If you're running IRIS in a mirrored configuration for HA in GCP, the question of providing a Mirror VIP (Virtual IP) becomes relevant. Virtual IP offers a way for downstream systems to interact with IRIS using one IP address. Even when a failover happens, downstream systems can reconnect to the same IP address and continue working.
The main issue, when deploying to GCP, is that an IRIS VIP has a requirement of IRIS being essentially a network admin, per the docs.
To get HA, IRIS mirror members must be deployed to different availability zones in one subnet (which is possible in GCP as subnets always span the entire region). One of the solutions might be load balancers, but they, of course, cost extra, and you need to administrate them.
In this article, I would like to provide a way to configure a Mirror VIP without using Load Balancers suggested in most other GCP reference architectures.
 By views
By views
 Open Exchange app
Open Exchange app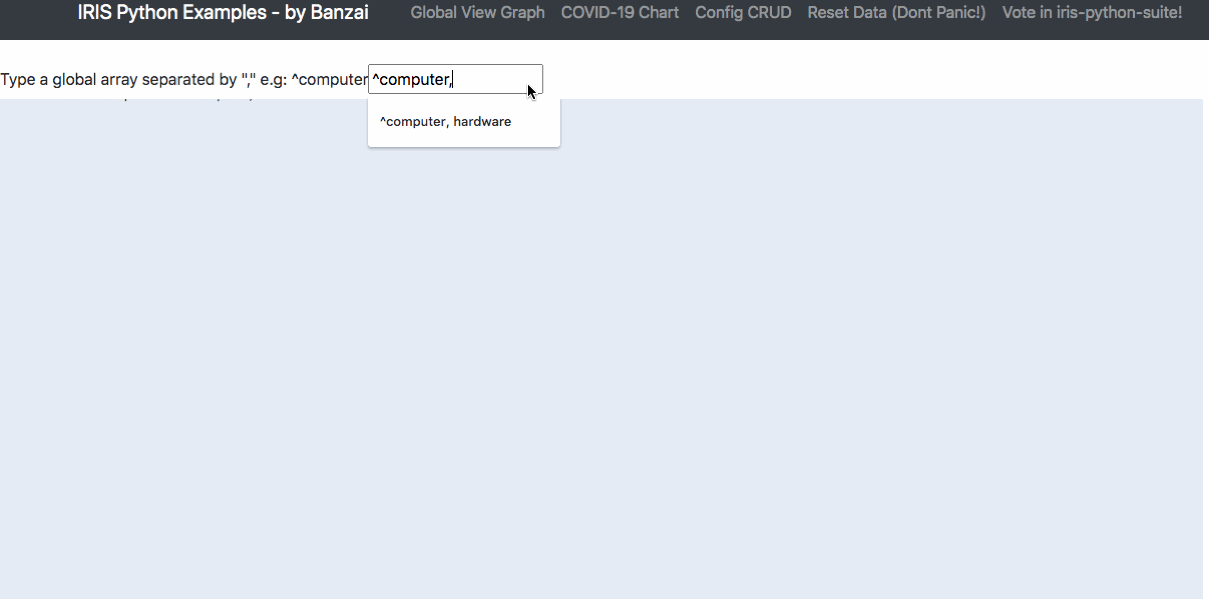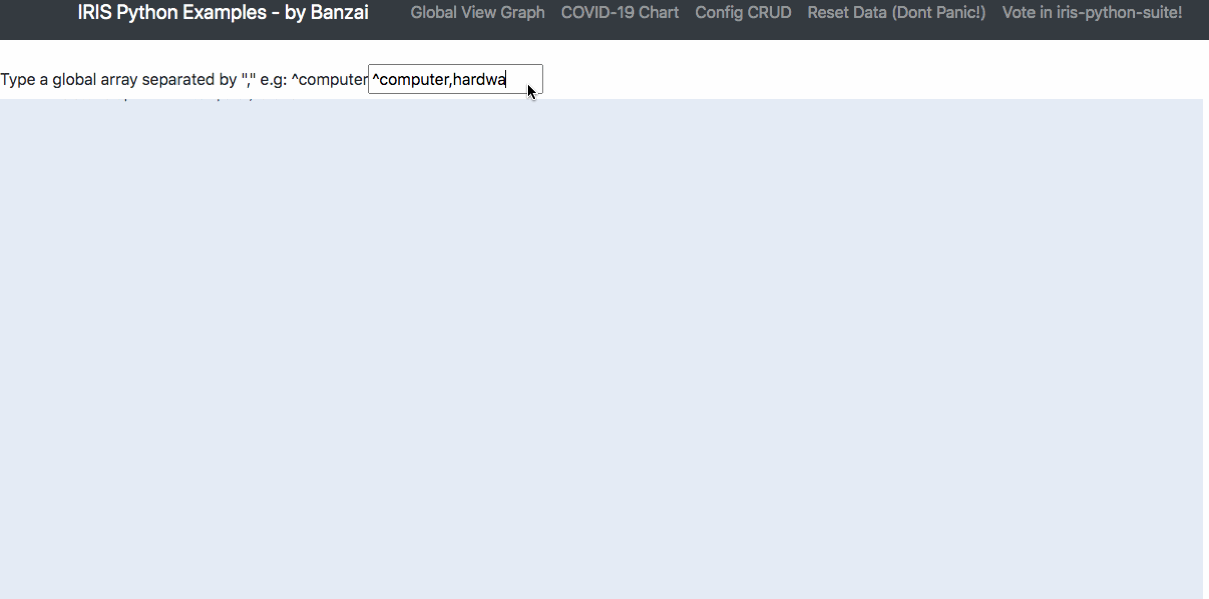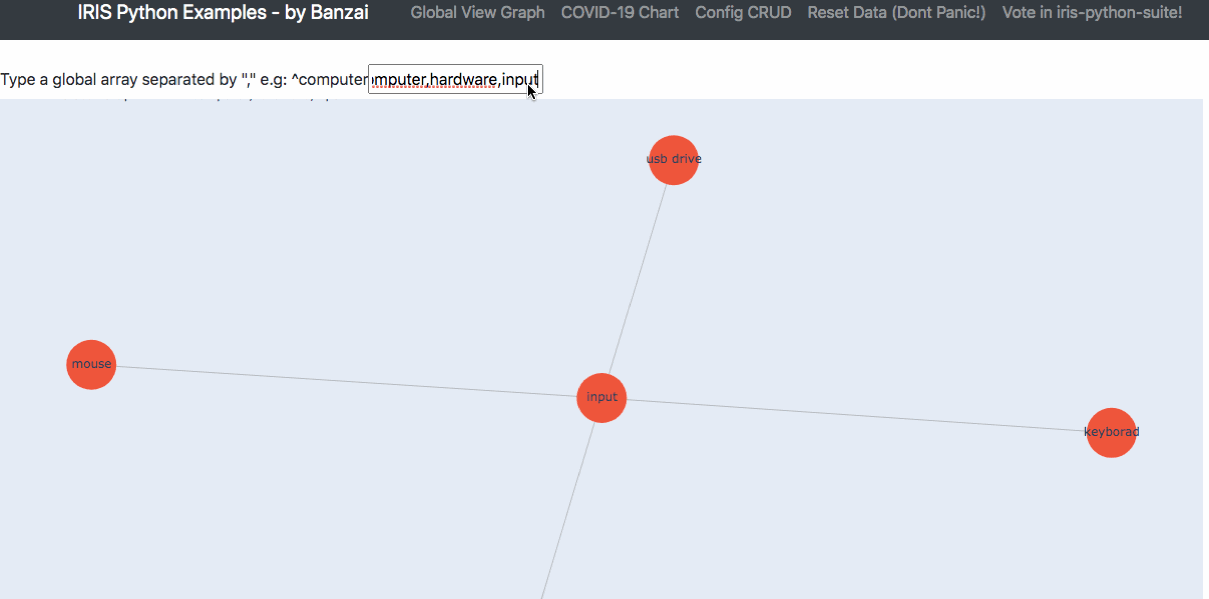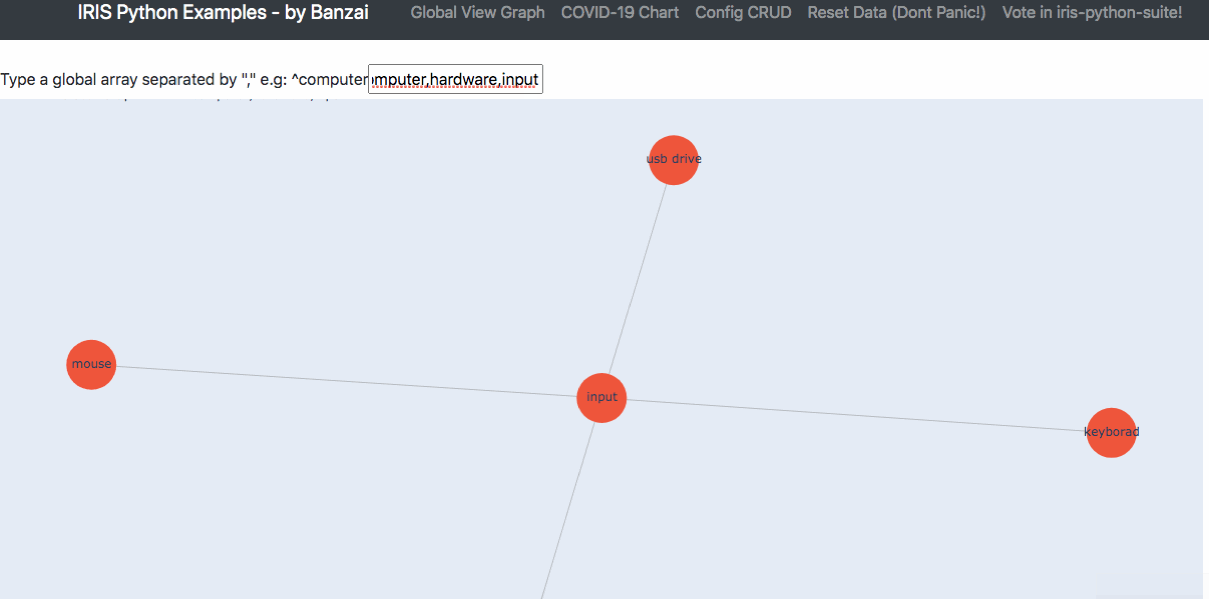



 ).
).