Export InterSystems IRIS Data to BigQuery on Google Cloud Platform
Loading your IRIS Data to your Google Cloud Big Query Data Warehouse and keeping it current can be a hassle with bulky Commercial Third Party Off The Shelf ETL platforms, but made dead simple using the iris2bq utility.
Let's say IRIS is contributing to workload for a Hospital system, routing DICOM images, ingesting HL7 messages, posting FHIR resources, or pushing CCDA's to next provider in a transition of care. Natively, IRIS persists these objects in various stages of the pipeline via the nature of the business processes and anything you included along the way. Lets send that up to Google Big Query to augment and compliment the rest of our Data Warehouse data and ETL (Extract Transform Load) or ELT (Extract Load Transform) to our hearts desire.
A reference architecture diagram may be worth a thousand words, but 3 bullet points may work out a little bit better:
- It exports the data from IRIS into DataFrames
- It saves them into GCS as
.avroto keep the schema along the data: this will avoid to specify/create the BigQuery table schema beforehands. - It starts BigQuery jobs to import those
.avrointo the respective BigQuery tables you specify.
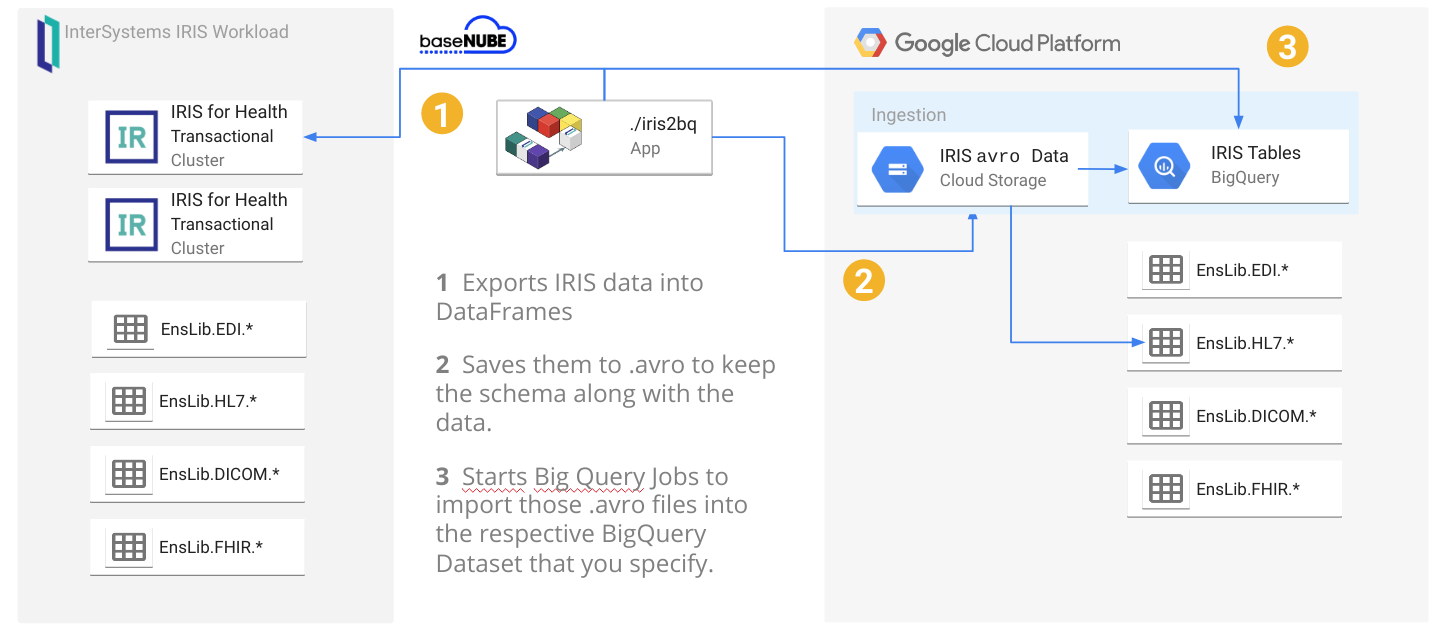
Under the hood, iris2bq it is using the Spark framework for the sake of simplicity, but no Hadoop cluster is needed. It is configured as a "local" cluster by default, meaning the application and is running standalone. The tool is meant to be launched on an interval either through cron or something like Airflow.
