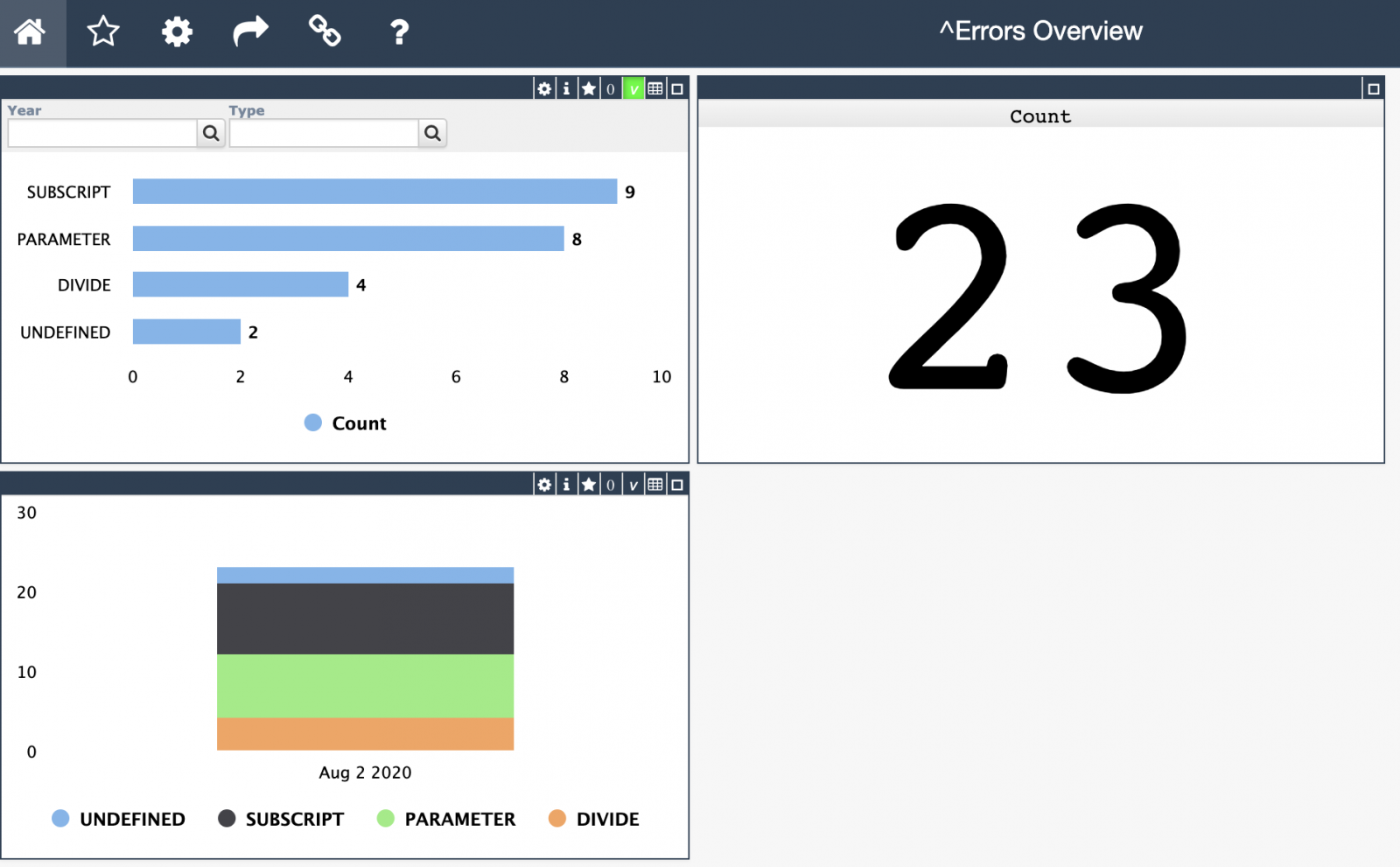
By date
By date.png)
The pandemic that struck the world in 2020 made everyone follow the news and the numbers that involve the COVID-19.
Why don’t you take that opportunity to create something simple and pleasant, to follow the number of vaccinations worldwide?
To face this challenge, I'm using the data provided by Our World in Data - Research and data to make progress against the world’s largest problems.
They have a dedicated repository on Github with the data of COVID-19, and I took the vaccination data to help me with my tracker.
 Open Exchange app
Open Exchange app




.png)