InterSystems IRIS and Intel Optane DC Persistent Memory
InterSystems and Intel recently conducted a series of benchmarks combining InterSystems IRIS with 2nd Generation Intel® Xeon® Scalable Processors, also known as “Cascade Lake”, and Intel® Optane™ DC Persistent Memory (DCPMM). The goals of these benchmarks are to demonstrate the performance and scalability capabilities of InterSystems IRIS with Intel’s latest server technologies in various workload settings and server configurations. Along with various benchmark results, three different use-cases of Intel DCPMM with InterSystems IRIS are provided in this report.
Overview
Two separate types of workloads are used to demonstrate performance and scaling – a read-intensive workload and a write-intensive workload. The reason for demonstrating these separately is to show the impact of Intel DCPMM on different use cases specific to increasing database cache efficiency in a read-intensive workload, and increasing write throughput for transaction journals in a write-intensive workload. In both of these use-case scenarios, significant throughput, scalability and performance gains for InterSystems IRIS are achieved.
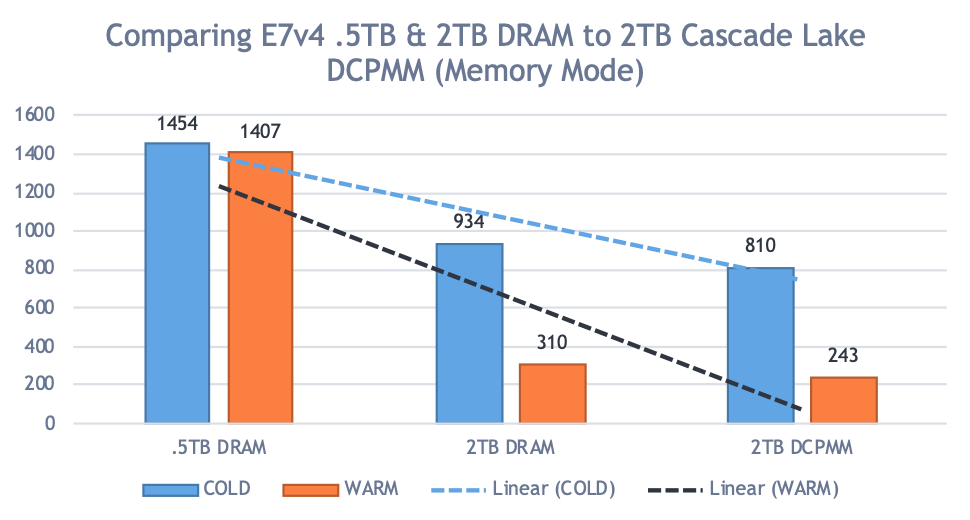
- The read-intensive workload leveraged a 4-socket server and massive long-running analytical queries across a dataset of approximately 1.2TB of total data. With DCPMM in “Memory Mode”, benchmark comparisons yielded a significant reduction in elapsed runtime of approximately six times faster when compared to a previous generation Intel E7v4 series processor with less memory. When comparing like-for-like memory sizes between the E7v4 and the latest server with DCPMM, there was a 20% improvement. This was due to both the increased InterSystems IRIS database cache capability afforded by DCPMM and the latest Intel processor architecture.
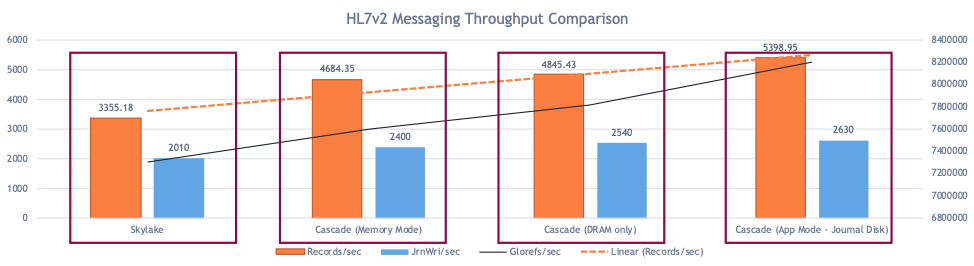
- The write-intensive workload leverages a 2-socket server and InterSystems HL7 messaging benchmark which consists of numerous inbound interfaces, each message has several transformations and then four outbound messages for each inbound. One of the critical components in sustaining high throughput is the message durability guarantees of IRIS for Health, and the transaction journal write performance is crucial in that operation. With DCPMM in “APP DIRECT” mode as DAX XFS presenting an XFS file system for transaction journals, this benchmark demonstrated a 60% increase in message throughput.
To summarize the test results and configurations; DCPMM offers significant throughput gains when used in the proper InterSystems IRIS setting and workload. The high-level benefits are increasing database cache efficiency and reducing disk IO block reads in read-intensive workloads and also increasing write throughput for journals in write-intensive workloads.