All you have to do is point it at your IRIS instance, tell it what tables you want to sync to Big Query, then they magically sync to an existing dataset or a creates a new one that you specify.
How To Setup
And if a reference architecture and 3 bullet points didn't do a good job explaining it, maybe actually running it will:
Google Cloud Setup
You can do this anyway you want, here are a few options for you, but all you have to do in GCP is:
- Create a Project
- Enable the API's of Big Query and Cloud Storage
- Create a service account with access to create resources and download the json file.
Using the Google Cloud Console (Easiest)
Using gcloud (Impress Your Friends):
gcloud projects create iris2bq-demo--enable-cloud-apisWith Terraform (Coolest):
Create a main.tf file after modifying the values:
// Create the GCP Project
resource "google_project" "gcp_project" {
name = "IRIS 2 Big Query Demo"
project_id = "iris2bq-demo"
// You'll need this
org_id = "1234567"
}
// Enable the APIS
resource "google_project_services" "gcp_project_apis" {
project = "iris2bq-demo"
services = ["bigquery.googleapis.com", "storage.googleapis.com"]
}Then do a:
terraform init
terraform plan
terraform applyIRIS Setup
Lets quickly jam some data into IRIS for a demonostration.
Create a class like so:
Class User.People Extends (%Persistent, %Populate)
{
Property ID As %String;
Property FirstName As %String(POPSPEC = "NAME");
Property LastName As %String(POPSPEC = "NAME");
}
Then run the populate to generate some data.
USER>do ##class(User.People).Populate(10000)
Alternatively, you can grab an irissession, ensure you are in the USER namespace and run the following commands.
