DeepSee: Databases, Namespaces, and Mappings - Part 3 of 5
The following post outlines an architectural design of intermediate complexity for DeepSee. As in the previous example, this implementation includes separate databases for storing the DeepSee cache, DeepSee implementation and settings. This post introduces two new databases: the first to store the globals needed for synchronization, the second to store fact tables and indices.

Example 2: More flexible design
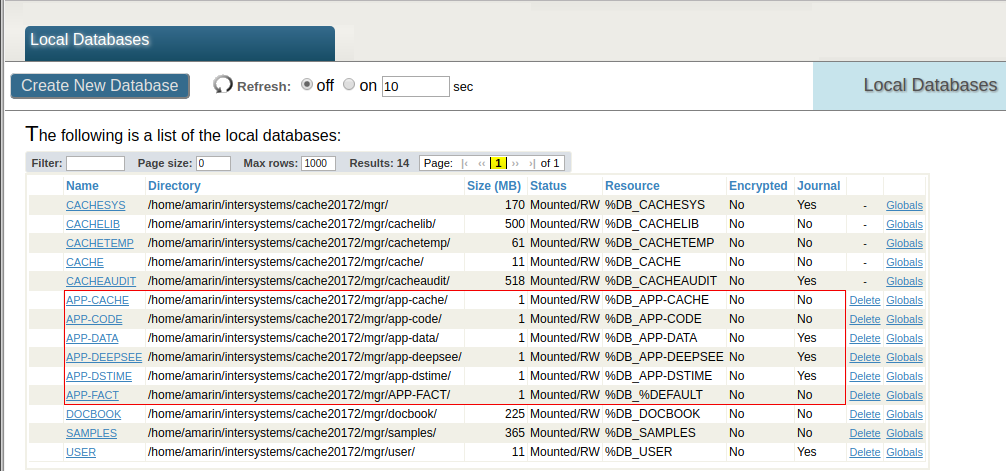
Databases
In addition to the APP-CACHE and APP-DEEPSEE databases in the previous example, we define the APP-DSTIME and the APP-FACT databases.
The APP-DSTIME database contains the DeepSee synchronization globals ^OBJ.DSTIME and ^DeepSee.Update. These globals are mirrored from a (journaled) database on the Production server. Note that the APP-DSTIME database must be Read-Write in caché versions using ^DeepSee.Update.
The APP-FACT database stores the fact tables and indices. The reason to split indices from fact tables is that indices can possibly be big in size. By defining APP-FACT it is possible to have more flexibility with journal settings or to define a non-default block size. Enabling journaling for the APP-FACT database is optional. The choice mainly depends on whether Analytics can stay unavailable while rebuilding cubes in case of a disruptive event. In this example journaling fact tables and indices is disabled, and the typical reason for this choice is that cubes are small in size, build relatively fast, and undergo frequent periodical rebuilds. Please read the note on the bottom for a more extensive discussion.
Global Mappings
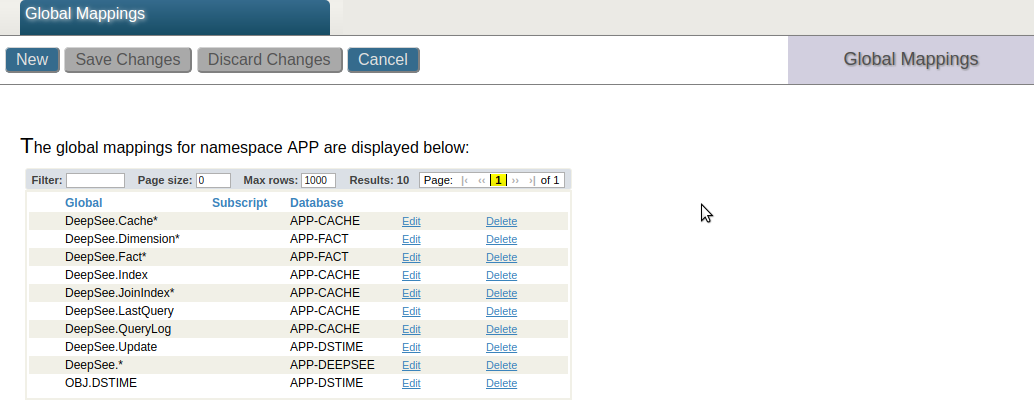
The following screenshot shows the mappings for the implementation example above.
