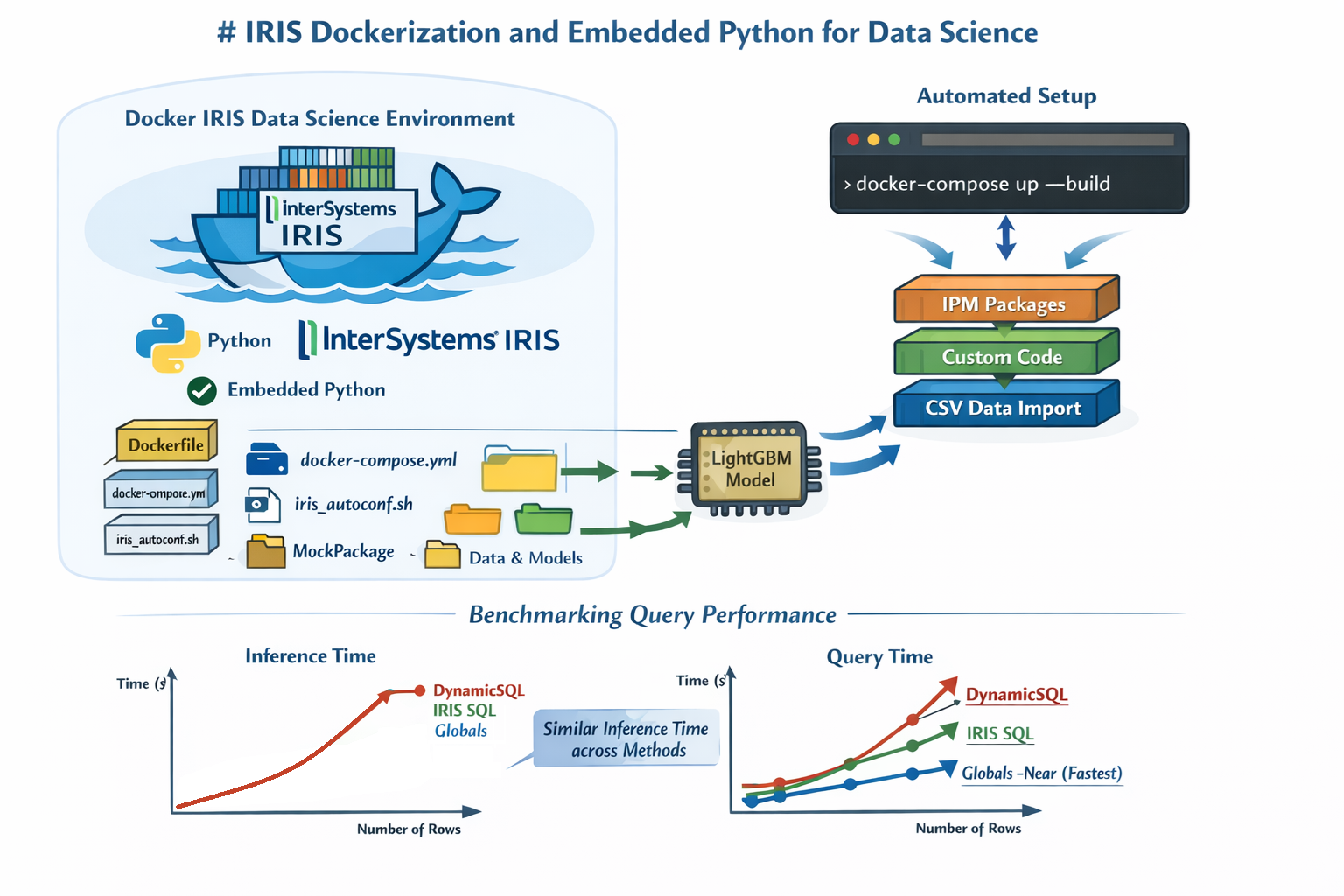
Hello community,
I wanted to share my experience about working on Large Data projects. Over the years, I have had the opportunity to handle massive patient data, payor data and transactional logs while working in an hospital industry. I have had the chance to build huge reports which had to be written using advanced logics fetching data across multiple tables whose indexing was not helping me write efficient code.
Here is what I have learned about managing large data efficiently.
Choosing the right data access method.
As we all here in the community are aware of, IRIS provides multiple ways to access data. Choosing the right method, depends on the requirement.
- Direct Global Access: Fastest for bulk read/write operations. For example, if i have to traverse through indexes and fetch patient data, I can loop through the globals to process millions of records. This will save a lot of time.
Set ToDate=+H
Set FromDate=+$H-1 For Set FromDate=$O(^PatientD("Date",FromDate)) Quit:FromDate>ToDate Do
. Set PatId="" For Set PatId=$Order(^PatientD("Date",FromDate,PatID)) Quit:PatId="" Do
. . Write $Get(^PatientD("Date",FromDate,PatID)),!- Using SQL: Useful for reporting or analytical requirements, though slower for huge data sets.