Artificial Intelligence (AI) is the simulation of human intelligence processes by machines, especially computer systems. These processes include learning (the acquisition of information and rules for using the information), reasoning (using rules to reach approximate or definite conclusions) and self-correction.
As you may know, our Developer Community AI has been out for over a month now 🎉 We hope you were curious enough to give it a try 😁 If you haven't yet, please do! Anyway, since it's still in beta, we're very interested in learning what you think about it, and we look forward to hearing your thoughts and experiences.
Since we value your time and effort, we will give away a cute prize to a random member of the Community who shares how DC AI helped you. To participate in this sweepstakes, you have to follow the guidelines:
This is my introduction to a series of posts explaining how to create an end-to-end Machine Learning system.
Starting with one problem
Our IRIS Development Community has several posts without tags or wrong tagged. As the posts keep growing the organization
of each tag and the experience of any community member browsing the subjects tends to decrease.
First solutions in mind
We can think some usual solutions for this scenario, like:
Last week, we announced the InterSystems IRIS Data Platform, our new and comprehensive platform for all your data endeavours, whether transactional, analytics or both. We've included many of the features our customers know and loved from Caché and Ensemble, but in this article we'll shed a little more light on one of the new capabilities of the platform: SQL Sharding, a powerful new feature in our scalability story.
This series of articles would cover Python Gateway for InterSystems Data Platforms. Leverage modern AI/ML tools and execute Python code and more from InterSystems IRIS. This project brings you the power of Python right into your InterSystems IRIS environment:
This is the third post of a series explaining how to create an end-to-end Machine Learning system.
Training a Machine Learning Model
When you work with machine learning is common to hear this work: training. Do you what training mean in a ML Pipeline?
Training could mean all the development process of a machine learning model OR the specific point in all development process
that uses training data and results in a machine learning model.
We have more exciting news! The new InterSystems online programming contest dedicated to Generative AI, Vector Search and Machine Learning is starting very soon!
Fast transfer. Pass globals, classes and tables from InterSystems IRIS to Python with ease and speed (10x faster than old QueryExecute). Documentation.
We're pleased to invite you to the InterSystems AI+ML Summit 2021, which will be held virtually from January 25 to February 4! Join us for a two-week event that ranges from thought leadership to technical sessions and even 1:1 “Ask the Expert” sessions.
The sessions will be in both German and English. And this summit is free to attend!
Do you resonate with this - A capability and impact of a technology being truly discovered when it's packaged in a right way to it's audience. Finest example would be, how the Generative AI took off when ChatGPT was put in the public for easy access and not when Transformers/RAG's capabilities were identified. At least a much higher usage came in, when the audience were empowered to explore the possibilities.
As you all know, the world of artificial intelligence is already here, and everyone wants to use it to their benefit.
There are many platforms that offer artificial intelligence services for free, by subscription or private ones. However, the one that stands out because of the amount of "noise" it made in the world of computing is Open AI, mainy thanks to its most renowned services: ChatGPT and DALL-E.
I' have done some tests with Caché and Apache Zeppelin. I want to share my experince to use both systems together. I'll try to describe all steps that are required to config Zeppelin to connect to Caché.
Artificial Intelligence (AI) is getting a lot of attention lately because it can change many areas of our lives. Better computer power and more data have helped AI do amazing things, like improving medical tests and making self-driving cars. AI can also help businesses make better decisions and work more efficiently, which is why it's becoming more popular and widely used. How can one integrate the OpenAI API calls into an existing IRIS Interoperability application?
Round 2 of the GenAI Crowdsourcing Mini-Contest is here! Everyone can join, even if you missed Round 1. You have $5 million in fantasy funds to invest in up to 5 promising submissions.
 By replies
By replies




 Open Exchange app
Open Exchange app.jpg)
.jpg)

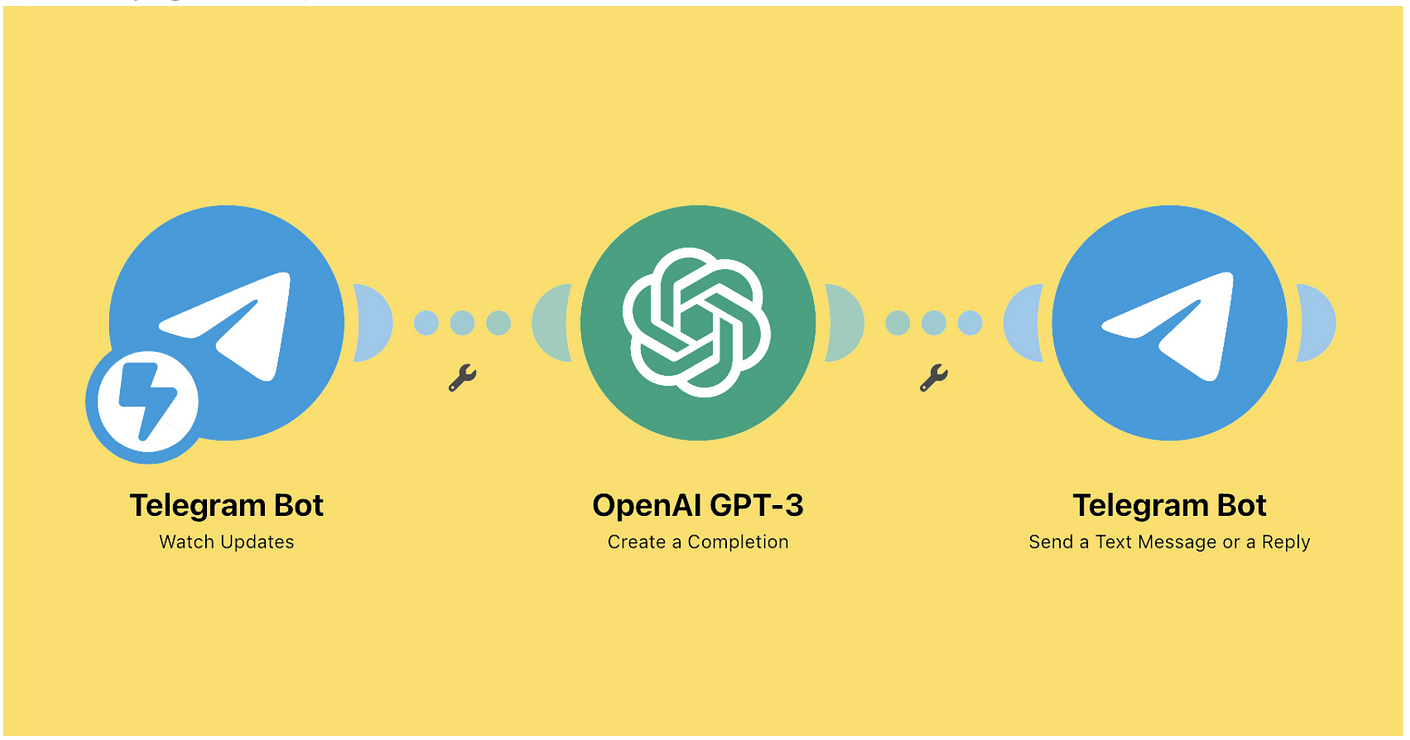






 Hi Community,
Hi Community,