. A file receiver involved in FTP is a remote host, and it is usually a server. Although many file transfers can be conducted using Hypertext Transfer Protocol (HTTP), FTP is still commonly used to transfer files behind the scenes for other applications, such as banking services.
On the Latest GlobalSummit 2022, InterSystems Introduced Cloud SQL. So, you may have lightweight InterSystems IRIS with access to SQL only. Well, what if you would still need some Interoperability features in the cloud as well? There are various solutions on the market nowadays, which offer a bunch of integration adapters out of the box and can be extended with support from the community. Some time ago, I've implemented an adapter for the Node-RED project, which can be deployed manually everywhere you want. Now I would like to introduce a new integration with my recent discovery, n8n.io
n8n.io is a workflow automation platform, that supports over 200 different integrations out of the box and from a community, and now including InterSystems IRIS.
https://www.youtube.com/embed/KBrvJvJLIXA [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
https://www.youtube.com/embed/-Vx_EAHMqXg [This is an embedded link, but you cannot view embedded content directly on the site because you have declined the cookies necessary to access it. To view embedded content, you would need to accept all cookies in your Cookies Settings]
In this webinar, we will talk about the interoperability capabilities of InterSystems IRIS, will do a demo of building the basic IRIS interoperability solution, and demo how to use the PEX. Also, we’ll discuss and answer the questions on how to build interoperability solutions using InterSystems IRIS and IRIS for Health.
Enhance Ensemble or IRIS production so it can dynamically allocate pool size for adapter-based components based on their utilization.
Sometimes, an unexpected traffic volume occurs, and default pool size allocated to production components may become a bottleneck. To avoid such situations, I created a demonstrator project some 2 years ago to see, whether it would be possible and feasible to modify production, so it allowed for dynamically modifying its components per their load.
InterSystems and Intel recently conducted a series of benchmarks combining InterSystems IRIS with 2nd Generation Intel® Xeon® Scalable Processors, also known as “Cascade Lake”, and Intel® Optane™ DC Persistent Memory (DCPMM). The goals of these benchmarks are to demonstrate the performance and scalability capabilities of InterSystems IRIS with Intel’s latest server technologies in various workload settings and server configurations. Along with various benchmark results, three different use-cases of Intel DCPMM with InterSystems IRIS are provided in this report.
There are numerous ways to interact with InterSystems Caché: We can start with ODBC/JDBC that are available via SQL gateway. There are API for .NET and Java too. But if we need to work with native binary libraries, such interaction is possible through Caché Callout Gateway, which can be tricky. You can read more about the ways of facilitating the work with native libraries directly from Caché in the article below.
A few weeks ago I published an API accelerator call Memoria, Is a very simple way to minimize the time and network traffic to and end-point, I hope could be useful.
IRIS and Ensemble are designed to act as an ESB/EAI. This mean they are build to process lots of small messages.
But some times, in real life we have to use them as ETL. The down side is not that they can't do so, but it can take a long time to process millions of row at once.
To improve performance, I have created a new SQLOutboundAdaptor who only works with JDBC.
BatchSqlOutboundAdapter
Extend EnsLib.SQL.OutboundAdapter to add batch batch and fetch support on JDBC connection.
In this article, I will introduce my application iris-fhir-bridge
IRIS-FHIR-Bridge is a robust interoperability engine built on InterSystems IRIS for Health, designed to transform healthcare data across multiple formats into FHIR and vice versa. It leverages the InterSystems FHIR Object Model (HS.FHIRModel.R4.*) to enable smooth data standardization and exchange across modern and legacy healthcare systems.
Profiling CCD Documents with LEAD North’s CCD Data Profiler Ever opened a CCD and been greeted by a wall of tangled XML? You’re not alone. Despite being a core format for clinical data exchange, CCD's are notoriously dense, verbose, and unfriendly to the human eye. For developers and analysts trying to validate their structure or extract meaningful insights, navigating these documents can feel more like archaeology than engineering.
RabbitMQ is a message broker that allows producers (those who send a data message) and consumers (those who receive a data message) to establish asynchronous, real-time, and high-performance massive data flows. RabbitMQ supports AMQP (Advanced Message Queuing Protocol), an open standard application layer protocol. The main reasons to employ RabbitMQ include the following:
You can improve the performance of the applications using an asynchronous approach.
It lets you decouple and reduce dependencies between services, microservices, and applications with the help of a data message mediator, meaning that there is no need for producers and consumers of exchanged data to know each other.
It allows the long-running processing of sent data (with the results) to be delivered after utilizing a response queue.
It helps you migrate from monolithic to microservices, where microservices exchange data via Rabbit in a decoupled and asynchronous way.
It offers reliability and resilience by making it possible for messages to be stored and forwarded. A message can be delivered multiple times until it is processed.
Message queueing is the key to scaling your application. As the workload increases, you will only have to add more workers to handle the queues faster.
