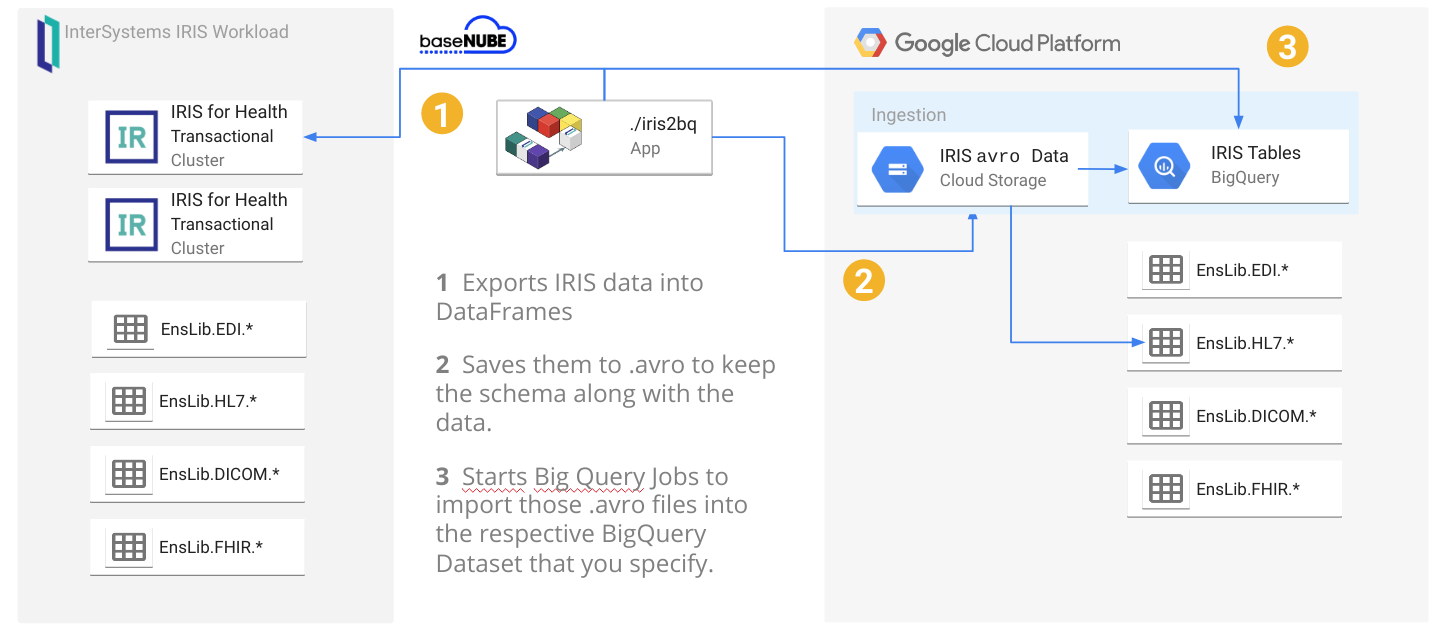
By likes
By likesYour may not realize it, but your InterSystems Login Account can be used to access a very wide array of InterSystems services to help you learn and use InterSystems IRIS and other InterSystems technologies more effectively. Continue reading to learn more about how to unlock new technical knowledge and tools using your InterSystems Login account. Also - after reading, please participate in the Poll at the bottom, so we can see how this article was useful to you!
 Open Exchange app
Open Exchange app