The DeepSee synchronization globals ^OBJ.DSTIME and ^DeepSee.Update are mapped to the APP-DSTIME database. The globals ^DeepSee.LastQuery and ^DeepSee.QueryLog define a log for all executed MDX queries. In this example these globals are mapped to the APP-CACHE database together with the DeepSee cache. These mappings are optional.
The ^DeepSee.Fact* and ^DeepSee.Dimension* globals store the fact and dimension tables, whereas the ^DeepSee.Index global defines the DeepSee indices. These globals are mapped to the APP-FACT database.
Comments
As in the basic example the DeepSee cache is correctly stored in a dedicated database with journaling disabled. DeepSee implementation and settings are separately mapped to a journaled database to be able to restore the DeepSee implementation.
The globals supporting synchronization are mapped to APP-DSTIME and journaled on the Primary.
Mapping fact tables and indices to a dedicated database allows DeepSee implementation and settings to be stored in a dedicated journaled database (i.e. APP-DEEPSEE), which can be easily used to restore the DeepSee implementation.
In the third and last example we will redefine the mappings for the APP-FACT database and create a database for the DeepSee indices.
Note on journaling and building cubes
Users should be aware that building cubes deletes and recreates the cubes’ fact and index tables. This means that when journaling is enabled the SETs and KILLs of globals such as ^DeepSee.Fact*, ^DeepSee.Index are logged in journal files. As a result, rebuilding cubes might lead to a huge amount of entries in the journal files and possible problems with disk space.
It is recommended to map fact tables and indices to one or two separate databases.
For the Fact and Indices databases journaling is optional and depends on the business needs. It might preferable to disable journaling when cubes are relatively small and fast to build, or cubes are scheduled to rebuild periodically.
Enable journaling on this database when cubes are relatively big and it takes too long to rebuild them. The ideal case to keep journaling on is when cubes are in a stable state and only get periodically synchronized, but not built. One way to safely build cubes is to temporarily disable journaling for the Fact database.
Comments
Hi, Alessandro!
Thanks again for such valuable content on BI Architecture with DeepSee. Analytics server configuration gets more and more sophisticated with a lot of manual operations.
Do you plan to introduce a script which will convert a "usual" server to a "ready for DeepSee Analytics" server in a one-run? That would be fantastic!
I did not plan to introduce such a script though I actually do have scripts doing operations on databases, mappings, security, etc. It would not be too difficult to implement such a script. There is already something similar for Ensemble namespaces.
One problem however is that, as I hope it will be clear from my series, there is no universal solution for all user cases. In spite of this my opinion is that the solution of intermediate complexity outlined here would be the most likely to be adopted by most users.
Like this one?
Thanks, Oleg!
But it's not about to map DeepSee globals, though this is helpful. Do you want to provide more details on this repository? Why map and what are the globals?
For the Fact and Indices databases journaling is optional and depends on the business needs. It might preferable to disable journaling when cubes are relatively small and fast to build, or cubes are scheduled to rebuild periodically.
Enable journaling on this database when cubes are relatively big and it takes too long to rebuild them. The ideal case to keep journaling on is when cubes are in a stable state and only get periodically synchronized, but not built. One way to safely build cubes is to temporarily disable journaling for the Fact database.
One thing to keep in mind is that when DeepSee synchronizes a cube, each update/insertion of a fact (along with the associated updates/insertions to the DeepSee indices) is done inside of a transaction. This means that there will be journal activity on ^DeepSee.Fact and ^DeepSee.Index when synchronizing even if those globals are mapped to a database (such as APP-FACT, in this example) that does not have journaling enabled.
When DeepSee builds a cube, updates and insertions on the fact table and indices are not done inside of a transaction. A build should cause journal activity on ^DeepSee.Fact and ^DeepSee.Index if and only if those globals are mapped to a database for which journaling is enabled.