InterSystems for dummies – Machine learning II

Previously, we trained our model using machine learning. However, the sample data we utilized was generated directly from insert statements.
Today, we will learn how to load this data straight from a file.
Dump Data
Before dumping the data from your file, check what header the fields have.
In this case, the file is called “Sleep_health_and_lifestyle_dataset.csv” and is located in the data/csv folder.
This file contains 374 records plus a header (375 lines).
The header includes the following names and positions:
- Person ID
- Gender
- Age
- Occupation
- Sleep Duration
- Quality of Sleep
- Physical Activity Level
- Stress Level
- BMI Category
- Systolic
- Diastolic
- Heart Rate
- Daily Steps
- Sleep Disorder
It is essential to know the names of column headers.
The class St.MLL.insomnia02 has different column names; therefore, we need to load the data indicating the name of the column into the file, while the relation with the column is placed in the table.
LOAD DATA FROM FILE '/opt/irisbuild/data/csv/Sleep_health_and_lifestyle_dataset.csv'
INTO St_MLL.insomnia02
(Gender,Age,Occupation,SleepDuration,QualitySleep,PhysicalActivityLevel,
StressLevel,BMICategory,Systolic,Diastolic,HeartRate,DailySteps,SleepDisorder)
VALUES ("Gender","Age","Occupation","Sleep Duration","Quality of Sleep","Physical Activity Level",
"Stress Level","BMI Category","Systolic","Diastolic","Heart Rate","Daily Steps","Sleep Disorder")
USING {"from":{"file":{"header":true}}}

All the information makes sense, but… What is the last instruction?
{
"from": {
"file": {
"header": true
}
}
}
This is an instruction for the LOAD DATA command to determine what the file is (whether or not it has a header; whether the column separator is another character, etc).
You can find more information about the JSON options by checking out the following links:
Since the columns of the file do not match those in the tables, it is necessary to indicate that the document has a line with the header, because by default, this value is “false”.
Now, we will drill our model once more. With much more data in hand, it will be way more efficient at this point.
TRAIN MODEL insomnia01AllModel FROM St_MLL.insomnia02
TRAIN MODEL insomnia01SleepModel FROM St_MLL.insomnia02
TRAIN MODEL insomnia01BMIModel FROM St_MLL.insomnia02
Populate the St_MLL.insomniaValidate02 table with 50% of St_MLL.insomnia02 rows:
INSERT INTO St_MLL.insomniaValidate02(
Age, BMICategory, DailySteps, Diastolic, Gender, HeartRate, Occupation, PhysicalActivityLevel, QualitySleep, SleepDisorder, SleepDuration, StressLevel, Systolic)
SELECT TOP 187
Age, BMICategory, DailySteps, Diastolic, Gender, HeartRate, Occupation, PhysicalActivityLevel, QualitySleep, SleepDisorder, SleepDuration, StressLevel, Systolic
FROM St_MLL.insomnia02
Validate the models with the newly validated table:
INSERT INTO St_MLL.insomniaTest02(
Age, BMICategory, DailySteps, Diastolic, Gender, HeartRate, Occupation, PhysicalActivityLevel, QualitySleep, SleepDisorder, SleepDuration, StressLevel, Systolic)
SELECT TOP 50
Age, BMICategory, DailySteps, Diastolic, Gender, HeartRate, Occupation, PhysicalActivityLevel, QualitySleep, SleepDisorder, SleepDuration, StressLevel, Systolic
FROM St_MLL.insomnia02
Proceeding with our previous model (a nurse, 29-year-old, female), we can check what prediction our test table will make.
Note: The following queries will be focused exclusively on this type of person.
SELECT *, PREDICT(insomnia01AllModel) FROM St_MLL.insomnia02
WHERE age = 29 and Gender = 'Female' and Occupation = 'Nurse'
 SURPRISE!!! The result is identical to the one with less data. We thought that training our model with more data would improve the outcome, but we were wrong.
SURPRISE!!! The result is identical to the one with less data. We thought that training our model with more data would improve the outcome, but we were wrong.
For a change, I executed the probability query instead, and I got a pretty interesting result:
SELECT Gender, Age, SleepDuration, QualitySleep, SleepDisorder, PREDICT(insomnia01SleepModel) As SleepDisorderPrediction, PROBABILITY(insomnia01SleepModel FOR 'Insomnia') as ProbabilityInsomnia,
PROBABILITY(insomnia01SleepModel FOR 'Sleep Apnea') as ProbabilityApnea
FROM St_MLL.insomniaTest02
WHERE age = 29 and Gender = 'Female' and Occupation = 'Nurse'

According to the data (sex, age, sleep quality, and sleep duration), the probability of having insomnia is only 46.02%, whereas the chance of having sleep apnea is 51.46%.
