Storage Performance Series - Samsung PM1725a NVMe SSD
Continuing on with providing some examples of various storage technologies and their performance profiles, this time we looked at the growing trend of leveraging internal commodity-based server storage, specifically the new HPE Cloudline 3150 Gen10 AMD processor-based single socket servers with two 3.2TB Samsung PM1725a NVMe drives.
Hardware Configuration and Linux LVM Setup
The configuration tested included the following details:
- 2 x Samsung 3.2TB PM1725a NVMe drives (internal to server)
- 1 x HPE Cloudline 3150 Gen10 server
- Red Hat Enterprise Linux 7.5 64-bit
No other storage devices or HBAs where used in this testing.
To maximize IO capabilities of both NVMe disk devices, a single LVM PE stripe was created using 16MB PE size. Details of LVM PE striping setup can be found here in another community article.
InterSystems IRIS Installation and Setup
InterSystems IRIS is installed in the single volume group and single logical volume. In this case we wanted to demonstrate a very simple deployment without the complexity of having multiple volume groups and logical volumes. In our example a single logical volume and file system was created (/data is our file system mount point in this example).
A random read workload from within the database instance is used to generate the IO workload in a progressive number of jobs. A 1TB database is the target of the IO workloads. Details of the RANREAD tool used in this testing can be found here.
Testing Results
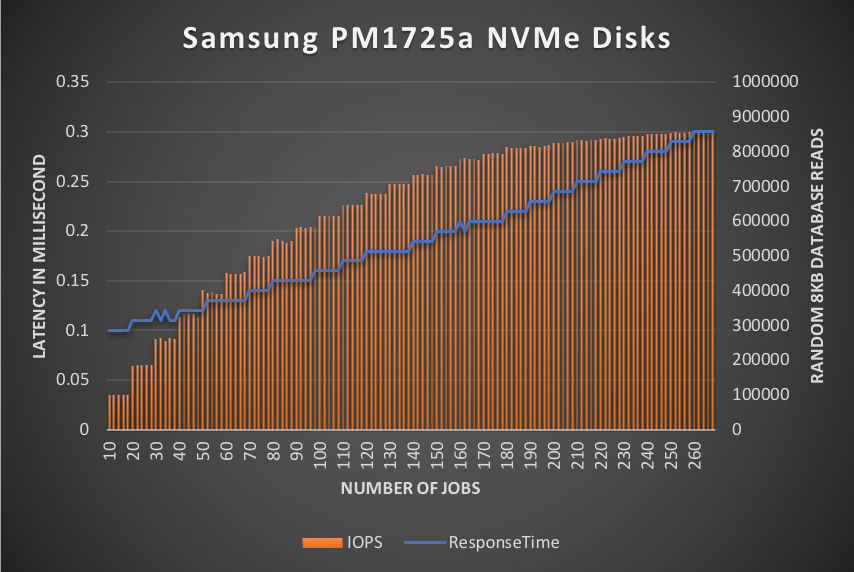
Starting with only 10 jobs, the storage throughput was significant from the start at ~100K 8KB database reads per second at at very low latency of only 100 microseconds (µs). As the number of jobs increased latency remained consistently low until the server actually ran out of CPU capacity to drive the storage any harder. The highest latency observed was only a mere 300µs while sustaining over 850K 8KB database reads per second.
Figure-1 illustrates the predictable performance and sustained throughput for the configuration as tested with only two Samsung NVMe disk devices. Even at the highest levels latency is still very low, and the test server actually ran out of CPU before maximizing throughput of the NVMe disk devices.
Figure-1: Predictable ultra-low latency while sustaining massive throughput
Conclusion
The Samsung PM1725a NVMe disk devices provide extremely low latency and high throughput capability to support a very high performance transactional system. These are ideal for high ingestion workloads where storage latency and throughput are required. Along with this impressive performance profile, these Samsung NVMe disk devices provides a very attractive price point and the same levels of application availability can be achieved when coupled with InterSystems' database mirroring.
Comments
Thanks for the post Mark. I am waiting for something on all flash non NVMe Nutanix setup of 4 nodes and RF2.
Hi Ashish,
We are actively working with Nutanix on a potential example reference architecture, but nothing imminent at this time. The challenges with HCI solutions, Nutanix being one of them, is there is more to the solution that just the nodes themselves. The network topology and switches play a very important role.
Additionally, performance with HCI solutions are good...until they aren't. What I mean by that is performance can be good with HCI/SDDC solutions, however maintaining the expected performance during node failures and/or maintenance periods is the key. Not all SSDs are created equal, so consideration of storage access performance during all situations such as normal operations, failure conditions, and node rebuild/rebalancing is important. Also data locality plays a large role too with HCI, and in some HCI solution so does the working dataset size (ie - the larger the data set and random access patterns to that data can have an adverse and unexpected impact on storage latency).
Here's a link to an article I authored regarding our current experiences and general recommendations with HCI and SDDC-based solutions.
So, in general, be careful when considering any HCI/SDDC solution to not fall into the HCI marketing hype or promises of being "low cost". Be sure to consider failure/rebuild scenarios when sizing you HCI cluster. Many times the often quoted "4-node cluster" just isn't ideal and more nodes may be necessary to support performance during failure/maintenance situations within a cluster. We have come across many of these situations, so test test test. :)
Kind regards,
Mark B