Hi everyone!
We’re currently determining the passing score for this exam and expect to publish it in late March or early April. Pass / fail notification emails for beta testers will also be sent out around that time!
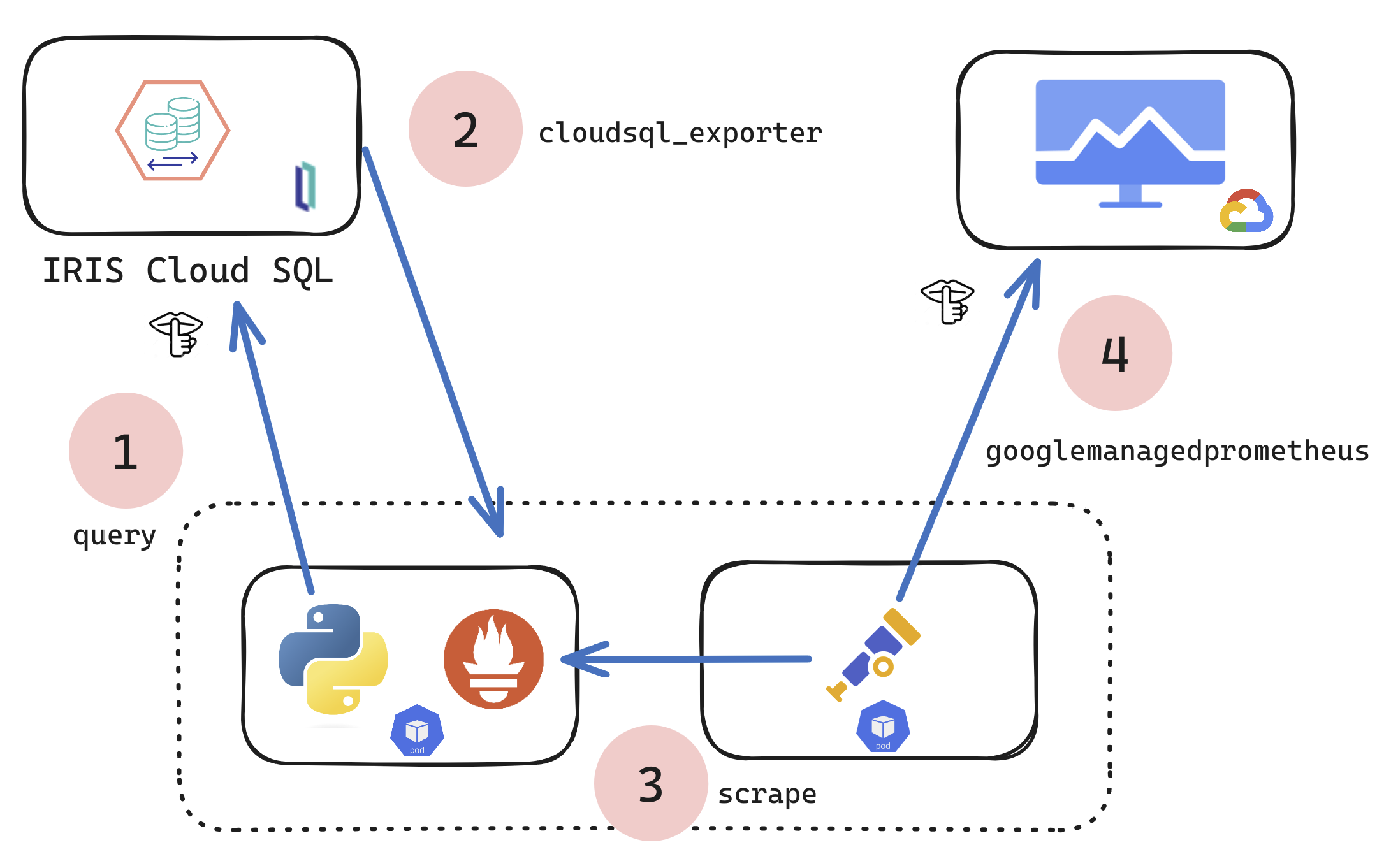
For candidates interested in taking the SQL Professional exam at Ready 2026, please see the preparation materials and exam topics below.
.png)
.png)

.png)