Our previous data training provided us with the following percentages: insomnia - 34.63%, and sleep apnea - 64.18%.
What does it mean? The more data we have, the more accurate results we obtain.
Time Is Money
Now, let's try another type of training, using the time series.
Following the same steps we took to build the insomnia table, I created a class called WeatherBase:
Class St.MLL.WeatherBase Extends %Persistent
{
/// Date and time of the weather observation in New York City
Property DatetimeNYC As %DateTime;
/// Measured temperature in degrees
Property Temperature As %Numeric(SCALE = 2);
/// Apparent ("feels like") temperature in degrees
Property ApparentTemperature As %Numeric(SCALE = 2);
/// Relative humidity (0 to 1)
Property Humidity As %Numeric(SCALE = 2);
/// Wind speed in appropriate units (e.g., km/h)
Property WindSpeed As %Numeric(SCALE = 2);
/// Wind direction in degrees
Property WindBearing As %Numeric(SCALE = 2);
/// Visibility distance in kilometers
Property Visibility As %Numeric(SCALE = 2);
/// Cloud cover fraction (0 to 1)
Property LoudCover As %Numeric(SCALE = 2);
/// Atmospheric pressure in appropriate units (e.g., hPa)
Property Pressure As %Numeric(SCALE = 2);
}
Then, I built two classes extending from WeatherBase (Weather and WeatherTest). It allowed me to have the same columns for both tables.
There is a file named “NYC_WeatherHistory.csv” in the csv folder. It contains the temperature, humidity, wind speed, and pressure for New York City in 2015. It is a fortune of data!! For that reason, we will load the file into our table using the knowledge about how to load data from a file.
LOAD DATA FROM FILE '/opt/irisbuild/data/csv/NYC_WeatherHistory.csv'
INTO St_MLL.Weather
(DatetimeNYC,Temperature,ApparentTemperature,Humidity,WindSpeed,WindBearing,Visibility,LoudCover,Pressure)
VALUES ("DatetimeNYC","Temperature","ApparentTemperature","Humidity","WindSpeed","WindBearing","Visibility","LoudCover","Pressure")
USING {"from":{"file":{"header":true}}}

📣NOTE: The names of the columns and the fields in the table are the same, therefore, we can use the following sentence instead.
LOAD DATA FROM FILE '/opt/irisbuild/data/csv/NYC_WeatherHistory.csv'
INTO St_MLL.Weather
USING {"from":{"file":{"header":true}}}Now we will create our model, but we will do it in a particular way.
CREATE TIME SERIES MODEL WeatherForecast
PREDICTING (Temperature, Humidity, WindSpeed, Pressure)
BY (DatetimeNYC) FROM St_MLL.Weather
USING {"Forward":3}
If we wish to create a prediction series, we should take into account the recommendations below:
- The date field must be datetime.
- Try to sort the data chronologically.
The latest command, USING {"Forward":3}, sets the timesteps for the time series.
This parameter has other values:
forward specifies the number of timesteps in the future that you would like to foresee as a positive integer. Approximated rows will appear after the latest time or date in the original dataset. However, you may specify both this and the backward setting simultaneously.
Example: USING {"Forward":3}
backward defines the number of timesteps in the past that you would like to predict as a positive integer. Forecasted rows will appear before the earliest time or date in the original dataset. Remember that you can indicate both this and the forward setting at the same time. The AutoML provider ignores this parameter.
Example: USING {"backward":5}
frequency determines both the size and unit of the predicted timesteps as a positive integer followed by a letter that denotes the unit of time. If this value is not appointed, the most common timestep in the data is supplied.
Example: USING {"Frequency":"d"}
This parameter is case-insensitive.
The letter abbreviations for units of time are outlined in the following table:
|
Abbreviation |
Unit of Time |
|
y |
year |
|
m |
month |
|
w |
week |
|
d |
day |
|
h |
hour |
|
t |
minute |
|
s |
second |
Now… training. You already know the command for that:
TRAIN MODEL WeatherForecast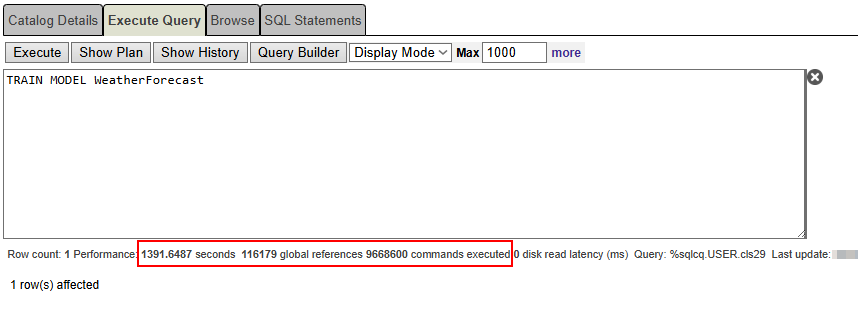
Be patient! This training took 1391 seconds, wich is approximately 23 minutes!!!!
