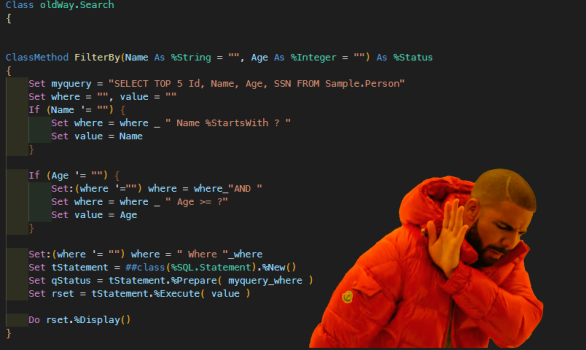
When creating custom Business Hosts, it's often necessary to add properties to the class for additional settings that will be used in the initialization or operation of the host. The property name itself isn't always very descriptive, so it's an advantage to have a custom caption display with the field.
In Caché, it was fairly straightforward:
TEST> Set^CacheMsgBut It involves a bit more effort in IRIS ...
In IRIS, the caption names of business host and production properties are stored in ^IRIS.



.png)

.png)


