 By update
By updateInterSystems IRIS has quite a few different kinds properties. Let’s put them in order so that they make better sense.
First of all, I would divide them into categories:
- Atomic or simple properties (all those %String, %Integer, %Data and other system or user datatypes)
- References to stored objects
- Built-in objects
- Streams (both binary and character)
- Collections (which are divided into arrays and lists)
- Relationships (one-many and parent-children)
Some of these kinds of properties are quite straightforward. For example, atomic properties:
Property Name As %Name;
Property DoB As %Date
Property Age As %Integer Open Exchange app
Open Exchange app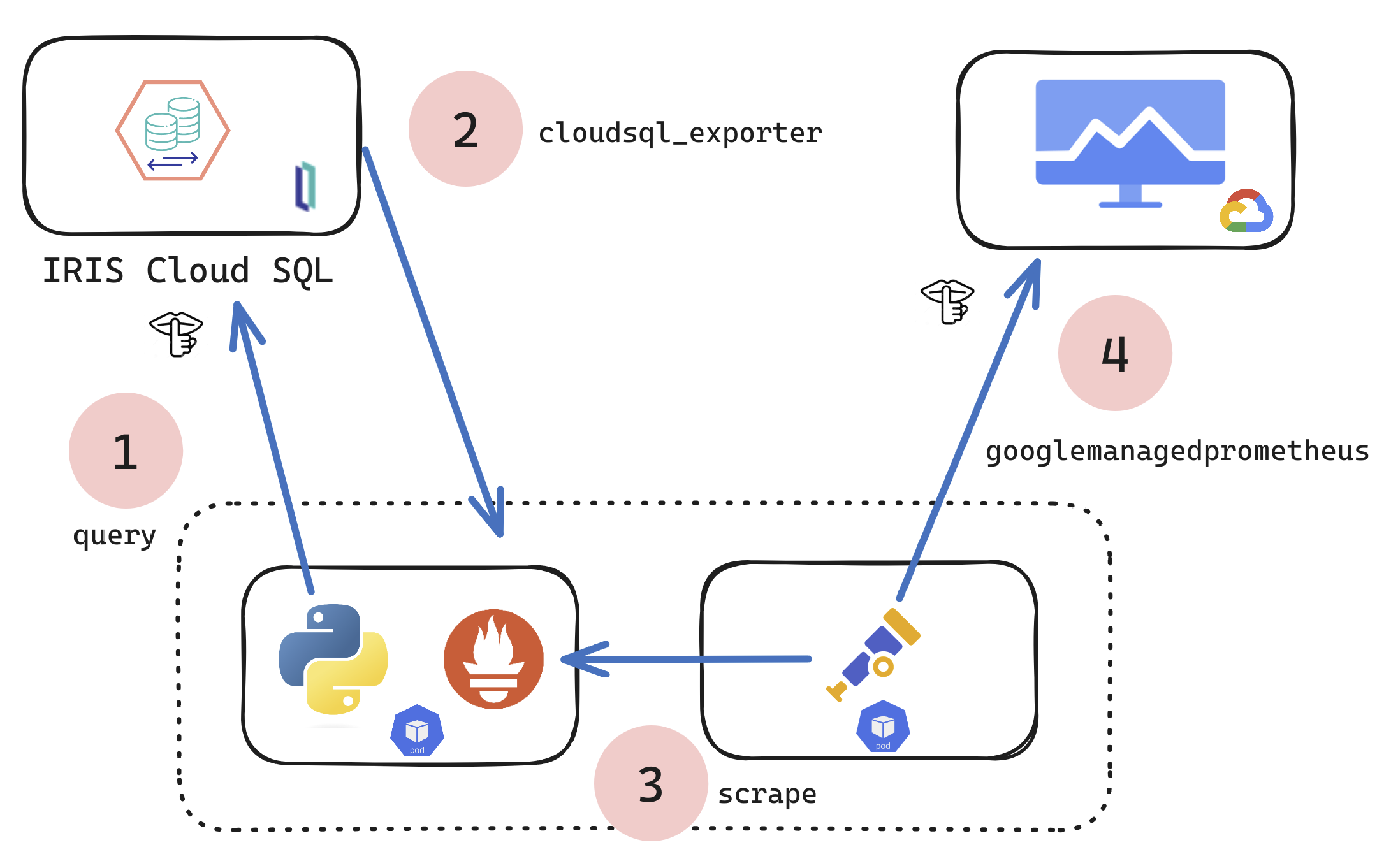
.png)
.png)
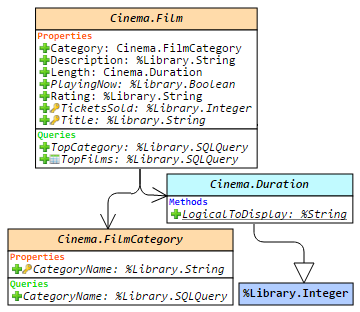 Hello!
Hello!