Once upon a time in Ensemble Management Portal the pool size of each component (Business Host) within the production was displayed in the Production Configuration page.
This information was very useful, especially when a production have tens or hundreds of components.
In your Interoperability Production you could always have a Business Operation that is an HTTP client, that uses OAuth 2.0 for authentication, but you had to customize the Operation for this authentication methodology. Since v2024.3, which was lately released, there is a new capability, providing new settings, to handle this more easily.
When building a bundle from legacy data, I (and others) wanted to be able to control whether or not the resources were generated with a FHIR Request Method of PUT instead of the hard coded POST. I have extended the two classes responsible for transforming SDA to FHIR in an Interoperability Production to accomodate a setting that lets the user control the Request Method.
I recently had the need to monitor from HealthConnect the records present in a NoSQL database in the Cloud, more specifically Cloud Firestore, deployed in Firebase. With a quick glance I could see how easy it would be to create an ad-hoc Adapter to make the connection taking advantage of the capabilities of Embedded Python, so I got to work.
 By update
By update Open Exchange app
Open Exchange app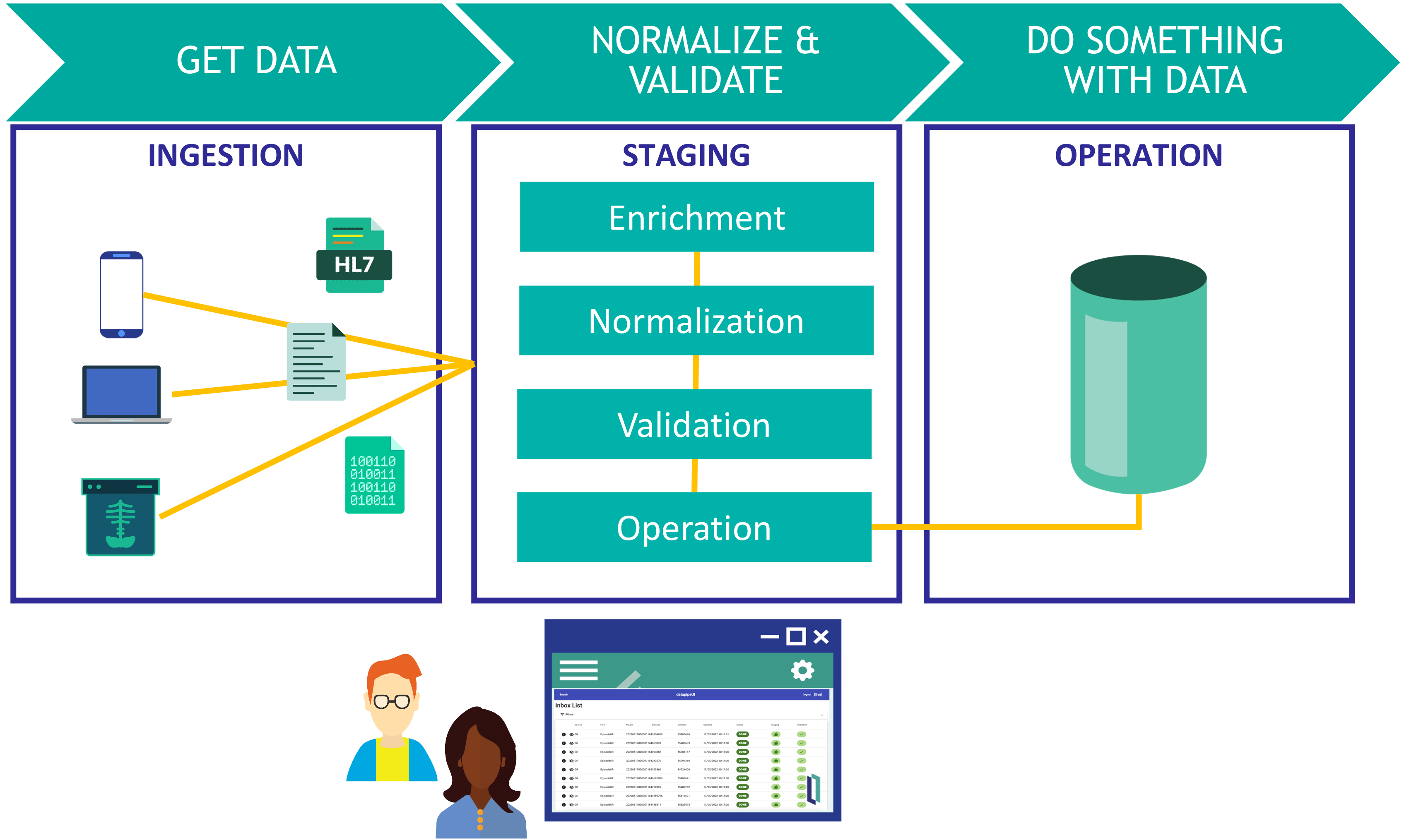




.png)
.png)