USER> SET result=$SYSTEM.SQL.Execute("CREATE TABLE People(ID int, FirstName varchar(255), LastName varchar(255))")USER> for i=1:1:100000 { SET result=$SYSTEM.SQL.Execute("INSERT INTO People VALUES ("_i_", 'First"_i_"', 'Last"_i_"')") }Both routes will create a table called "People" and insert 100,000 rows.
Either way you to and if everything worked out, you should be able to query for some dummy rows in IRIS. These are the rows we are sending to Big Query.
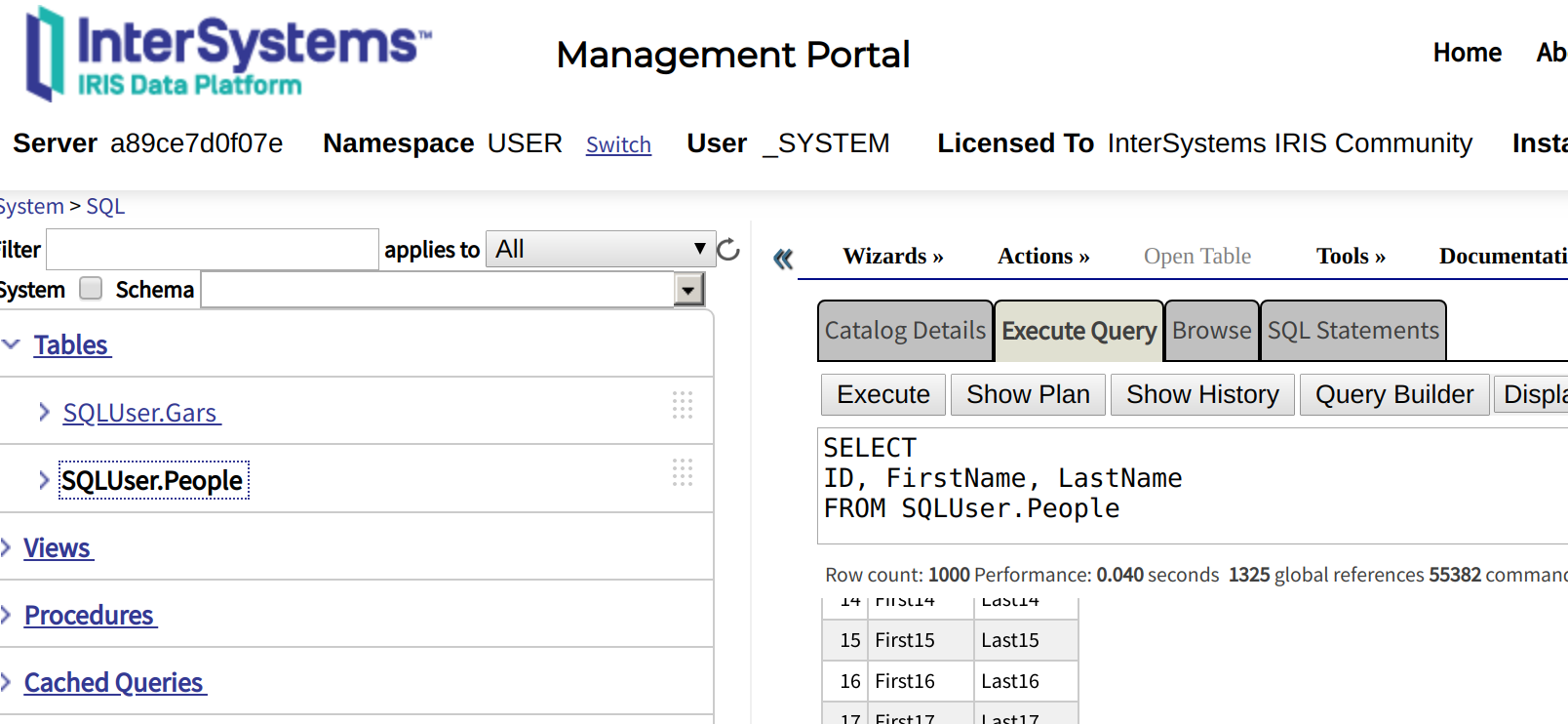
IRIS2BQ Setup
Download the latest release of the utility iris2bq, and unzip it. Then cd to the `bin` directory and move over your credentials to the root of this directory and create an application.conf file as below into the same root.
Taking a look at the below configuration file here, you can get an idea of how the utility works.
- Specify a jdbc url and the credentials for the system user.
- Give it a list of tables that you wan to appear in Big Query.
- Tell the utility which project to point to, the location of your credentials file.
- Then tell it a target Big Query Dataset, and a target bucket to write the .avro files to.
Quick note on the GCP block, the dataset and bucket can either exist or not exist as the utility will create those resources for you.
jdbc {
url = "jdbc:IRIS://127.0.0.1:51773/USER"
user = "_SYSTEM"
password = "flounder" // the password is flounder
tables = [ "people" ] //IRIS tables to send to big query
}
gcloud {
project = "iris2bq-demo"
service-account-key-path = "service.key.json" //gcp service account
bq.dataset = "iris2bqdemods" // target bq dataset
gcs.tmp-bucket = "iris2bqdemobucket" //target storage bucket
}
Run
At this point we should be parked at our command prompt in the root of the utility, with a conf file we created and the json credentials file.

Now that we have all that in place, lets run it and check the result.