In addition, Cascade Lake based servers with DCPMM provide an excellent update path for those looking into refreshing older hardware and improving performance and scaling. InterSystems technology architects are available to help with those discussions and provide advice on suggested configurations for your existing workloads.
READ-INTENSIVE WORKLOAD BENCHMARK
For the read-intensive workload, we used an analytical query benchmark comparing an E7v4 (Broadwell) with 512GiB and 2TiB database cache sizes, against the latest 2nd Generation Intel® Xeon® Scalable Processors (Cascade Lake) with 1TB and 2TB database cache sizes using Intel® Optane™ DC Persistent Memory (DCPMM).
We ran several workloads with varying global buffer sizes to show the impact and performance gain of larger caching. For each configuration iteration we ran a COLD, and a WARM run. COLD is where the database cache was not pre-populated with any data. WARM is where the database cache has already been active and populated with data (or at least as much as it could) to reduce physical reads from disk.
Hardware Configuration
We compared an older 4-Socket E7v4 (aka Broadwell) host to a 4-socket Cascade Lake server with DCPMM. This comparison was chosen because it would demonstrate performance gains for existing customers looking for a hardware refresh along with using InterSystems IRIS. In all tests, the same version of InterSystems IRIS was used so that any software optimizations between versions were not a factor.
All servers have the same storage on the same storage array so that disk performance wasn’t a factor in the comparison. The working set is a 1.2TB database. The hardware configurations are shown in Figure-1 with the comparison between each of the 4-socket configurations:
Figure-1: Hardware configurations
| Server #1 Configuration | Server #2 Configuration |
|---|---|
| Processors: 4 x E7-8890 v4 @ 2.5Ghz | Processors: 4 x Platinum 8280L @ 2.6Ghz |
| Memory: 2TiB DRAM | Memory: 3TiB DCPMM + 768GiB DRAM |
| Storage: 16Gbps FC all-flash SAN @ 2TiB | Storage: 16Gbps FC all-flash SAN @ TiB |
| DCPMM: Memory Mode only |
Benchmark Results and Conclusions
There is a significant reduction in elapsed runtime (approximately 6x) when comparing 512GiB to either 1TiB and 2TiB DCPMM buffer pool sizes. In addition, it was observed that in comparing 2TiB E7v4 DRAM and 2TiB Cascade Lake DCPMM configurations there was a ~20% improvement as well. This 20% gain is believed to be mostly attributed to the new processor architecture and more processor cores given that the buffer pool sizes are the same. However, this is still significant in that in the 4-socket Cascade Lake tested only had 24 x 128GiB DCPMM installed, and can scale to 12TiB DCPMM, which is about 4x the memory of what E7v4 can support in the same 4-socket server footprint.
The following graphs in figure-2 depict the comparison results. In both graphs, the y axis is elapsed time (lower number is better) comparing the results from the various configurations.
Figure-2: Elapse time comparison of various configurations
WRITE-INTENSIVE WORKLOAD BENCHMARK
The workload in this benchmark was our HL7v2 messaging workload using all T4 type workloads.
- The T4 Workload used a routing engine to route separately modified messages to each of four outbound interfaces. On average, four segments of the inbound message were modified in each transformation (1-to-4 with four transforms). For each inbound message four data transformations were executed, four messages were sent outbound, and five HL7 message objects were created in the database.
Each system is configured with 128 inbound Business Services and 4800 messages sent to each inbound interface for a total of 614,400 inbound messages and 2,457,600 outbound messages.
The measurement of throughput in this benchmark workload is “messages per second”. We are also interested in (and recorded) the journal writes during the benchmark runs because transaction journal throughput and latency are critical components in sustaining high throughput. This directly influences the performance of message durability guarantees of IRIS for Health, and the transaction journal write performance is crucial in that operation. When journal throughput suffers, application processes will block on journal buffer availability.
Hardware Configuration
For the write-intensive workload, we decided to use a 2-socket server. This is a smaller configuration than our previous 4-socket configuration in that it only had 192GB of DRAM and 1.5TiB of DCPMM. We compared the workload of Cascade Lake with DCPMM to that of the previous 1st Generation Intel® Xeon® Scalable Processors (Skylake) server. Both servers have locally attached 750GiB Intel® Optane™ SSD DC P4800X drives.
