Loading your IRIS Data to your Google Cloud Big Query Data Warehouse and keeping it current can be a hassle with bulky Commercial Third Party Off The Shelf ETL platforms, but made dead simple using the iris2bq utility.
Let's say IRIS is contributing to workload for a Hospital system, routing DICOM images, ingesting HL7 messages, posting FHIR resources, or pushing CCDA's to next provider in a transition of care. Natively, IRIS persists these objects in various stages of the pipeline via the nature of the business processes and anything you included along the way. Lets send that up to Google Big Query to augment and compliment the rest of our Data Warehouse data and ETL (Extract Transform Load) or ELT (Extract Load Transform) to our hearts desire.
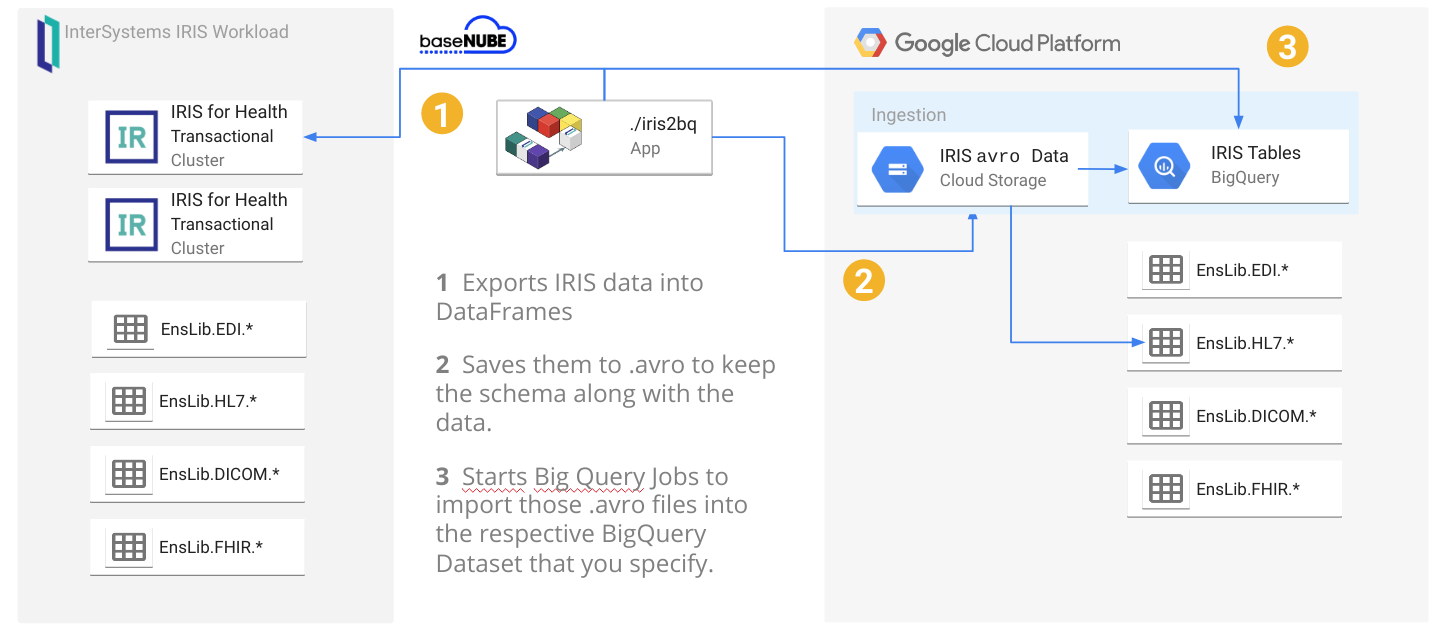
A reference architecture diagram may be worth a thousand words, but 3 bullet points may work out a little bit better:
- It exports the data from IRIS into DataFrames
- It saves them into GCS as
.avro to keep the schema along the data: this will avoid to specify/create the BigQuery table schema beforehands.
- It starts BigQuery jobs to import those
.avro into the respective BigQuery tables you specify.