Now, populate the table St_MLL.WeatherTest with the command Populate.
Do ##class(St.MLL.WeatherTest).Populate()It includes the first 5 days of January 2025. When completed, select the prediction using the model and the test table.
SELECT WITH PREDICTIONS (WeatherForecast) * FROM St_MLL.WeatherTest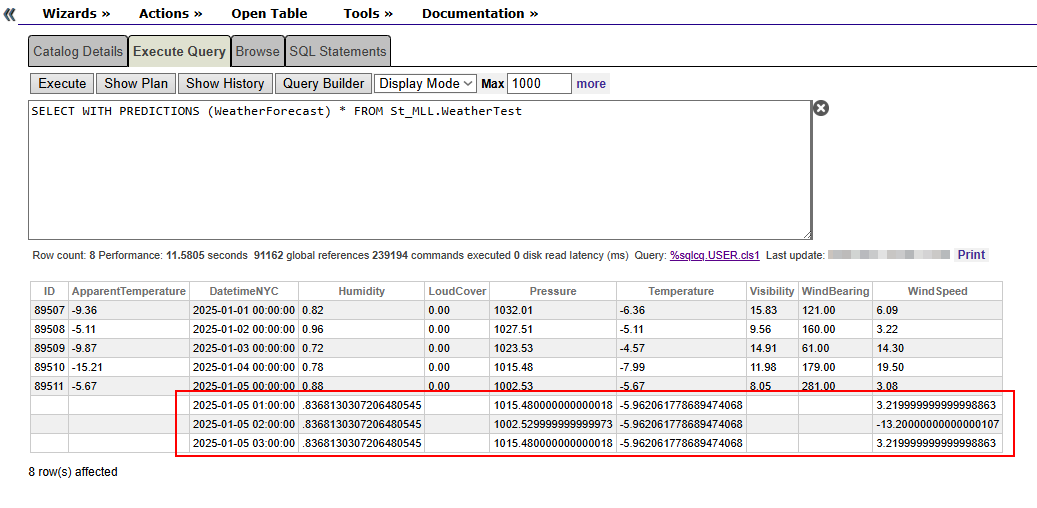 Well, it is showing us the forecast for the next 3 hours on January 2, 2025. This happens because we defined our model to forecast 3 records ahead. However, our data model has data for every hour of every day (00:00, 01:00, 02:00, etc.)
Well, it is showing us the forecast for the next 3 hours on January 2, 2025. This happens because we defined our model to forecast 3 records ahead. However, our data model has data for every hour of every day (00:00, 01:00, 02:00, etc.)
If we want to see the daily outlook, we should create another model trained to do so by the day.
Let's create the following model to see the 5-day forecast.
CREATE TIME SERIES MODEL WeatherForecastDaily
PREDICTING (Temperature, Humidity, WindSpeed, Pressure)
BY (DatetimeNYC) FROM St_MLL.Weather
USING {"Forward":5, "Frequency":"d"}
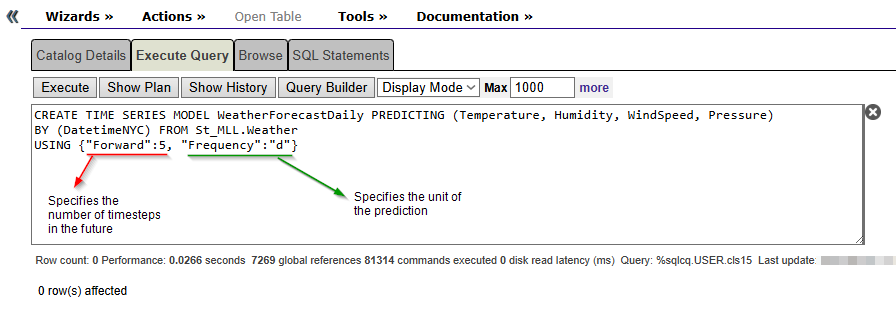
Now, repeat the same steps… training and displaying the forecast:
TRAIN MODEL WeatherForecastDaily
SELECT WITH PREDICTIONS (WeatherForecastDaily) * FROM St_MLL.WeatherTest
Wait! This time, it throws out the following error:
[SQLCODE: <-400>:<Fatal error occurred>][%msg: <PREDICT execution error: ERROR #5002: ObjectScript error: <PYTHON EXCEPTION> *<class 'ValueError'>: forecast_length is too large for training data. What this means is you don't have enough history to support cross validation with your forecast_length. Various solutions include bringing in more data, alter min_allowed_train_percent to something smaller, and also setting a shorter forecast_length to class init for cross validation which you can then override with a longer value in .predict() This error is also often caused by errors in inputing of or preshaping the data. Check model.df_wide_numeric to make sure data was imported correctly. >]
What has happened?
