DeepSee: Databases, Namespaces, and Mappings - Part 2 of 5
The following post is a guide to implement a basic architecture for DeepSee. This implementation includes a database for the DeepSee cache and a database for the DeepSee implementation and settings.

Example 1: Basic architecture
Databases
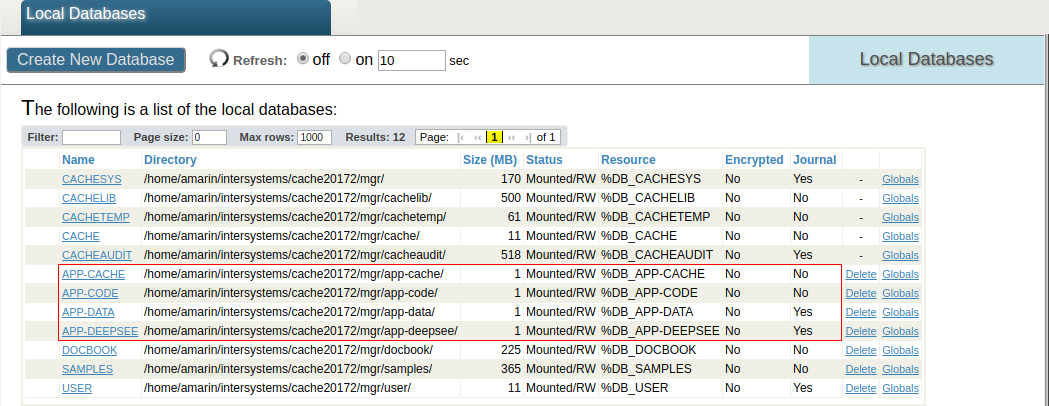
This configuration for the Analytics server includes the APP-CACHE and APP-DEEPSEE databases. A crucial setting for DeepSee to run smoothly is that the DeeSee cache should never be journaled. Doing so will slow down the performance of the DeepSee engine, in addition to causing hyper-journaling and possibly problems with disk space. For this reason the DeepSee cache is stored in APP-CACHE, a separate DeepSee Cache database with journaling disabled.
APP-DEEPSEE is a DeepSee Implementation and Settings database containing the ^DeepSee.* globals. These globals define most of the DeepSee implementation such as cube definitions and settings, Cube Manager, user settings, and more. Note in the screenshot below that all databases are Read-Write and that it was decided to enable Journaling only on the APP-DEEPSEE. It is recommended to journal this database since it contains all definitions, settings and user data.
Global Mappings
The following screenshot shows the mappings for this basic architectural implementation on the APP namespace. The ^DeepSee.Cache.* and ^DeepSee.JoinIndex map the DeepSee cache to the APP-CACHE database. The ^DeepSee.* globals maps, among others, DeepSee implementation and settings to the APP-DEEPSEE database.

Comments
In this example for a basic architecture the DeepSee cache is stored in a dedicated database. This allows journaling to be disabled on the ^DeepSee.Cache* and ^DeepSee.JoinIndex globals.
Journaling of the APP-DEEPSEE database makes it possible to restore the DeepSee implementation (cubes, subject areas, DeepSee items, user settings, etc) in case of a disruptive event.
The configuration outlined in this example has some flaws. First, globals supporting synchronization are not taken care of. Second, the APP-DEEPSEE database also contains fact tables, indices, and other DeepSee globals. As a result, APP-DEEPSEE could become big in size making it not practical to journal and restore. This configuration can be considered acceptable if, for example, cubes do not contain a large amount of data.
In the next example of this series we will see how to map cube synchronization globals, fact tables and indices to separate databases.