By likes
By likes
 Open Exchange app
Open Exchange appIntroduction
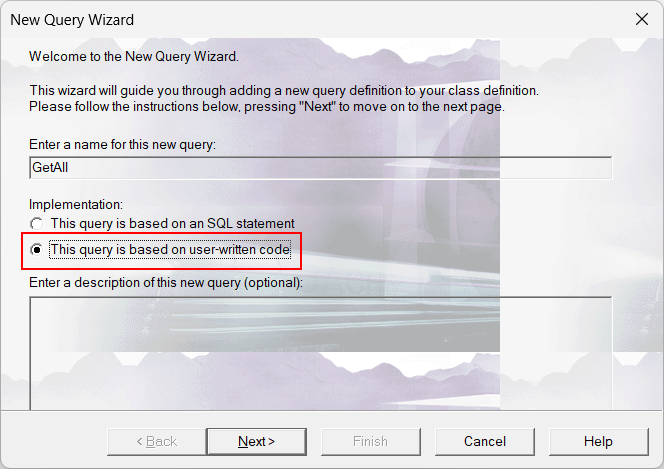
The common requirement in many applications is logging of data changes in a database - which data has changed, who changed them and when (audit logging). There are many articles about this question and there are different approaches on how to do that in Caché.