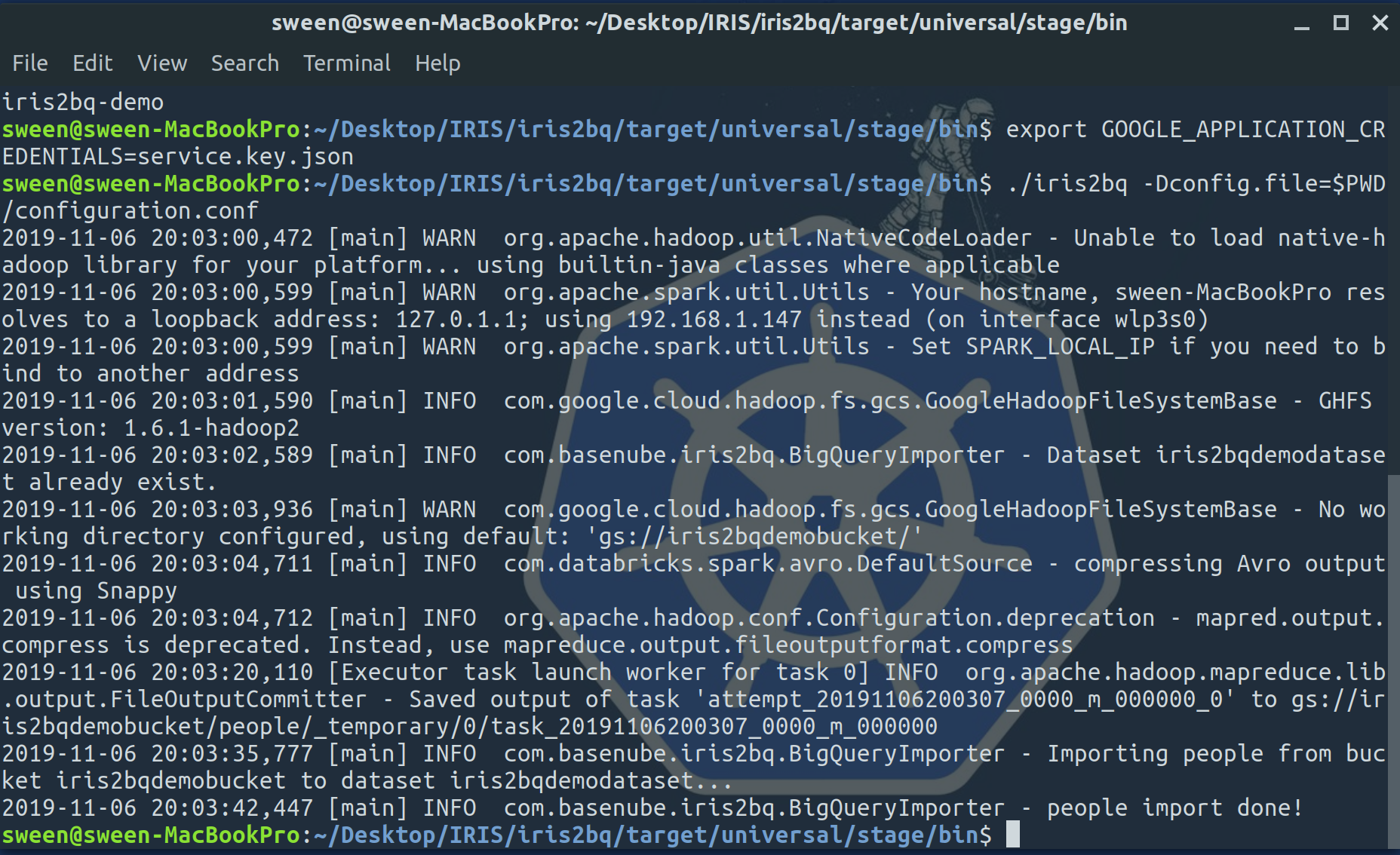
$ export GOOGLE_CLOUD_PROJECT=iris2bq-demo
$ exportGOOGLE_APPLICATION_CREDENTIALS=service.key.json
$./iris2bq -Dconfig.file=configuration.confThe output is a tad chatty, but if the import was successful it will state `people import done!`
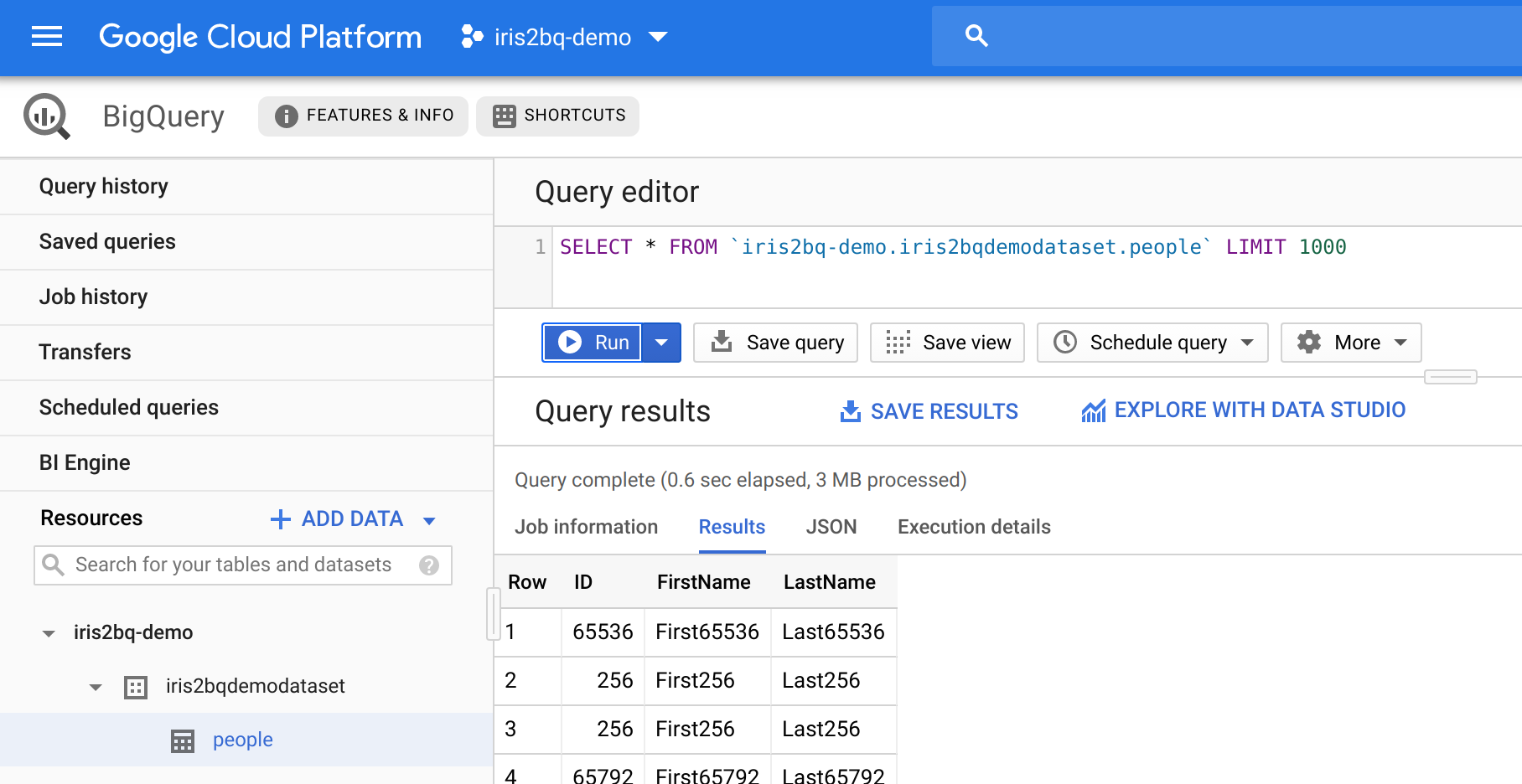
Lets head over to to Big Query and inspect our work...
The baseNUBE team hopes you found this helpful!
Now setup a job to run it on an interval and JOIN all over your IRIS data in Big Query!
Comments
 The article is considered as InterSystems Data Platform Best Practice.
The article is considered as InterSystems Data Platform Best Practice.
Hi Ron,
thanks for this great article.
There's a typo which creates a wondering question about the potentiality of Google Cloud :
Using the Google Cloud Console (Easiest)
fixed, thank you!