As the error says, it is due to the lack of data to make a prediction. You might think that it needs more data in the Weather table and training, but it has 8760 records… so what is wrong?
If we want to forecast the weather for a large number of days, we need a lot of data in the model. Filling all the data into a table requires extensive training time and a very powerful PC. Therefore, since this is a basic tutorial, we will build a model for 3 days only.
Don’t forget to remove the model WeatherForecastDaily before following the instructions.
DROP MODEL WeatherForecastDailyI am not going to include all the images of those changes, but I will give you the instructions on what to do:
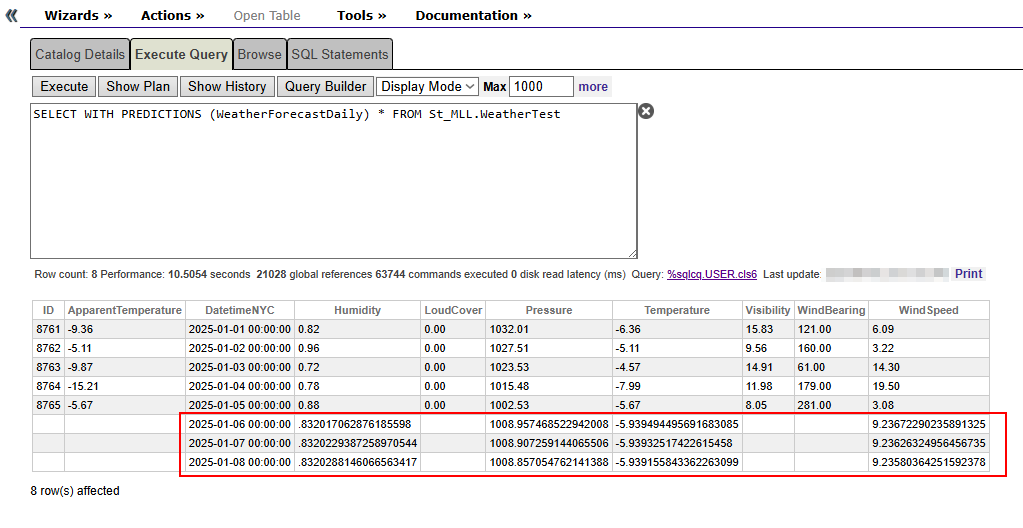
CREATE TIME SERIES MODEL WeatherForecastDaily
PREDICTING (Temperature, Humidity, WindSpeed, Pressure)
BY (DatetimeNYC) FROM St_MLL.Weather
USING {"Forward":3, "Frequency":"d"}
TRAIN MODEL WeatherForecastDaily
SELECT WITH PREDICTIONS (WeatherForecastDaily) * FROM St_MLL.WeatherTest
 Important Note
Important Note
The Docker container containers.intersystems.com/intersystems/iris-community-ml:latest-em is no longer available, so you have to use the iris-community container.
This container is not initialized with the AutoML configuration, so the following statement will need to be executed first:
pip install --index-url https://registry.intersystems.com/pypi/simple --no-cache-dir --target /usr/irissys/mgr/python intersystems-iris-automlIf you are using a Dockerfile to deploy your Docker image, remember to add the command below to the deployment instructions:
ARG IMAGE=containers.intersystems.com/intersystems/iris-community:latest-em
FROM $IMAGE
USER root
WORKDIR /opt/irisbuild
RUN chown ${ISC_PACKAGE_MGRUSER}:${ISC_PACKAGE_IRISGROUP} /opt/irisbuild
RUN pip install --index-url https://registry.intersystems.com/pypi/simple --no-cache-dir --target /usr/irissys/mgr/python intersystems-iris-automl
For more information, please visit the website below: