 By likes
By likesAdding VSCode into your IRIS container
One of the easiest ways to setup repeatable development environments is to spin up containers for them. I find that when iterating quickly, it was very convenient to host a vscode instance within my development container. Thus, I have created a quick container script to add a browser-based vscode into an IRIS container. This should work for most 2021.1+ containers. My code repository can be found here
 Open Exchange app
Open Exchange app (*)
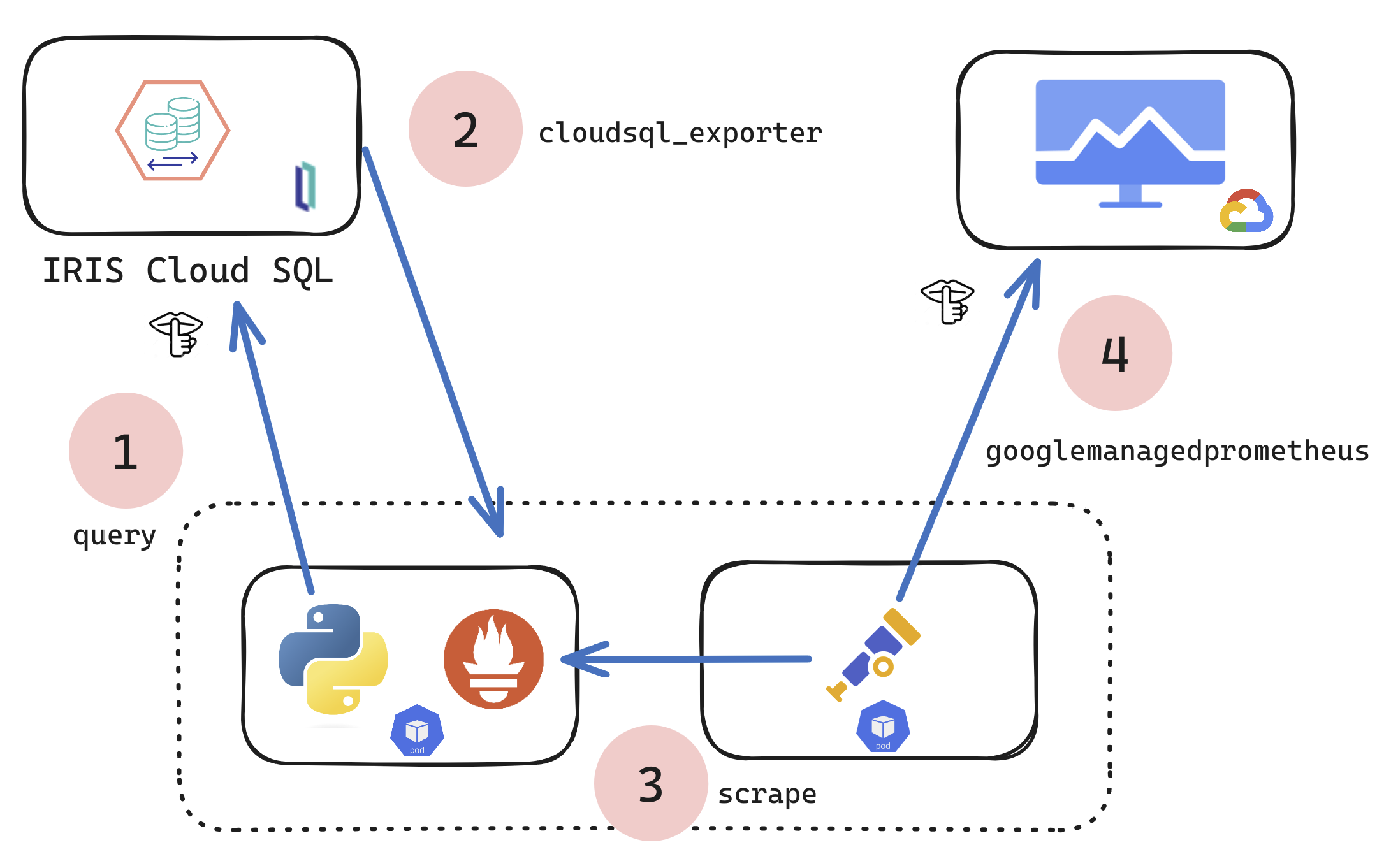
(*)
.png)