The hardware configurations are shown in Figure-3 with the comparison between each of the 2-socket configurations:
Figure-3: Write intensive workload hardware configurations
| Server #1 Configuration | Server #2 Configuration |
|---|---|
| Processors: 2 x Gold 6152 @ 2.1Ghz | Processors: 2 x Gold 6252 @ 2.1Ghz |
| Memory: 192GiB DRAM | Memory:1.5TiB DCPMM + 192GiB DRAM |
| Storage: 2 x 750GiB P4800X Optane SSDs | Storage: 2 x 750GiB P4800X Optane SSDs |
| DCPMM: Memory Mode & App Direct Modes |
Benchmark Results and Conclusions
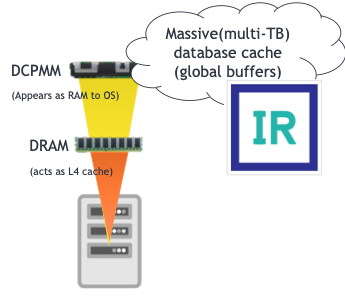
InterSystems IRIS Recommended Intel DCPMM Use Cases
Memory Mode
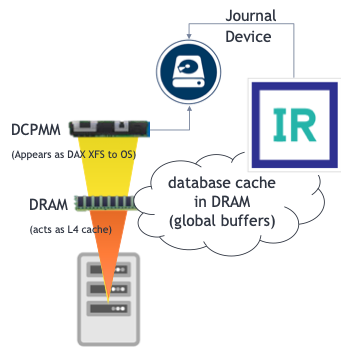
App Direct Mode (DAX XFS) – Journal Disk Device
App Direct Mode (DAX XFS) – Journal + Write Image Journal (WIJ) Disk Device
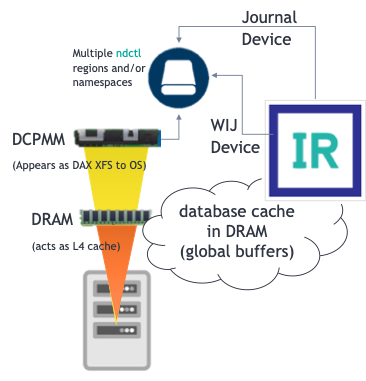
Dual Mode: Memory + App Direct Modes
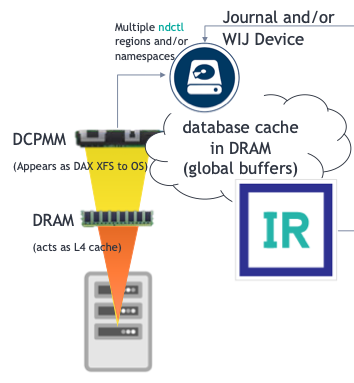
“Quasi” Dual Mode

Conclusion
Increases memory capacity so that multi-terabyte databases can completely reside in InterSystems IRIS or InterSystems IRIS for Health database cache with DCPMM in Memory Mode. In comparison to reading from storage (disks), this can increase query response performance by up six times with no code changes due to InterSystems IRIS proven memory caching capabilities that take advantage of system memory as it increases in size. Improves the performance of high-rate data interoperability throughput applications based on InterSystems IRIS and InterSystems IRIS for Health, such as HL7 transformations, by as much as 60% in increased throughput using the same processors and only changing the transaction journal disk from the fastest available NVMe drives to leveraging DCPMM in App Direct mode as a DAX XFS file system. Exploiting both the memory speed data transfers and data persistence is a significant benefit to InterSystems IRIS and InterSystems IRIS for Health. Augment the compute resources where needed for a given workload whether read or write-intensive, or both, without over-allocating entire servers just for the sake of one resource component with DCPMM in Mixed Mode.
Comments
Great article, Mark!
I have a few notes and questions:
1. Here's a brief comparison of different storage categories:
- Intel® Optane™ DC Persistent Memory has read throughput of 6.8 GB/s and write throughput 1.85 GB/s (source).
- Intel® Optane™ SSD has read throughput of 2.5 GB/s and write throughput of 2.2 GB/s at (source).
- Modern DDR4 RAM has read throughput of ~25 GB/s.
While I certainly see the appeal of DC Persistent Memory if we need more memory than RAM can provide, is it useful on smaller scale? Say I have a few hundred gigabytes of indices I need to keep in global buffer and be able to read-access fast. Would plain DDR4 RAM be better? Costs seem comparable and read throughput of 25 Gb/s seems considerably better.
2. What RAM was used in a Server #1 configuration?
3. Why are there different CPUs between servers?
4. Workload link does not work.
6252 can be used for both DCPM and DRAM configuration.
Correct. Gold 6252 series (aka "Cascade Lake") supports both DCPMM and DRAM. However, keep in mind that when using DCPMM you need to have DRAM and should adhere to at least a 8:1 ratio of DCPMM:DRAM.
Hi Eduard,
Thanks for you questions.
1- On small scale I would stay with traditional DRAM. DCPMM becomes beneficial when >1TB of capacity.
2- That was DDR4 DRAM memory in both read-intensive and write-intensive Server #1 configurations. In the read-intensive server configuration it was specifically DDR-2400, and in the write-intensive server configuration it was DDR-2600.
3- There are different CPUs in configuration in the read-intensive workload because this testing is meant to demonstrate upgrade paths from older servers to new technologies and the scalability increases offered in that scenario. The write-intensive workload only used a different server in the first test to compare previous generation to the current generation with DCPMM. Then the three following results demonstrated the differences in performance within the same server - just different DCPMM configurations.
4- Thanks. I will see what happened to the link and correct.