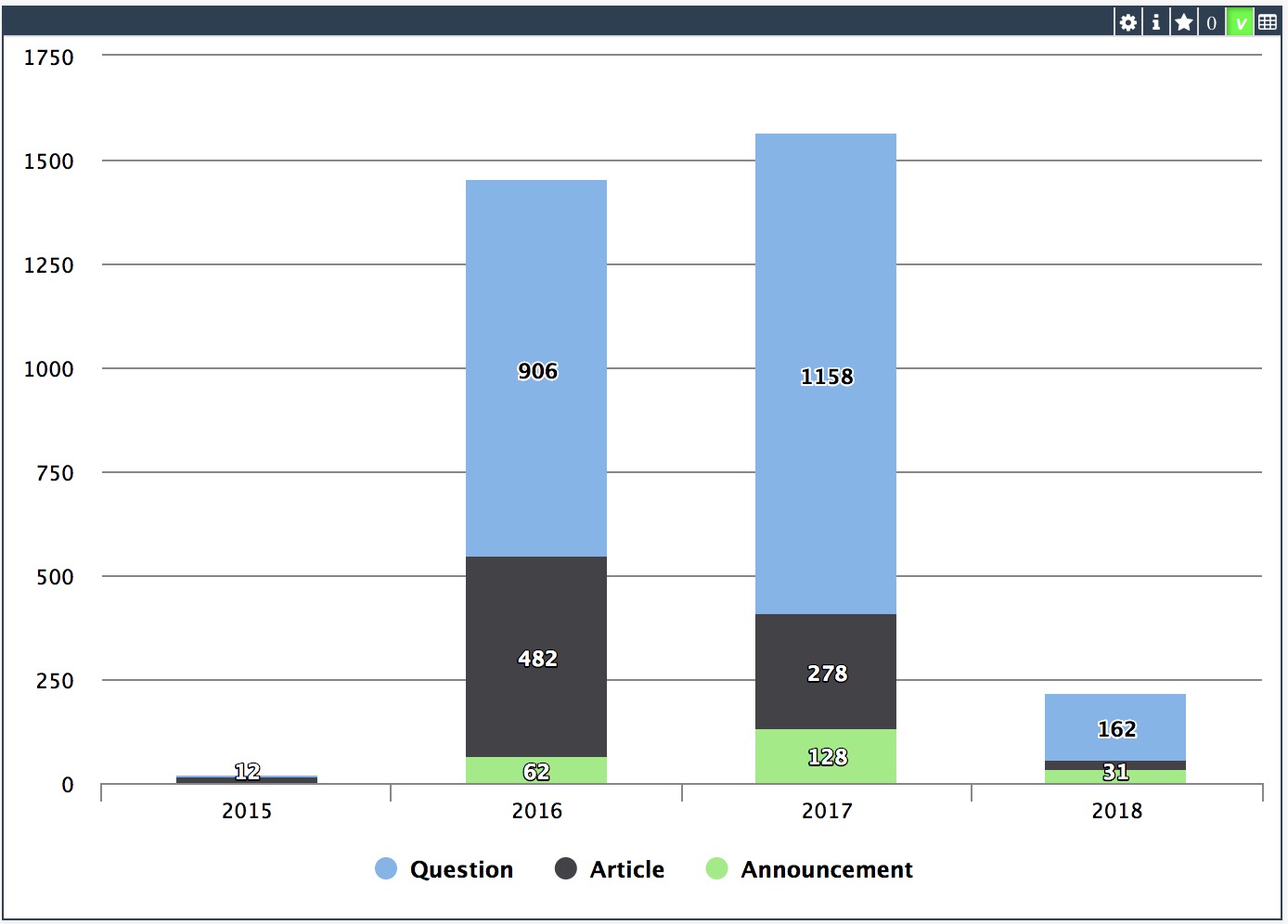
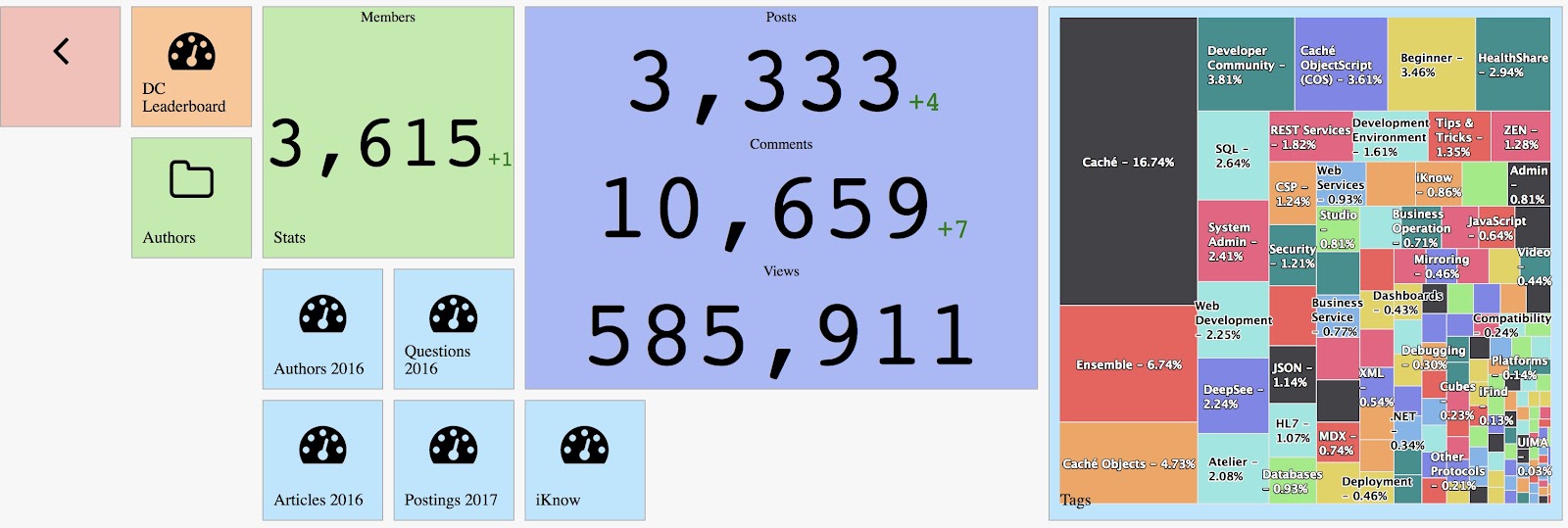
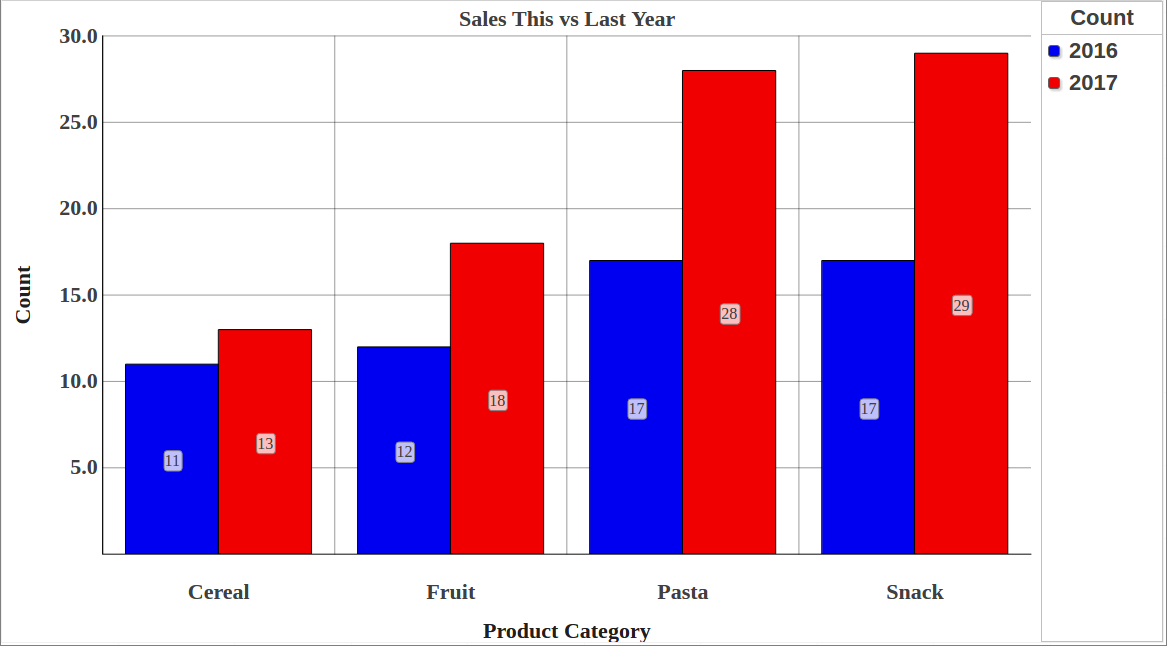
By update
By updateThe following post outlines an architectural design of intermediate complexity for DeepSee. As in the previous example, this implementation includes separate databases for storing the DeepSee cache, DeepSee implementation and settings. This post introduces two new databases: the first to store the globals needed for synchronization, the second to store fact tables and indices.